What is operability, how does it promote resilience, and how does building operability into your applications drive Continuous Delivery adoption?
TL;DR:
- Operability refers to the ability to safely and reliably operate a production application.
- Increasing service resilience depends on adding sources of adaptive capacity that increase operability.
- Continuous Delivery depends on increasing service resilience.
Introduction
The origins of the 20th century, pre-Internet IT As A Cost Centre organisational model can be traced to the suzerainty of cost accounting, and the COBIT management and governance framework. COBIT has recommended sequential Plan-Build-Run phases to maximise resource efficiency since its launch in 1996. The Plan phase is business analysis and product development, Build is product engineering, and Run is product support. The justification for this is the high compute costs and high transaction costs for a release in the 1990s.

With IT As A Cost Centre, Plan happens in a Product department, and Build and Run happens in an IT department. IT will have separate Delivery and Operations groups, with competing goals:
- Delivery will be responsible for building features
- Operations will be responsible for running applications
Delivery and Operations will consist of functionally-oriented teams of specialists. Delivery will have multiple development teams. Operations will have Database, Network, and Server teams to administer resources, a Service Transition team to check operational readiness prior to launch, and one or more Production Support teams to respond to live incidents.
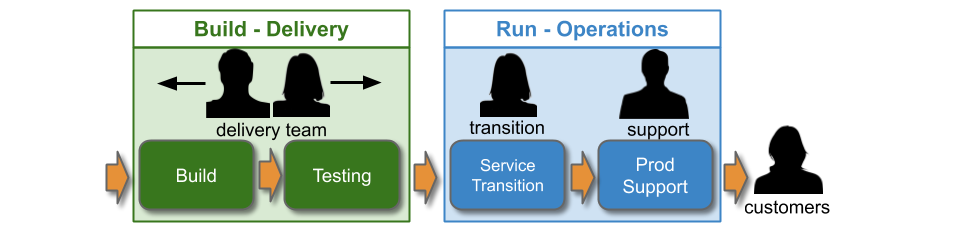
Siloisation causes Discontinuous Delivery
In High Velocity Edge, Dr. Steven Spear warns over-specialisation leads to siloisation, and causes functional areas to “operate more like sovereign states”. Delivery and Operations teams with orthogonal priorities will create multiple handoffs in a technology value stream. A handoff means waiting in a queue for a downstream team to complete a task, and that task could inadvertently produce more upstream work.
Furthermore, the fundamentally opposed incentives, nomenclature, and risk appetites within Delivery and Operations teams will cause a pathological culture to emerge over time. This is defined by Ron Westrum in A Typology of Organisational Cultures as a culture of power-oriented interactions, with low cooperation and neglected responsibilities.
Plan-Build-Run was not designed for fast customer feedback and iterative product development. The goal of Continuous Delivery is to achieve a deployment throughput that satisfies product demand. Disparate Delivery and Operations teams will inject delays and rework into a technology value stream such that lead times are disproportionately inflated. If product demand dictates a throughput target of weekly deployments or more, Discontinuous Delivery is inevitable.
Robustness breeds inoperability
Most IT cost centres try to achieve reliability by Optimising For Robustness, which means prioritising a higher Mean Time Between Failures (MTBF) over a lower Mean Time To Repair (MTTR). This is based on the idea a production environment is a complicated system, in which homogeneous application processes have predictable, repeatable interactions, and failures are preventable.
Reliability is dependent on operability, which can be defined as the ease of safely operating a production system. Optimising For Robustness produces an underinvestment in operability, due to the following:
- A Diffusion Of Responsibility between Delivery and Operations. When Operations teams are accountable for operational readiness and incident response, Delivery teams have little reason to work on operability
- A Normalisation of Deviation within Delivery and Operations. When failures are tolerated as rare and avoidable, Delivery and Operations teams will pursue cost savings rather than an ability to degrade on failure
That underinvestment in operability will result in Delivery and Operations teams creating brittle, inoperable production systems.
