End-To-End Testing is used by many organisations, but relying on extensive end-to-end tests is fundamentally incompatible with Continuous Delivery. Why is End-To-End Testing so commonplace, and yet so ineffective? How is Continuous Testing a lower cost, higher value testing strategy?
NOTE: The latter half of this article was superseded by the talk “End-To-End Testing Considered Harmful” in September 2016
Introduction
“Good testing involves balancing the need to mitigate risk against the risk of trying to gather too much information” Jerry Weinberg
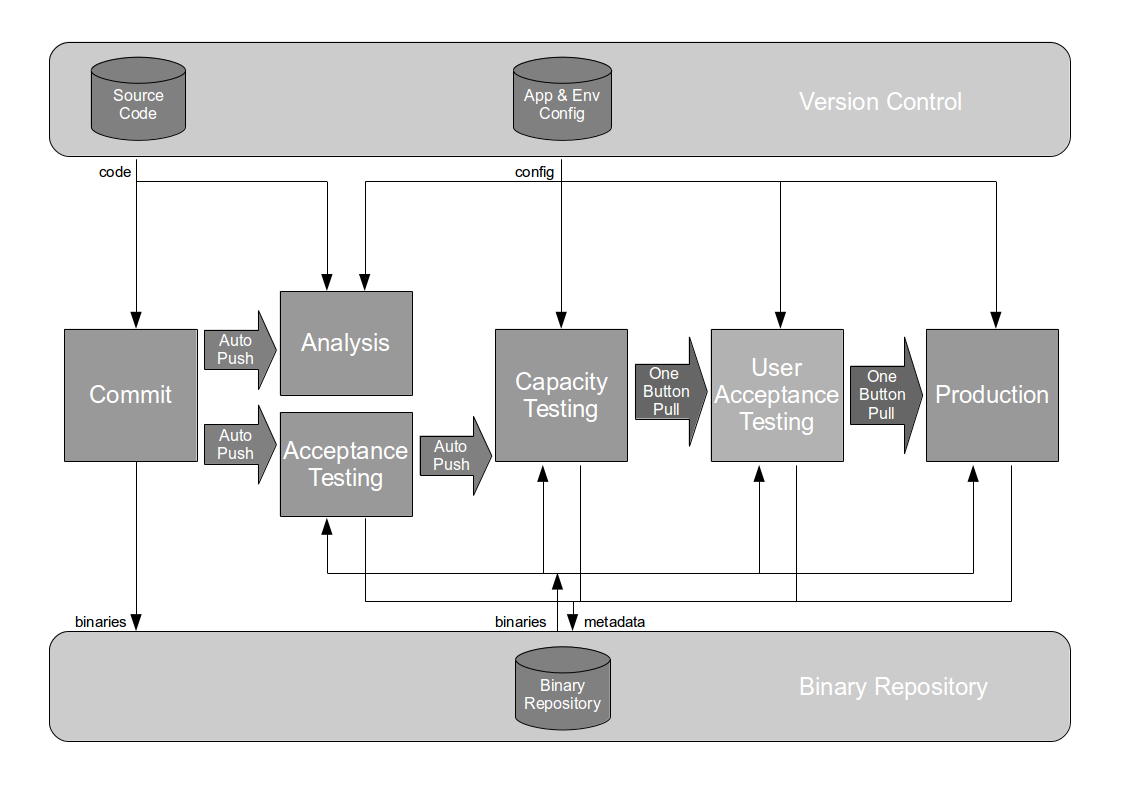
Continuous Delivery is a set of holistic principles and practices to reduce time to market, and it is predicated upon rapid and reliable test feedback. Continuous Delivery mandates any change to code, configuration, data, or infrastructure must pass a series of automated and exploratory tests in a Deployment Pipeline to evaluate production readiness, so test execution times must be low and test results must be deterministic if an organisation is to achieve shorter lead times.
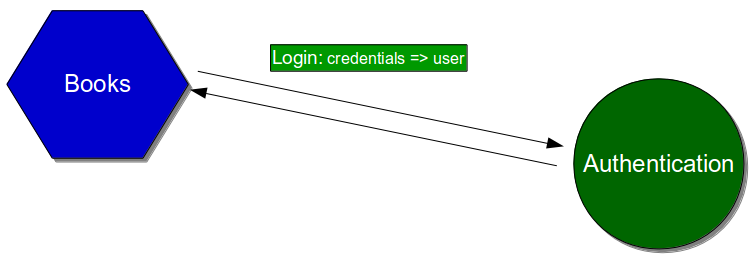
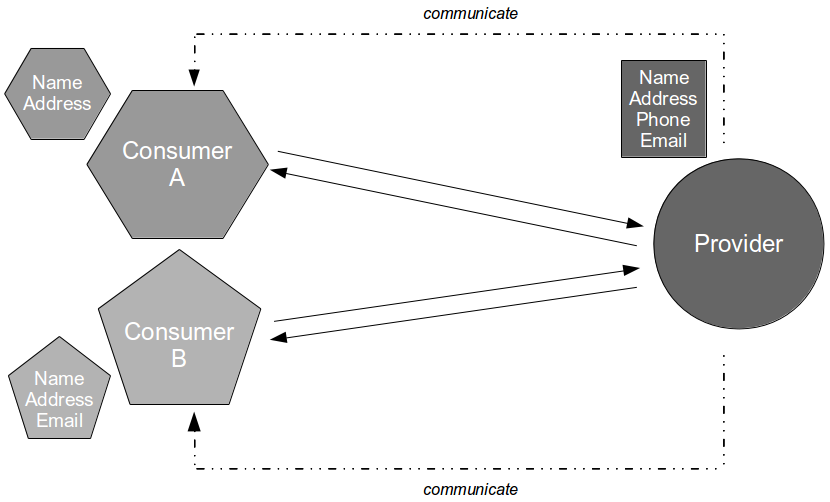
For example, consider a Company Accounts service in which year end payments are submitted to a downstream Payments service.
