How should you design a deployment pipeline? Short and wide, long and thin, or something else? Can you use a Theory Of Constraints lens to explain why pipeline flexibility is more important than any particular pipeline design?
TL;DR:
- Past advice from the Continuous Delivery community to favour short and wide deployment pipelines over long and thin pipelines was flawed
- Parallelising activities between code commit and production in a short and wide deployment pipeline is unlikely to achieve a target lead time
- Flexible pipelines allow for experimentation until a Goldilocks deployment pipeline can be found, which makes Continuous Delivery easier to implement
Introduction
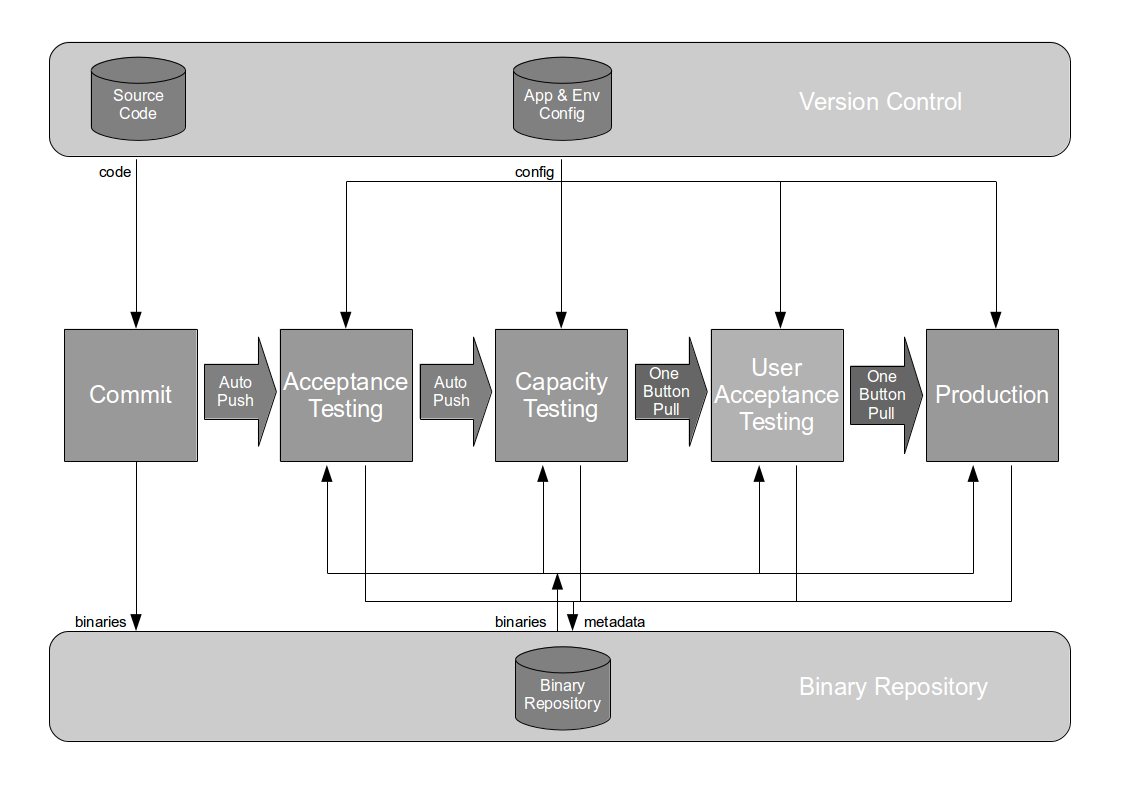
The Deployment Pipeline pattern is at the heart of Continuous Delivery. A deployment pipeline is a pull-based automated toolchain, used from code commit to production. The design of a deployment pipeline should be aligned with Conway’s Law, and a model of the underlying technology value stream. In other words, it should encompass the build, testing, and operational activities required to launch new product ideas to customers. The exact tools used are of little consequence.
Advice on deployment pipeline design has remained largely unchanged since 2010, when Jez Humble recommended “make your pipeline wide, not long… and parallelise each stage as much as you can“. A long and thin deployment pipeline of sequential activities is easy to reason about, but in theory parallelising activities between build and production will shorten lead times, and accelerate feedback loops. The trade-off is an increase in toolchain complexity and coordination costs between different teams participating in the technology value stream.
For example, imagine a technology value stream with sequential activities for automated acceptance tests, exploratory testing, and manual performance testing. This could be modelled as a long and thin deployment pipeline.

If those testing activities could be run in parallel, the long and thin deployment pipeline could be re-designed as a short and wide deployment pipeline.
