The Version Control Strategies series
- Organisation antipattern – Release Feature Branching
- Organisation pattern – Trunk Based Development
- Organisation antipattern – Integration Feature Branching
- Organisation antipattern – Build Feature Branching
Build Feature Branching is oft-incompatible with Continuous Integration
Build Feature Branching is a version control strategy where developers commit their changes to individual remote branches of a source code repository prior to the shared trunk. Build Feature Branching is possible with centralised Version Control Systems (VCSs) such as Subversion and TFS, but it is normally associated with Distributed Version Control Systems (DVCSs) such as Git and Mercurial – particularly GitHub and GitHub Flow.
In Build Feature Branching Trunk is considered a flawless representation of all previously released work, and new features are developed on short-lived feature branches cut from Trunk. A developer will commit changes to their feature branch, and upon completion those changes are either directly merged into Trunk or reviewed and merged by another developer using a process such as a GitHub Pull Request. Automated tests are then executed on Trunk, testers manually verify the changes, and the new feature is released into production. When a production defect occurs it is fixed on a release branch cut from Trunk and merged back upon production release.
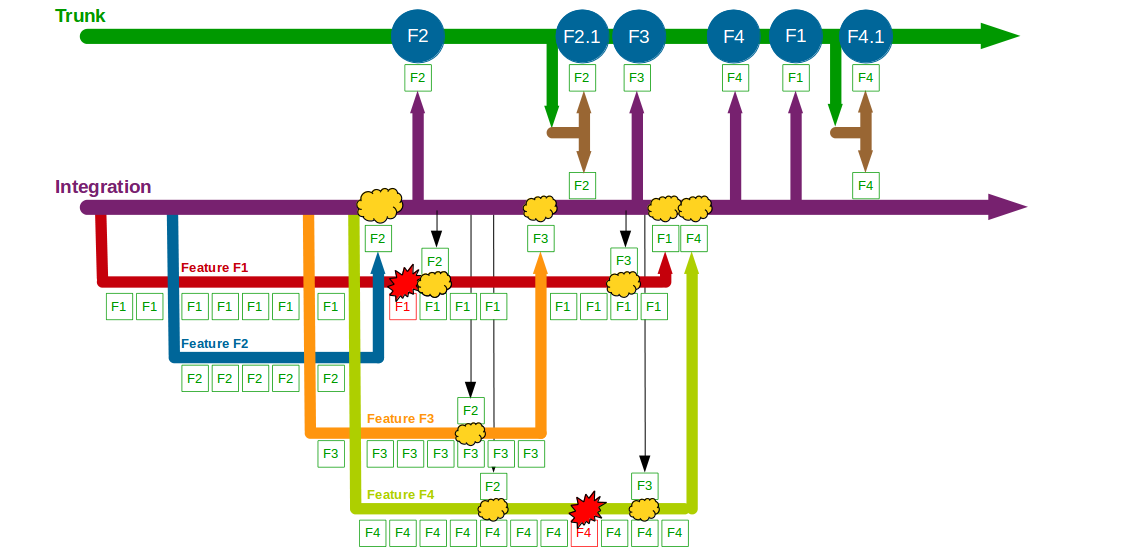
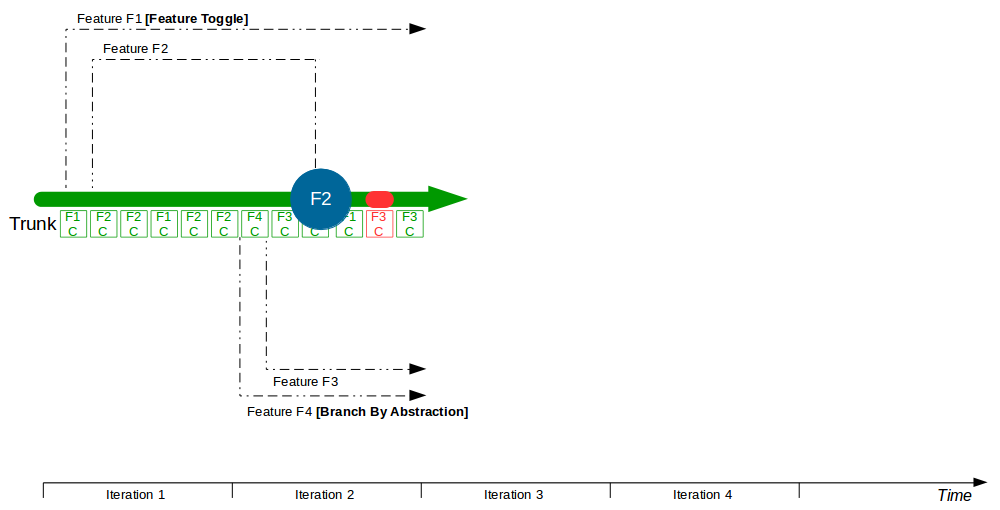
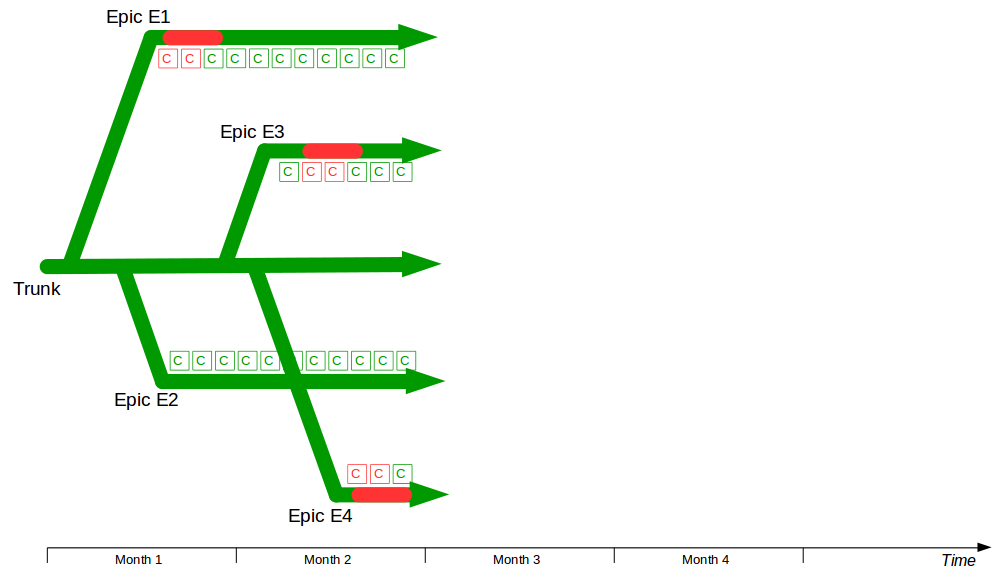