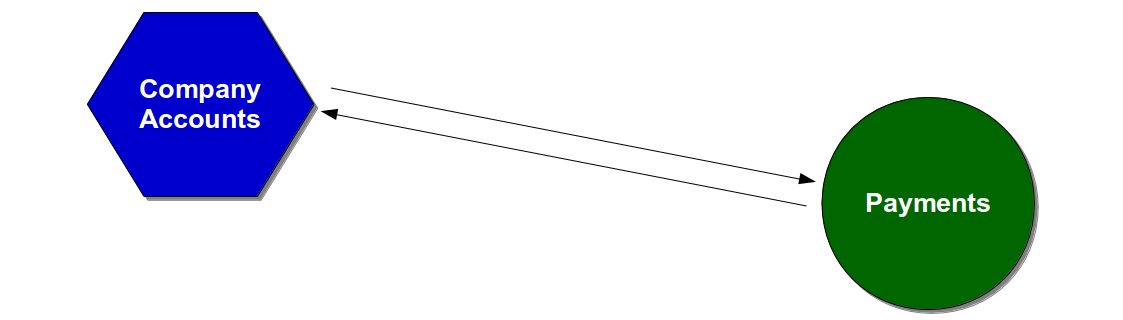
The behaviour of the Company Accounts service could be checked at build time by the following types of automated test:
- Unit tests check intent against implementation by verifying a discrete unit of code
- Acceptance tests check implementation against requirements by verifying a functional slice of the system
- End-to-end tests check implementation against requirements by verifying a functional slice of the system, including unowned dependent services
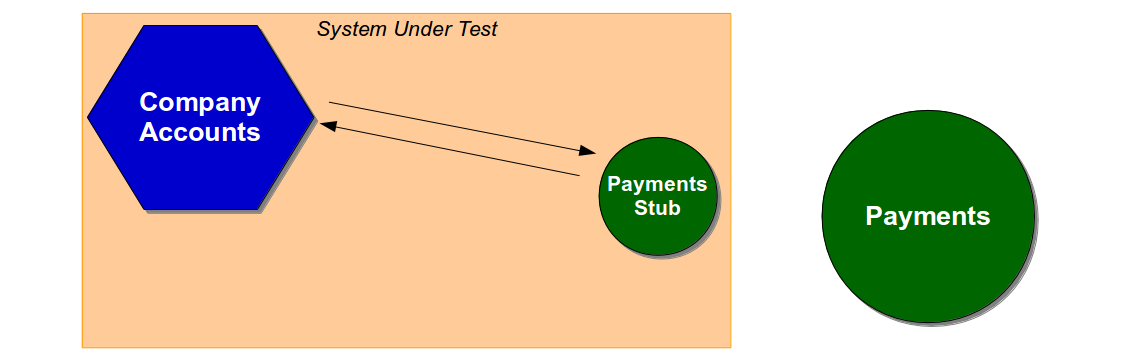
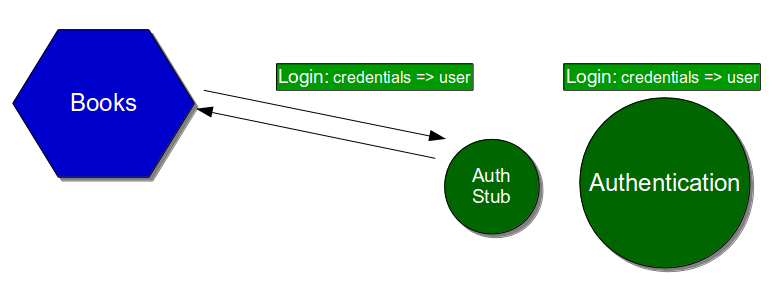
While unit tests and acceptance tests vary in terms of purpose and scope, acceptance tests and end-to-end tests vary solely in scope. Acceptance tests exclude unowned dependent services, so an acceptance test of a Company Accounts user journey would use a System Under Test comprised of the latest Company Accounts code and a Payments Stub.