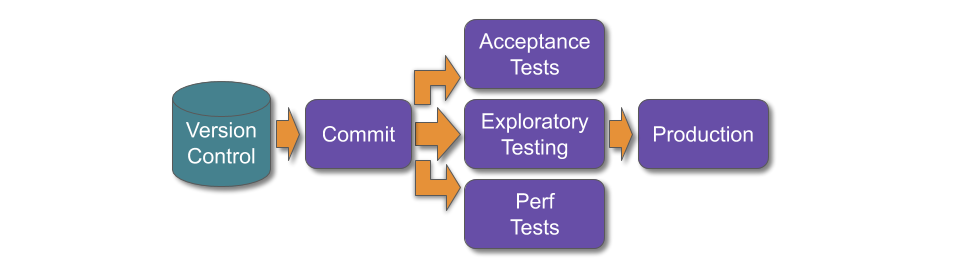
Since 2010, people in the Continuous Delivery community – including the author – have periodically recommended short and wide deployment pipelines over long and thin pipelines. That advice was flawed.
The Theory Of Constraints, Applied
The Theory Of Constraints is a management paradigm by Dr. Eli Goldratt, for improving organisational throughput in a homogeneous workflow. A constraint is any resource with capacity equal to, or less than market demand. Its level of utilisation will limit the utilisation of other resources. The aim is to iteratively increase the capacity of a constraint, until the flow of items can be balanced according to demand. The Theory Of Constraints is applicable to Continuous Delivery, as a technology value stream should be a homogeneous workflow that is as deterministic and invariable as possible.
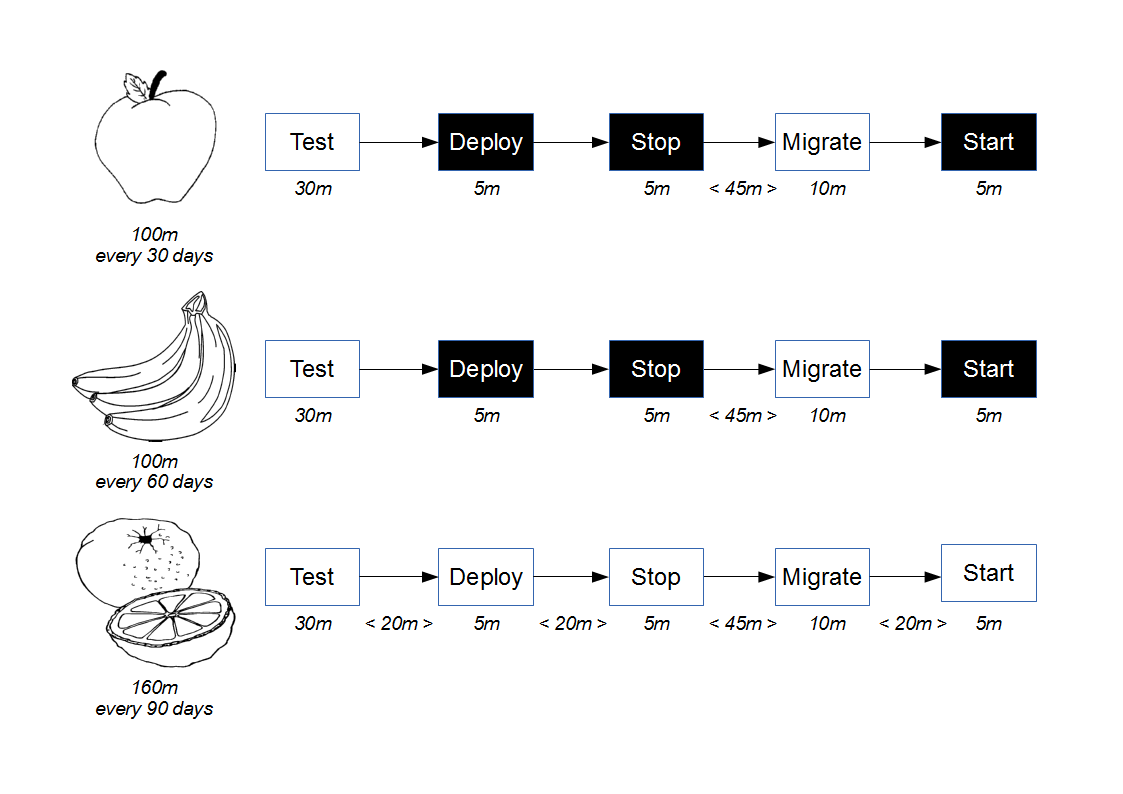
When a delivery team is in a state of Discontinuous Delivery, its technology value stream will contain a constrained activity with a duration less than the current lead time, but too large for the target lead time. The duration might be greater than the target lead time, or the largest duration of all the activities. A short and wide deployment pipeline will not be able to meet the target lead time, as the duration of the parallel activities will be limited by the constrained activity.