Consider an organisation that provides an online Company Accounts Service, with its codebase maintained by a team practising Build Feature Branching. Initially two features are requested – F1 Computations and F2 Write Offs – so F1 and F2 feature branches are cut from Trunk and developers commit their changes to F1 and F2.

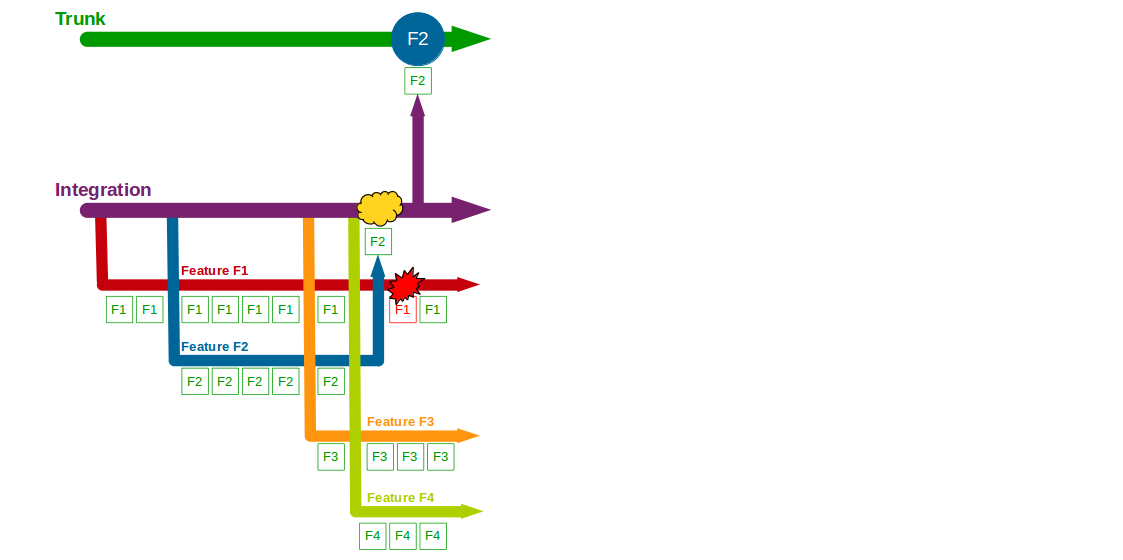
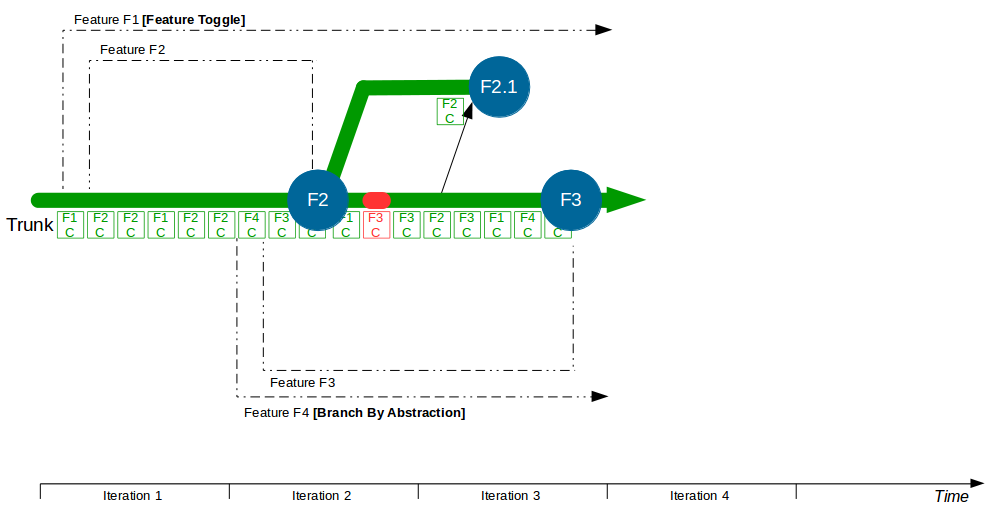
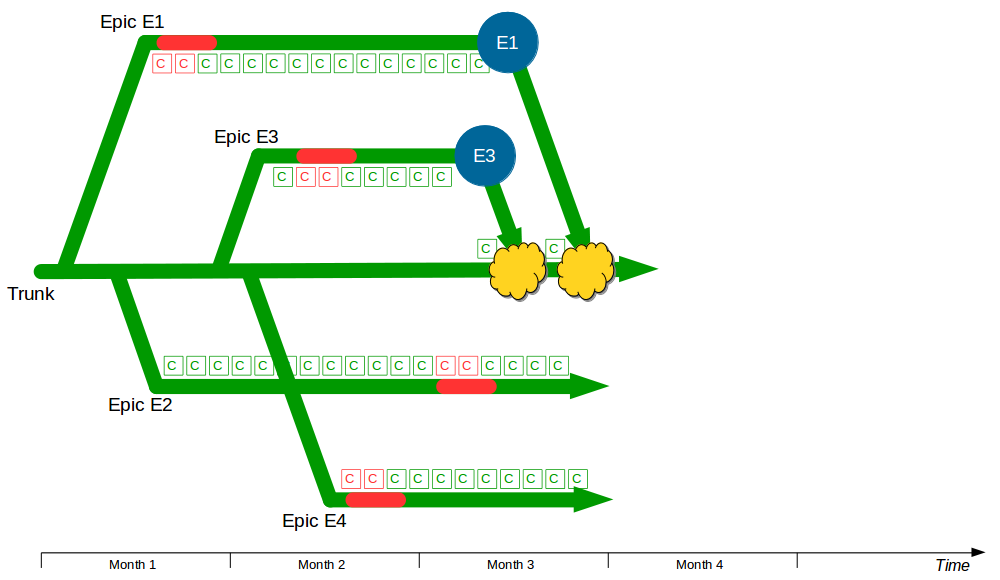
Two more features – F3 Bank Details and F4 Accounting Periods – then begin development, with F3 and F4 feature branches cut from Trunk and developers committing to F3 and F4. F2 is completed and merged into Trunk by a non-F2 developer following a code review, and once testing is signed off on Trunk + F2 it is released into production. The F1 branch grows to encompass a Computations refactoring, which briefly breaks the F1 branch.