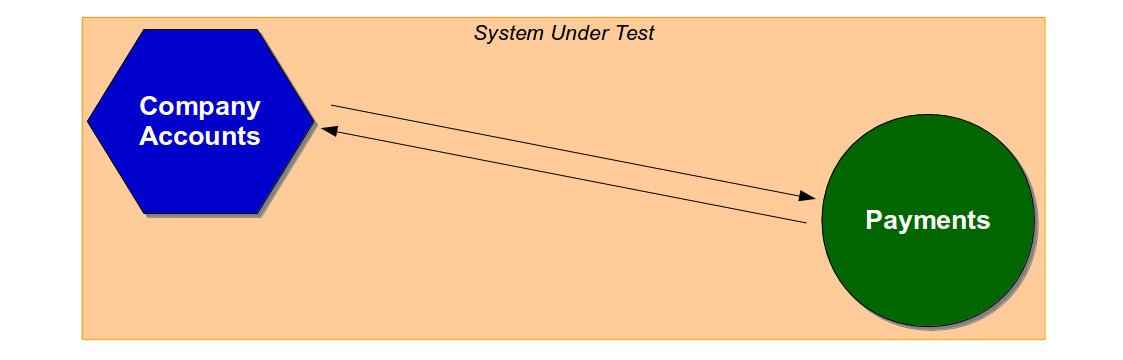
End-to-end tests include unowned dependent services, so an end-to-end test of a Company Accounts user journey would use a System Under Test comprised of the latest Company Accounts code and a running version of Payments.
If a testing strategy is to be compatible with Continuous Delivery it must have an appropriate ratio of unit tests, acceptance tests, and end-to-end tests that balances the need for information discovery against the need for fast, deterministic feedback. If testing does not yield new information then defects will go undetected, but if testing takes too long delivery will be slow and opportunity costs will be incurred.
The folly of End-To-End Testing
“Any advantage you gain by talking to the real system is overwhelmed by the need to stamp out non-determinism” Martin Fowler
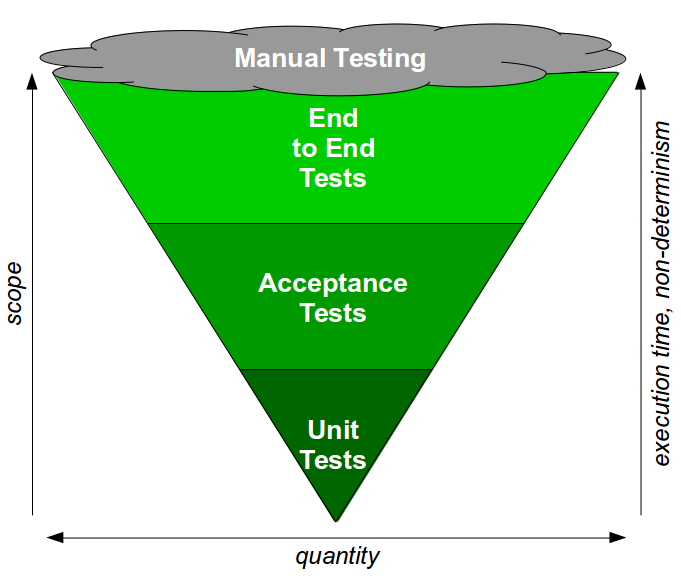
End-To-End Testing is a testing practice in which a large number of automated end-to-end tests and manual regression tests are used at build time with a small number of automated unit and acceptance tests. The End-To-End Testing test ratio can be visualised as a Test Ice Cream Cone.
End-To-End Testing often seems attractive due to the perceived benefits of an end-to-end test:
- An end-to-end test maximises its System Under Test, suggesting a high degree of test coverage
- An end-to-end test uses the system itself as a test client, suggesting a low investment in test infrastructure
Given the above it is perhaps understandable why so many organisations adopt End-To-End Testing – as observed by Don Reinertsen, “this combination of low investment and high validity creates the illusion that system tests are more economical“. However, the End-To-End Testing value proposition is fatally flawed as both assumptions are incorrect:
- The idea that testing a whole system will simultaneously test its constituent parts is a Decomposition Fallacy. Checking implementation against requirements is not the same as checking intent against implementation, which means an end-to-end test will check the interactions between code pathways but not the behaviours within those pathways
- The idea that testing a whole system will be cheaper than testing its constituent parts is a Cheap Investment Fallacy. Test execution time and non-determinism are directly proportional to System Under Test scope, which means an end-to-end test will be slow and prone to non-determinism
Martin Fowler has warned before that “non-deterministic tests can completely destroy the value of an automated regression suite“, and Stephen Covey’s Circles of Control, Influence, and Concern highlights how the multiple actors in an end-to-end test make non-determinism difficult to identify and resolve. If different teams in the same Companies R Us organisation owned the Company Accounts and Payments services the Company Accounts team would control its own service in an end-to-end test, but would only be able to influence the second-party Payments service.