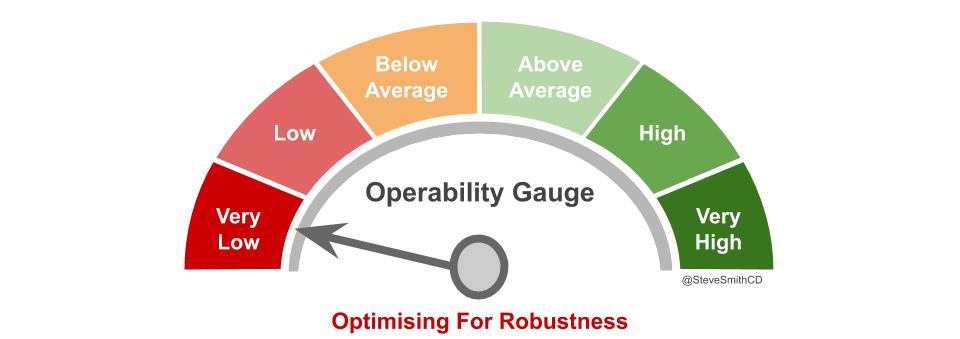
Symptoms of brittleness will include:
- Inadequate telemetry – an inability to detect abnormal conditions
- Fragile architecture – an inability to limit blast radius on failure
- Operator burnout – an inability to perform heroics on demand
- Blame games – an inability to learn from experience
This is ill-advised, as failures are entirely unavoidable. A production environment is actually a complex system, in which heterogeneous application processes have unpredictable, unrepeatable interactions, and failures are inevitable. As Richard Cook explains in How Complex Systems Fail “the complexity of these systems makes it impossible for them to run without multiple flaws“. A production environment is perpetually in a state of near-failure.
A failure occurs when multiple flaws unexpectedly coalesce and impede a business function, and the costs can be steep for a brittle, inoperable application. Inadequate telemetry widens the sunk cost duration from failure start to detection. A fragile architecture expands the opportunity cost duration from detection until resolution, and the overall cost per unit time. Operator burnout increases all costs involved, and blame games allow similar failures to occur in the future.
Resilience needs operability
Optimising For Resilience is a more effective reliability strategy. This means prioritising a lower MTTR over a higher MTBF. The ability to quickly adapt to failures is more important than fewer failures, although some failure classes should never occur and some safety-critical systems should never fail.
Resilience can be thought of as graceful extensibility. In The Theory of Graceful Extensibility, David Woods defines it as “a blend of graceful degradation and software extensibility”. A complex system with high graceful extensibility will continue to function, whereas a brittle system would collapse.
Graceful extensibility is derived from the capacity for adaptation in a system. Adaptive capacity can be created when work is effectively managed to rapidly reveal new problems, problems are quickly solved and produce new knowledge, and new local knowledge is shared throughout an organisation. These can be achieved by improving the operability of a system via:
- An adaptive architecture
- Incremental deployments
- Automated provisioning
- Ubiquitous telemetry
- Chaos Engineering
- You Build It You Run It
- Post-incident reviews
Investing in operability creates a production environment in which applications can gracefully extend on failure. Ubiquitous telemetry will minimise sunk cost duration, an adaptive architecture will decrease opportunity cost duration, operator health will aid all aspects of failure resolution, and post-incident reviews will produce shareable knowledge for other operators. The result will be what Ron Westrum describes as a generative culture of performance-oriented interactions, high cooperation, and shared risks.
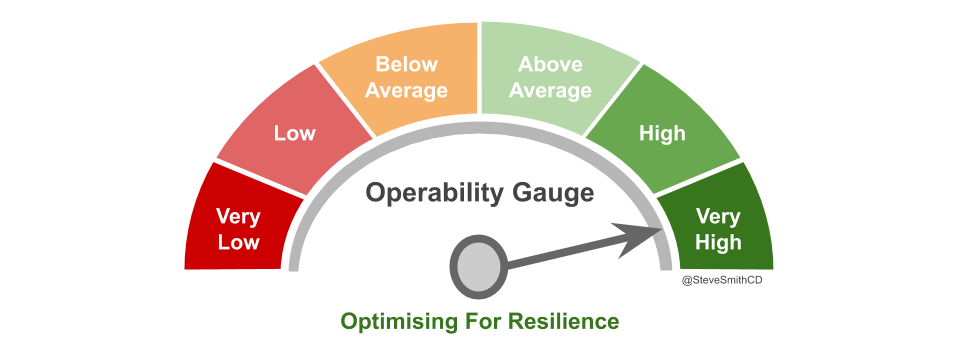
Dr. W. Edwards Deming said in Out Of The Crisis that “you cannot inspect quality into a product”. The same is true of operability. You cannot inspect operability into a product. Building operability in from the outset will remove handoffs, queues, and coordination costs between Delivery and Operations teams in a technology value stream. This will eliminate delays and rework, and allow Continuous Delivery to be achieved.
Acknowledgements
Thanks to Thierry de Pauw for the review