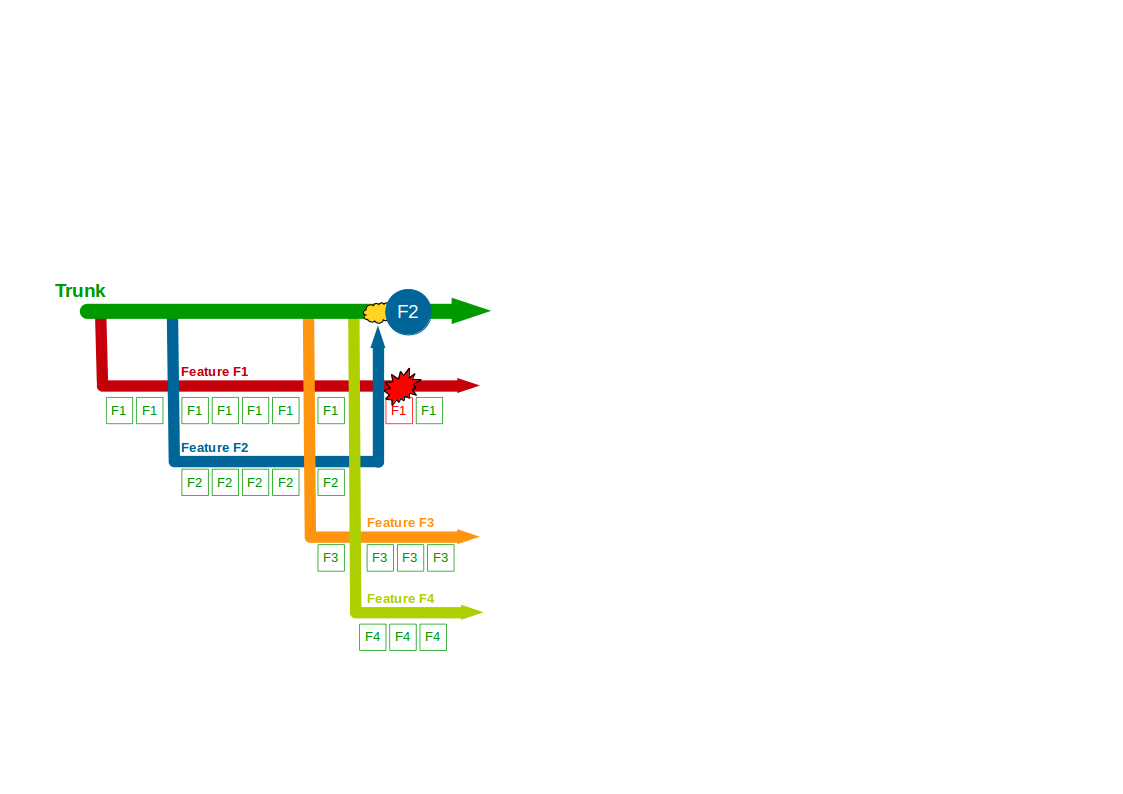
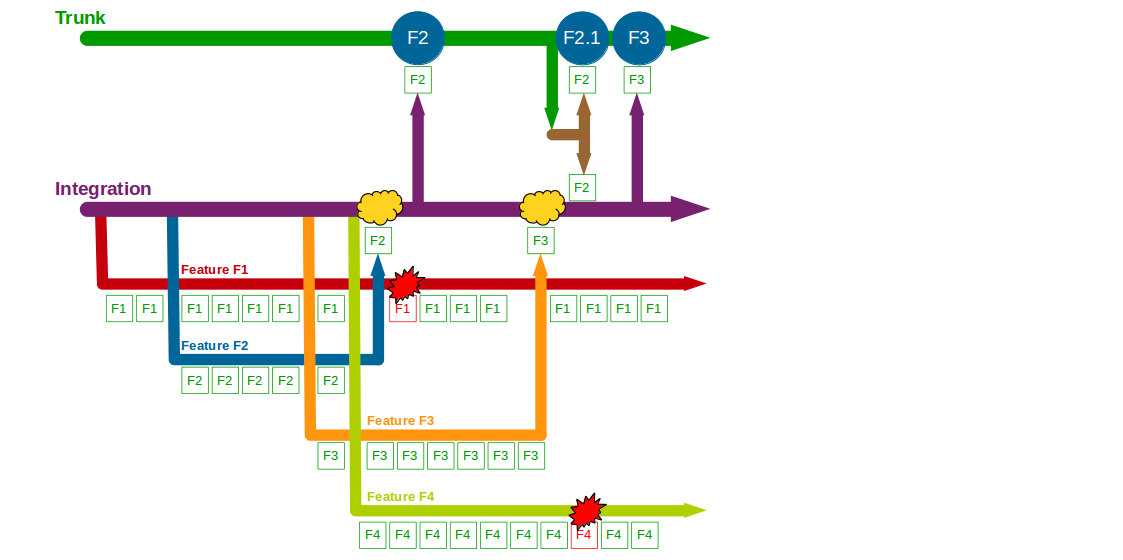
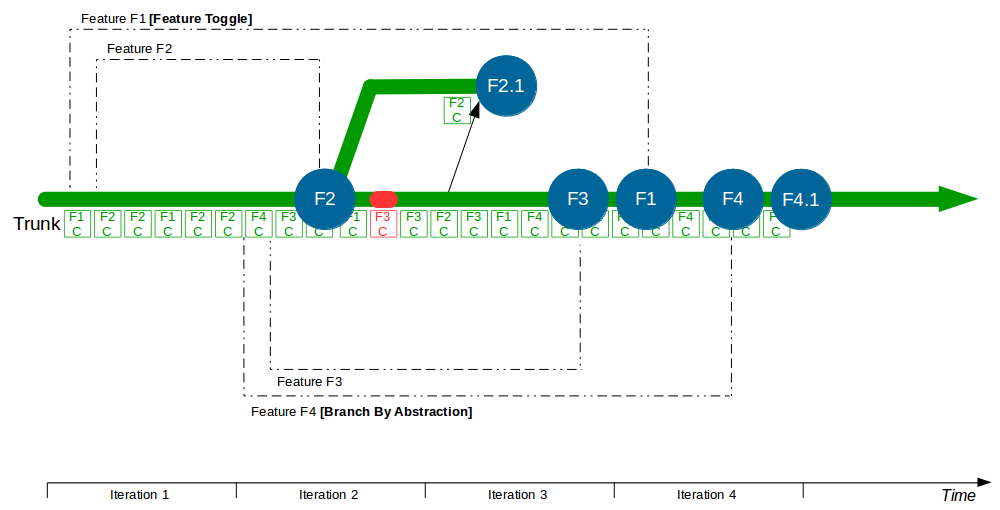
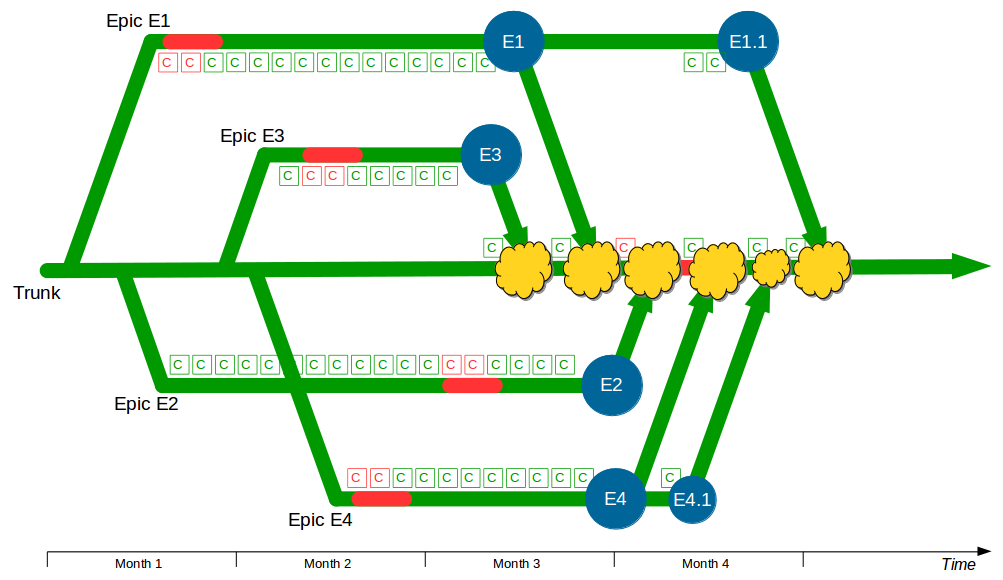
A production defect is found in F2, so a F2.1 fix for Write Offs is made on a release branch cut from Trunk + F2 and merged back when the fix is in production. F3 is deemed complete and merged into Trunk + F2 + F2.1 by a non-F3 developer, and after testing it is released into production. The F1 branch grows further as the Computations refactoring increases in scope, and the F4 branch is temporarily broken by an architectural change to the submissions system for Accounting Periods.