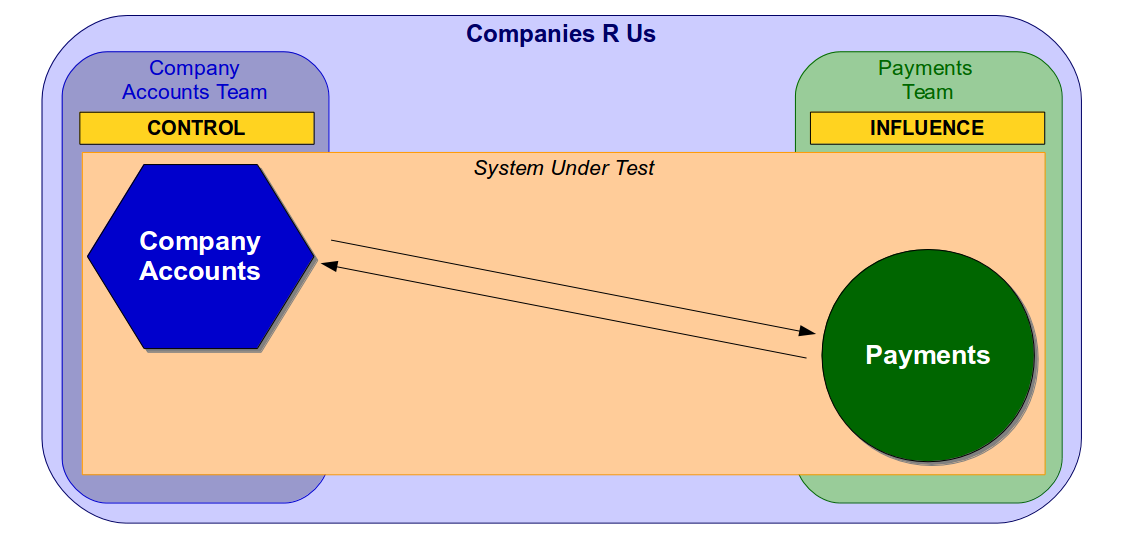
The lead time to improve an end-to-end test depends on where the change is located in the System Under Test, so the Company Accounts team could analyse and implement a change in the Company Accounts service in a relatively short lead time. However, the lead time for a change to the Payments service would be constrained by the extent to which the Company Accounts team could persuade the Payments team to take action.
Alternatively, if a separate Payments R Us organisation owned the Payments service it would be a third-party service and merely a concern of the Company Accounts team.
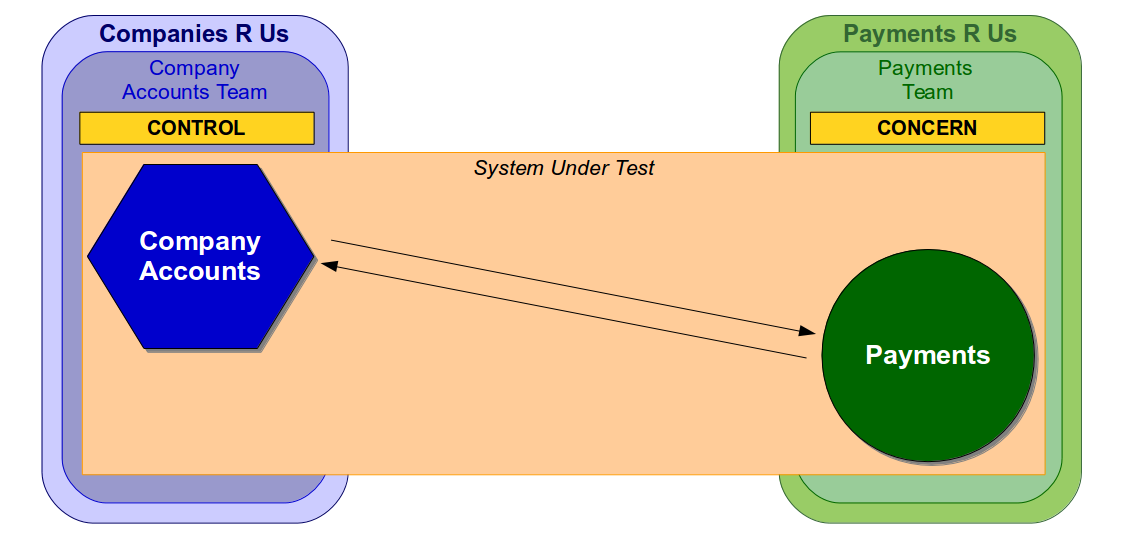
In this situation a change to the Payments service would take much longer as the Company Accounts team would have zero control or influence over Payments R Us. Furthermore, the Payments service could be arbitrarily updated with little or no warning, which would increase non-determinism in Company Accounts end-to-end tests and make it impossible to establish a predictable test baseline.
A reliance upon End-To-End Testing is often a symptom of long-term underinvestment producing a fragile system that is resistant to change, has long lead times, and optimised for Mean Time Between Failures instead of Mean Time To Repair. Customer experience and operational performance cannot be accurately predicted in a fragile system due to variations caused by external circumstances, and focussing on failure probability instead of failure cost creates an exposure to extremely low probability, extremely high cost events known as Black Swans such as Knights Capital losing $440 million in 45 minutes. For example, if the Payments data centre suffered a catastrophic outage then all customer payments made by the Company Accounts service would fail.