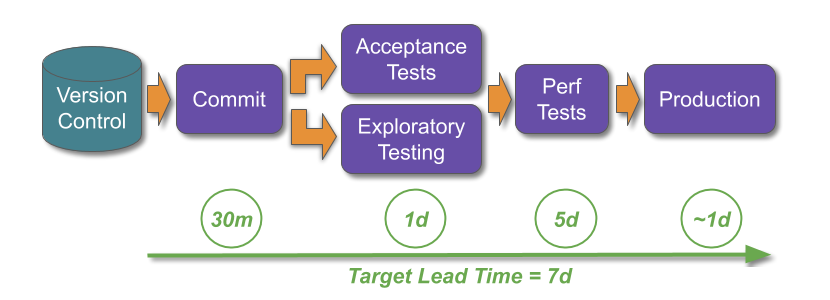
In the above example, assume the current lead time is 14 days, and manual performance testing takes 12 days as it involves end-to-end performance testing with a third party.
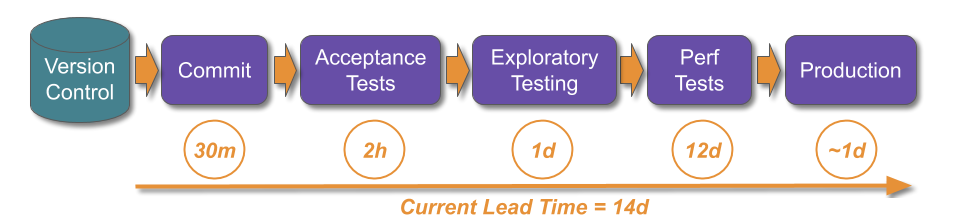
Assume customer demand results in a target lead time of 7 days. This means the delivery team are in a state of Discontinuous Delivery, and a long and thin deployment pipeline would be unable to meet that target.
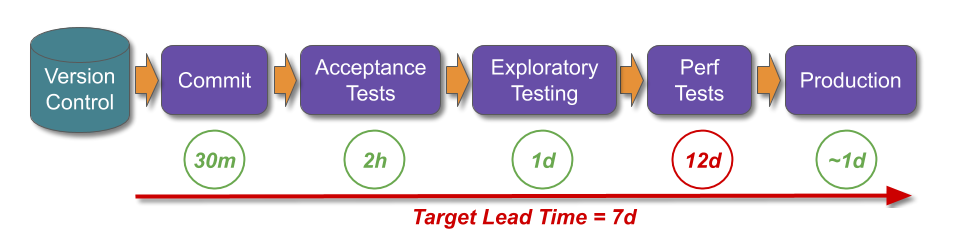
A short and wide deployment pipeline would also be unable to achieve the target lead time. The parallel testing activities would be limited by the 12 days of manual performance testing, and future release candidates would queue before the constrained activity. An obvious countermeasure would be for some release candidates to skip manual performance testing, but that would increase the risk of production incidents.
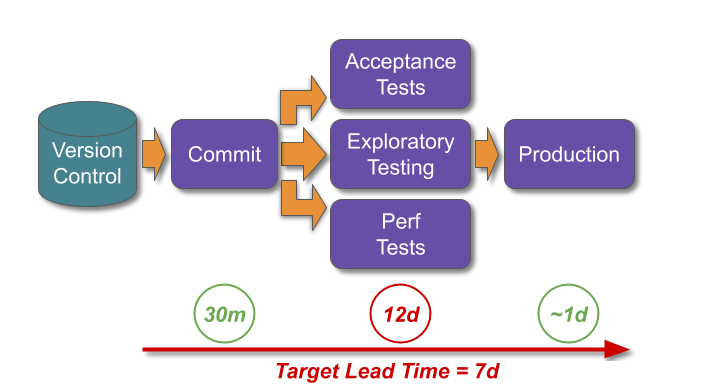
This means long and thin vs. short and wide deployment pipelines is a false dichotomy.
Pipeline Design and The Theory Of Constraints
In The Goal, Dr. Eli Goldratt describes the Theory Of Constraints as an iterative cycle known as the Five Focussing Steps: identify a constraint, reduce its wasted capacity, regulate its item arrival rate, increase its capacity, and then repeat.
If the activities in a technology value stream can be re-sequenced, re-designing a deployment pipeline is one way to reduce wasted time at a constrained activity, and regulate the arrival of release candidates. Pipeline flexibility is more important than any particular pipeline design, as it enables experimentation until a Goldilocks deployment pipeline can be found.