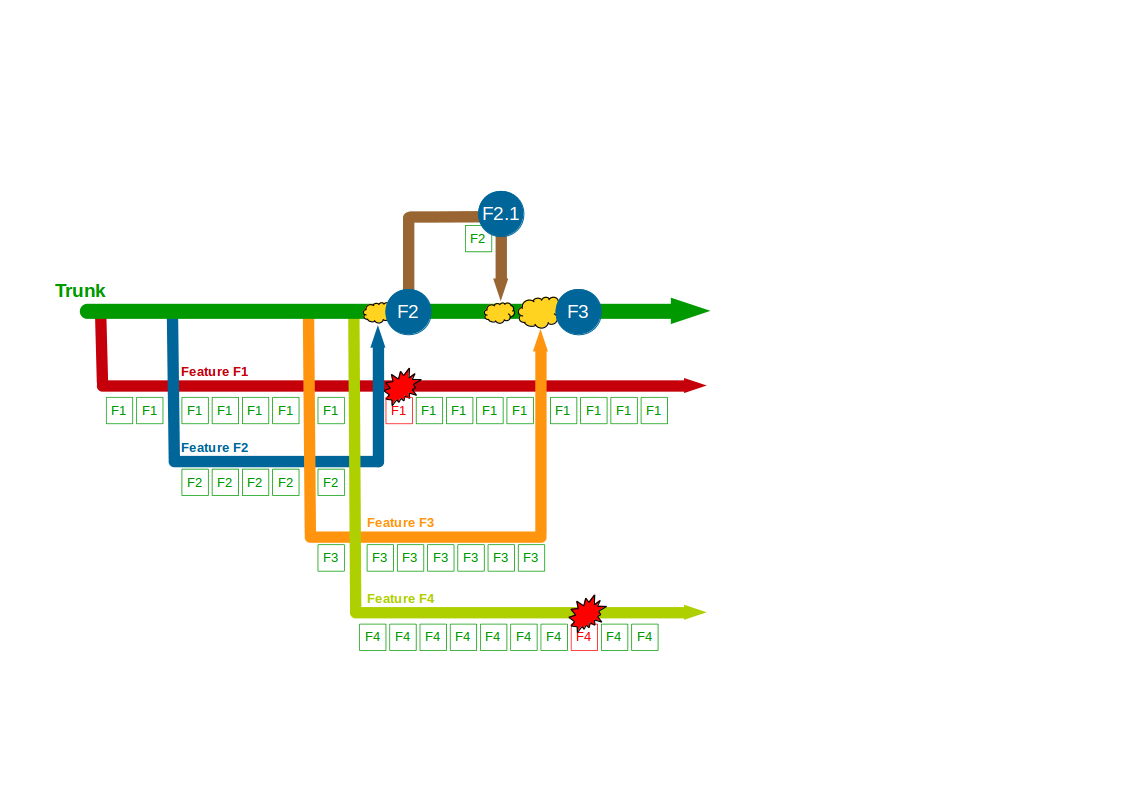
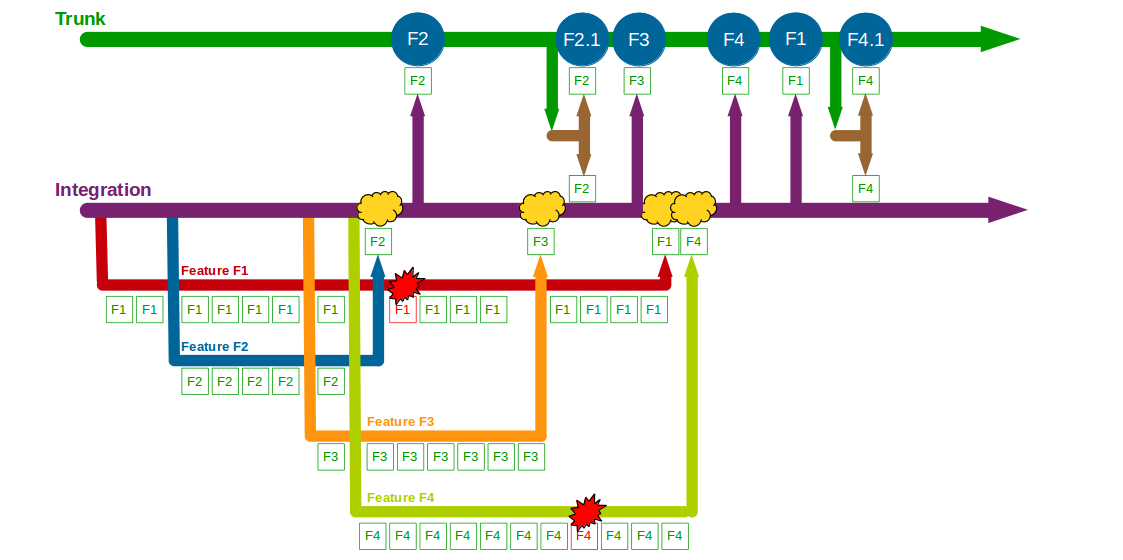
When F1 is completed the amount of modified code means a lengthy code review by a non-F1 developer and some rework are required before F1 can be merged into Trunk + F2 + F2.1 + F3, after which it is successfully tested and released into production. The architectural changes made in F4 also mean a time-consuming code review and merge into Trunk + F2 + F2.1 + F3 + F1 by a non-F4 developer, and after testing F4 goes into production. However, a production defect is then found in F4, and a F4.1 fix for Accounting Periods is made on a release branch and merged into Trunk + F2 + F2.1 + F3 + F1 + F4 once the defect is resolved.