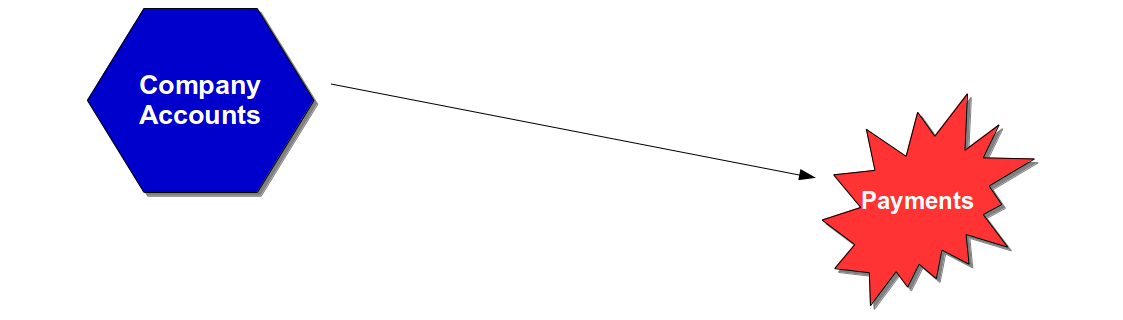
An unavailable Payments service would leave customers of the Company Accounts service with their money locked up in in-flight payments, and a slow restoration of service would encourage dissatisfied customers to take their business elsewhere. If any in-flight payments were lost and it became public knowledge it could trigger an enormous loss of customer confidence.
End-To-End Testing is an uncomprehensive, high cost testing strategy. An end-to-end test will not check behaviours, will take time to execute, and will intermittently fail, so a test suite largely composed of end-to-end tests will result in poor test coverage, slow execution times, and non-deterministic results. Defects will go undetected, feedback will be slow and unreliable, maintenance costs will escalate, and as a result testers will be forced to rely on their own manual end-to-end regression tests. End-To-End Testing cannot produce short lead times, and it is utterly incompatible with Continuous Delivery.
The value of Continuous Testing
“Cease dependence on inspection to achieve quality. Eliminate the need for inspection on a mass basis by building quality into the product in the first place” Dr W Edwards Deming
Continuous Delivery advocates Continuous Testing – a testing strategy in which a large number of automated unit and acceptance tests are complemented by a small number of automated end-to-end tests and focussed exploratory testing. The Continuous Testing test ratio can be visualised as a Test Pyramid, which might be considered the antithesis of the Test Ice Cream Cone.
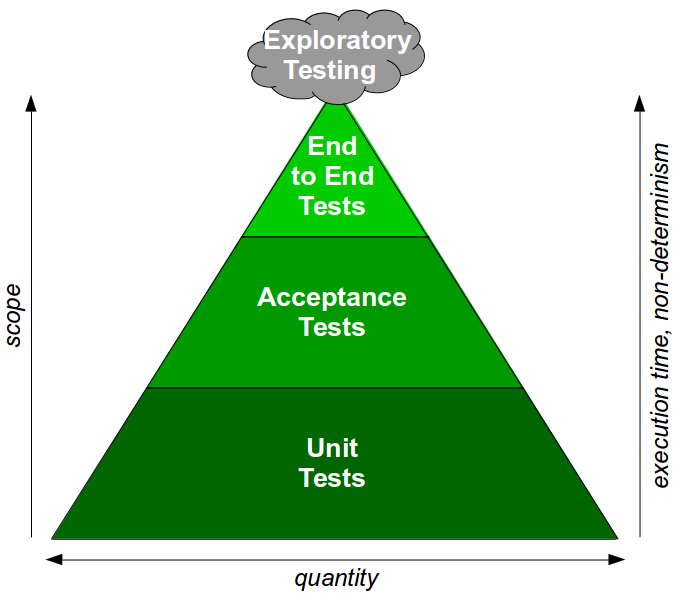
Continuous Testing is aligned with Test-Driven Development and Acceptance Test Driven Development, and by advocating cross-functional testing as part of a shared commitment to quality it embodies the Continuous Delivery principle of Build Quality In. However, Continuous Testing can seem daunting due to the perceived drawbacks of unit tests and acceptance tests:
- A unit test or acceptance test minimises its System Under Test, suggesting a low degree of test coverage
- A unit test or acceptance test uses its own test client, suggesting a high investment in test infrastructure
While the End-To-End Testing value proposition is invalidated by incorrect assumptions of high test coverage and low maintenance costs, the inverse is true of Continuous Testing – its value proposition is validated by incorrect assumptions of low test coverage and high maintenance costs:
- A unit test will check intent against implementation and an acceptance test will check implementation against requirements, which means both the behaviour of a code pathway and its interactions with other pathways can be checked
- A unit test will restrict its System Under Test scope to a single pathway and an acceptance test will restrict itself to a single service, which means both can have the shortest possible execution time and deterministic results
A non-deterministic acceptance test can be resolved in a much shorter period of time than an end-to-end test as the System Under Test has a single owner. If Companies R Us owned the Company Accounts service and Payments R Us owned the Payments service a Company Accounts acceptance test would only use services controlled by the Company Accounts team.