The constrained activity should not be the first activity after release candidate creation. This would reduce subsequent release candidate queues, and statistical fluctuations in unconstrained activities. However, constraint time should never be wasted on items with knowable defects, and most activities in a deployment pipeline are testing activities.
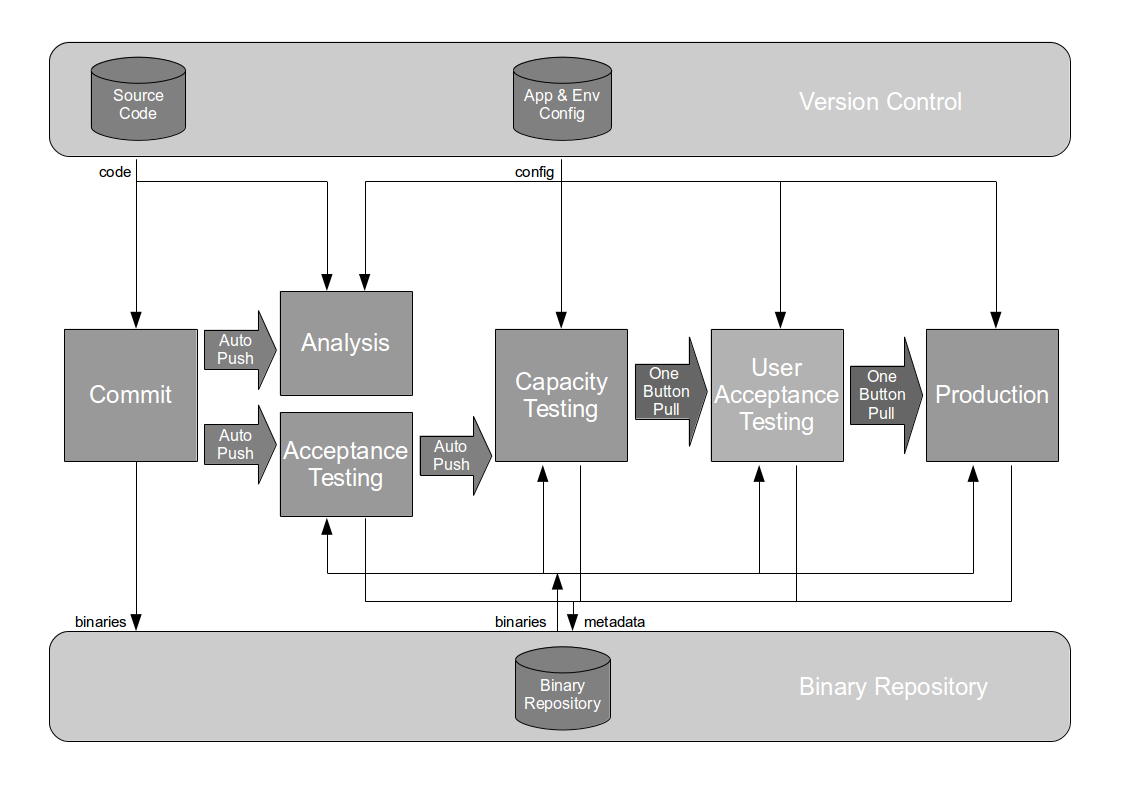
One Goldilocks deployment pipeline design is for all unconstrained testing activities to be parallelised before the constrained activity. This should be combined with other experiments to save constraint time, and regulate the flow of release candidates to minimise queues and statistical fluctuations. Such a pipeline design will make it easier for delivery teams to successfully implement Continuous Delivery.
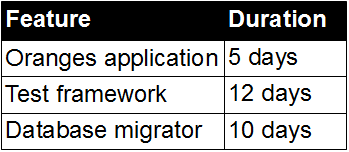
In the above example, assume the short and wide deployment pipeline can be re-designed so manual performance testing occurs after the other parallelised testing activities. This ensures release candidates with knowable defects are rejected prior to performance testing, which saves 1 day in queue time per release candidate. End-to-end performance testing scenarios are gradually replaced with stubbed performance tests and contract tests, which saves 6 days and means the target lead time can be accomplished.
If there is no constrained activity in a technology value stream, the delivery team is in a state of Continuous Delivery and a constraint will exist either upstream in product development or downstream in customer marketing. Further deployment pipeline improvements such as automated filtering of test scenarios could increase the speed of release candidate feedback, but the priority should be tackling the external constraint if product cycle time from ideation to customer is to be improved.
Acknowledgements
Thanks to Thierry de Pauw for his feedback on this article.





Recent Comments