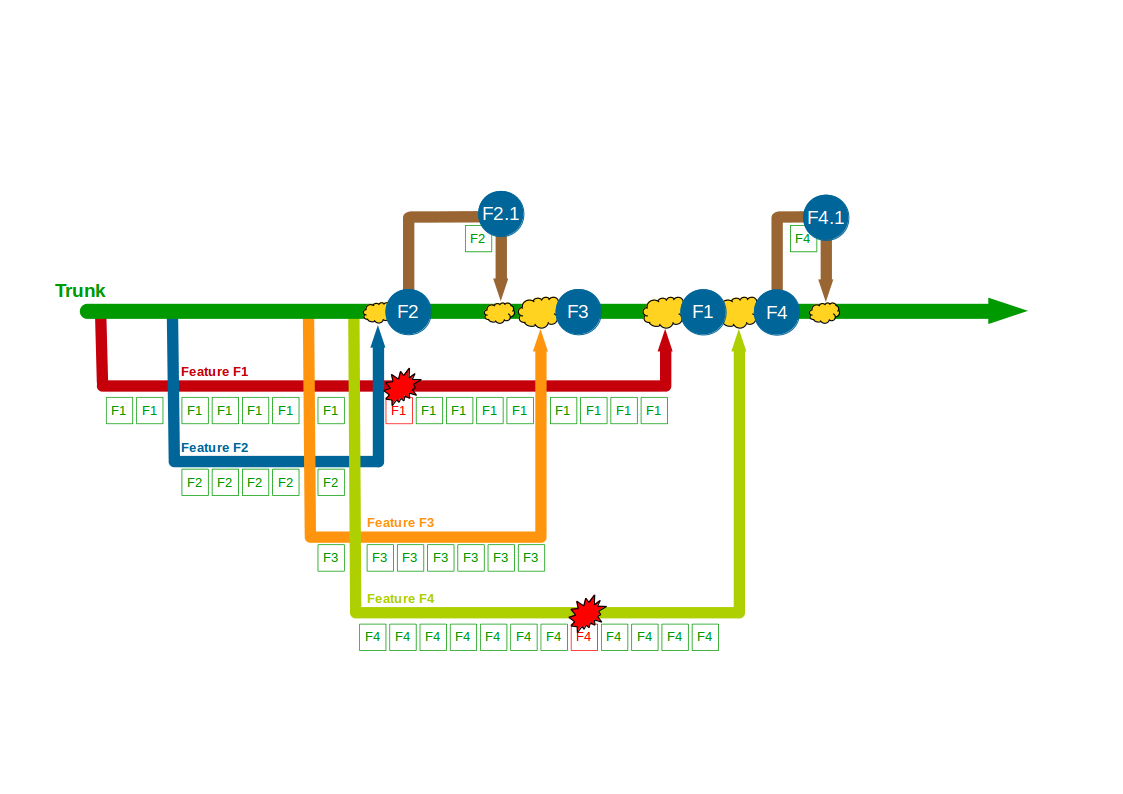
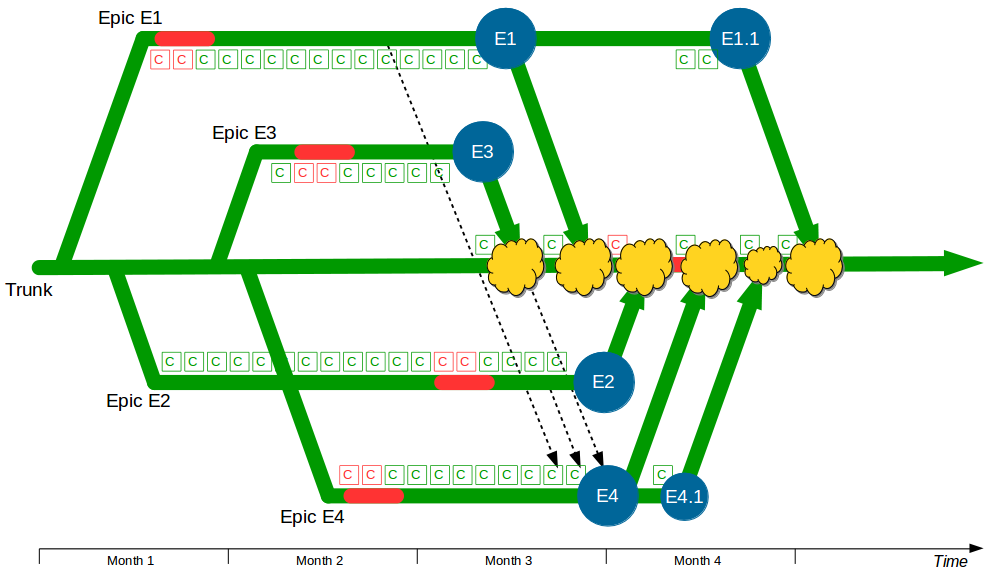
In this example F1, F2, F3, and F4 all enjoy uninterrupted development on their own feature branches. The emphasis upon short-lived feature branches reduces merge complexity into Trunk, and the use of code reviews lowers the probability of Trunk build failures. However, the F1 and F4 feature branches grow unchecked until they both require a complex, risky merge into Trunk.