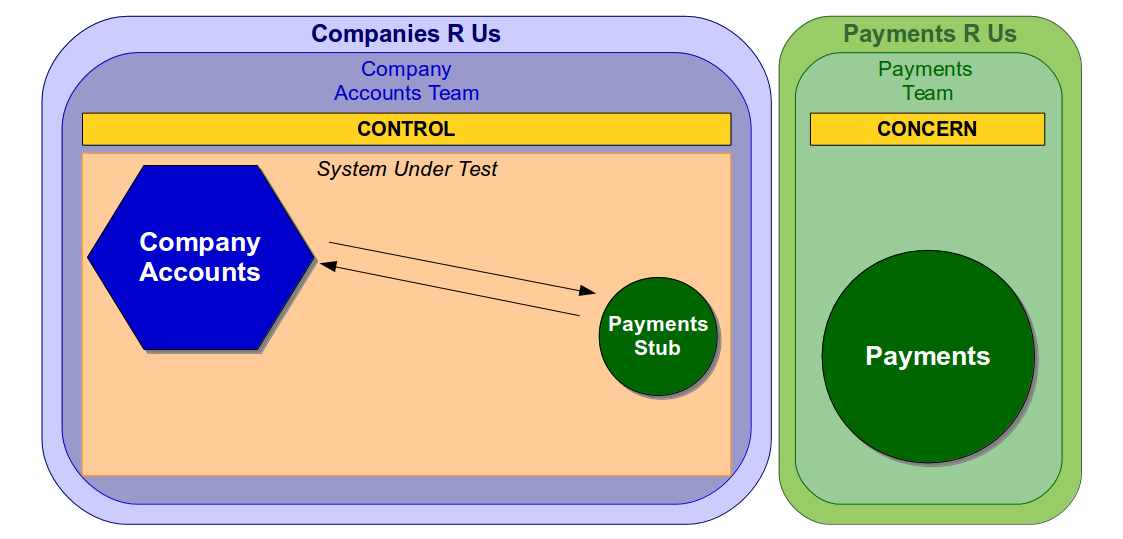
If the Company Accounts team attempted to identify and resolve non-determinism in an acceptance test they would be able to make the necessary changes in a short period of time. There would also be no danger of unexpected changes to the Payments service impeding an acceptance test of the latest Company Accounts code, which would allow a predictable test baseline to be established.
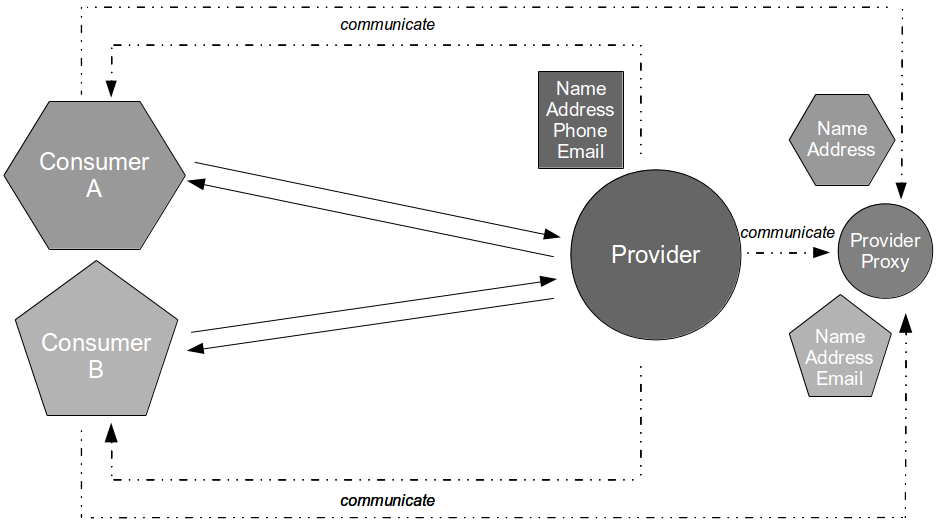
End-to-end tests are a part of Continuous Testing, not least because the idea that testing the constituent parts of a system will simultaneously test the whole system is a Composition Fallacy. A small number of automated end-to-end tests should be used to validate core user journeys, but not at build time when unowned dependent services are unreliable and unrepresentative. The end-to-end tests should be used for release time smoke testing and runtime production monitoring, with synthetic transactions used to simulate user activity. This approach will increase confidence in production releases and should be combined with real-time monitoring of business and operational metrics to accelerate feedback loops and understand user behaviours.
In Continuous Delivery there is a recognition that optimising for Mean Time To Repair is more valuable than optimising for Mean Time Between Failures as it enables an organisation to minimise the impact of production defects, and it is more easily achievable. Defect cost can be controlled as Little’s Law guarantees smaller production releases will shorten lead times to defect resolution, and Continuous Testing provides the necessary infrastructure to shrink feedback loops for smaller releases. The combination of Continuous Testing and Continuous Delivery practices such as Blue Green Releases and Canary Releases empower an organisation to create a robust system capable of neutralising unanticipated events, and advanced practices such as Dark Launching and Chaos Engineering can lead to antifragile systems that seek to benefit from Black Swans. For example, if Chaos Engineering surfaced concerns about the Payments service the Company Accounts team might Dark Launch its Payments Stub into production and use it in the unlikely event of a Payments data centre outage.
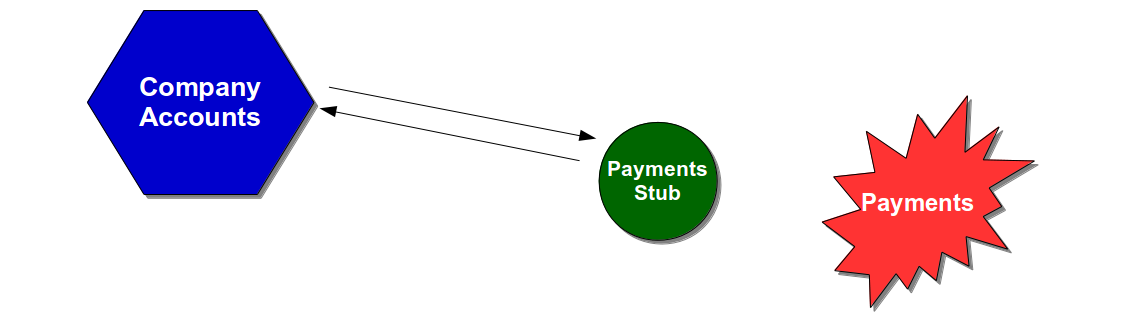
While the Payments data centre was offline the Company Accounts service would gracefully degrade to collecting customer payments in the Payments Stub until the Payments service was operational again. Customers would be unaffected by the production incident, and if competitors to the Company Accounts service were also dependent on the same third-party Payments service that would constitute a strategic advantage in the marketplace. Redundant operational capabilities might seem wasteful, but Continuous Testing promotes operational excellence and as Nassim Nicholas Taleb has remarked “something unusual happens – usually“.
Continuous Testing can be a comprehensive and low cost testing strategy. According to Dave Farley and Jez Humble “building quality in means writing automated tests at multiple levels“, and a test suite largely comprised of unit and acceptance tests will contain meticulously tested scenarios with a high degree of test coverage, low execution times, and predictable test results. This means end-to-end tests can be reserved for smoke testing and production monitoring, and testers can be freed up from manual regression testing for higher value activities such as exploratory testing. This will result in fewer production defects, fast and reliable feedback, shorter lead times to market, and opportunities for revenue growth.
From end-to-end testing to continuous testing
“Push tests as low as they can go for the highest return in investment and quickest feedback” Janet Gregory and Lisa Crispin
Moving from End-To-End Testing to Continuous Testing is a long-term investment, and should be based on the notion that an end-to-end test can be pushed down the Test Pyramid by decoupling its concerns as follows:
- Connectivity – can services connect to one another
- Conversation – can services talk with one another
- Conduct – can services behave with one another
Assume the Company Accounts service depends on a Pay endpoint on the Payments service, which accepts a company id and payment amount before returning a confirmation code and days until payment. The Company Accounts service sends the id and amount request fields and silently depends on the code response field.
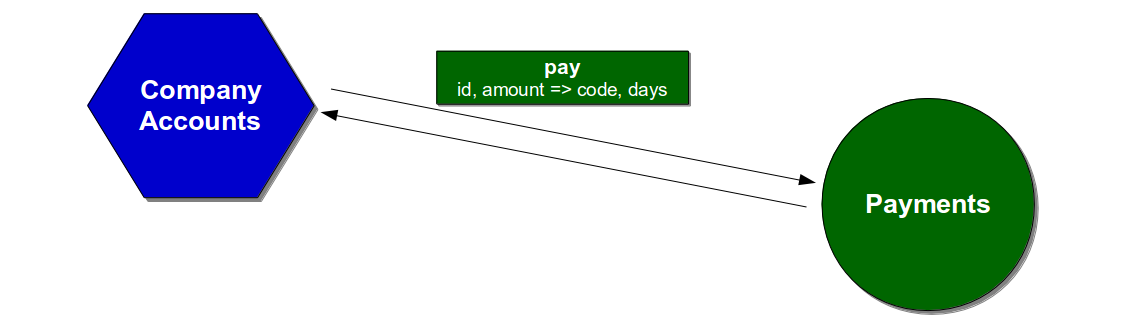
The connection between the services could be unit tested using Test Doubles, which would allow the Company Accounts service to test its reaction to different Payments behaviours. Company Accounts unit tests would replace the Payments connector with a Mock or Stub connector to ensure scenarios such as an unexpected Pay timeout were appropriately handled.
The conversation between the services could be unit tested using Consumer Driven Contracts, which would enable the Company Accounts service to have its interactions continually verified by the Payments service. The Payments service would issue a Provider Contract describing its Pay API at build time, the Company Accounts service would return a Consumer Contract describing its usage, and the Payments service would create a Consumer Driven Contract to be checked during every build.
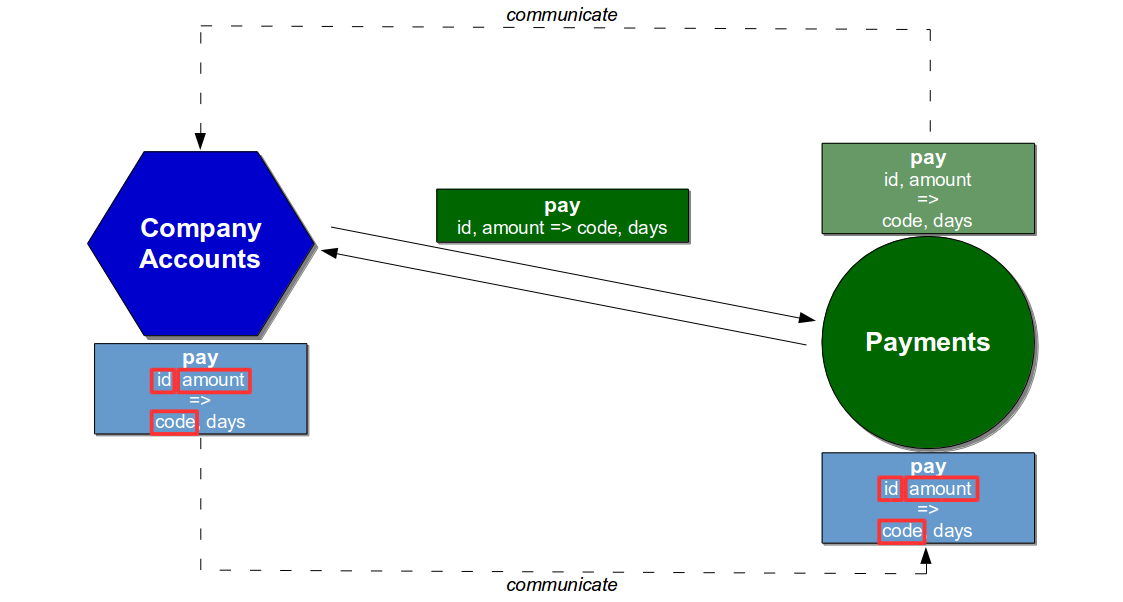
With the Company Accounts service not using the days response field it would be excluded from the Consumer Contract and Consumer Driven Contract, so a build of the Payments service that removed days or added a new comments response field would be successful. If the code response field was removed the Consumer Driven Contract would fail, and the Payments team would have to collaborate with the Company Accounts team on a different approach.
The conduct of the services could be unit tested using API Examples, which would permit the Company Accounts service to check for behavioural changes in new releases of the Payments service. Each release of the Payments service would be accompanied by a sibling artifact containing example API requests and responses for the Pay endpoint, which would be plugged into Company Accounts unit tests to act as representative test data and warn of behavioural changes.
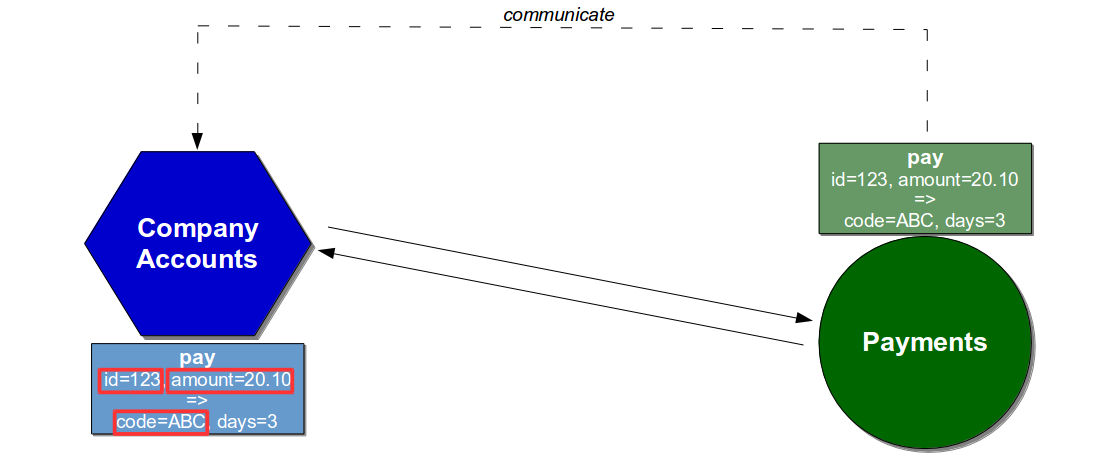
If a new version of the Payments service changed the format of the code response field from alphanumeric to numeric it would cause the Company Accounts service to fail at build time, indicating a behavioural change within the Payments service and prompting a conversation between the teams.
Conclusion
“Not only won’t system testing catch all the bugs, but it will take longer and cost more – more than you save by skipping effective acceptance testing” – Jerry Weinberg
End-To-End Testing seems attractive to organisations due to its promise of high test coverage and low maintenance costs, but the extensive use of automated end-to-end tests and manual regression tests can only produce a fragile system with slow, unreliable test feedback that inflates lead times and is incompatible with Continuous Delivery. Continuous Testing requires an upfront and ongoing investment in test automation, but a comprehensive suite of automated unit tests and acceptance tests will ensure fast, deterministic test feedback that reduces production defects, shortens lead times, and encourages the Continuous Delivery of robust or antifragile systems.
Further Reading
- Continuous Delivery by Dave Farley and Jez Humble
- Principles Of Product Development Flow by Don Reinertsen
- 7 Habits of Highly Effective People by Stephen Covey
- Test Pyramid by Martin Fowler
- Test Ice Cream Cone by Alister Scott
- Integrated Tests Are A Scam by JB Rainsberger
- Agile Testing and More Agile Testing by Janet Gregory and Lisa Crispin
- Perfect Software and Other Illusions by Jerry Weinberg
- Release Testing Is Risk Management Theatre by Steve Smith
- The Art Of Agile Development by James Shore and Shane Warden
- Making End-To-End Tests Work by Adrian Sutton
- Just Say No To More End-To-End Tests by Mike Wacker
- Antifragile by Nassim Nicholas Taleb
- On Antifragility In Systems And Organisational Architecture by Jez Humble
Acknowledgements
Thanks to Amy Phillips, Beccy Stafford, Charles Kubicek, and Chris O’Dell for their early feedback on this article.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Recent Comments