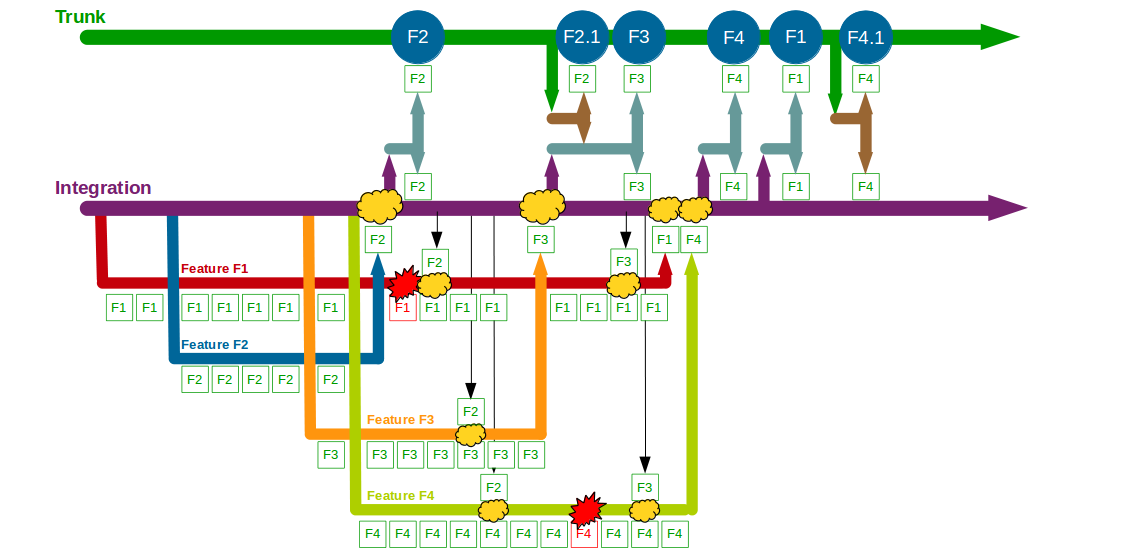
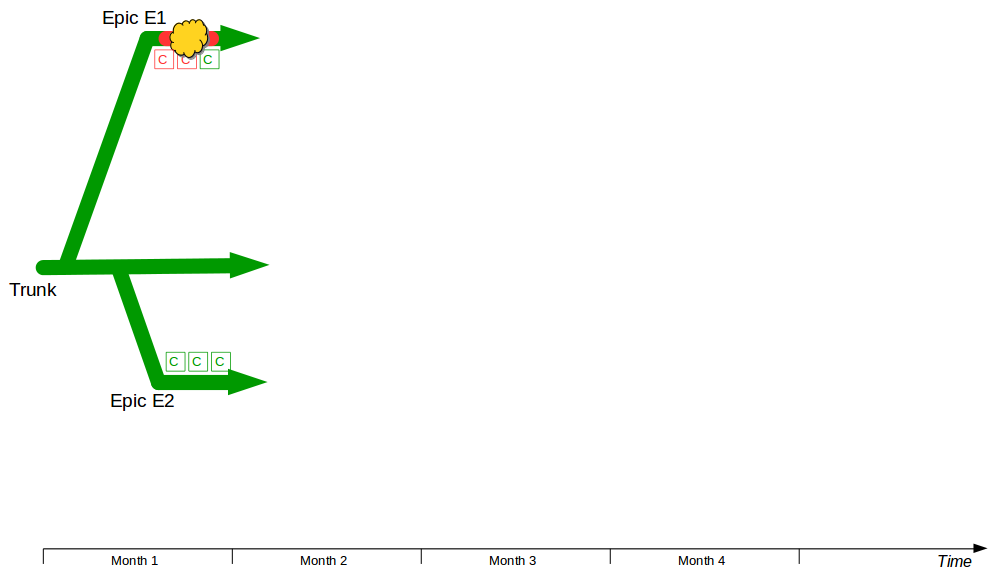
The Company Accounts Service team might have used Promiscuous Integration to reduce the complexity of merging each feature branch into Trunk, but that does not prevent the same code deviating on different branches. For example, integrating F2 and F3 into F1 and F4 would simplify merging F1 and F4 into Trunk later on, but it would not restrain F1 and F4 from generating Semantic Conflicts if they both modified the same code.
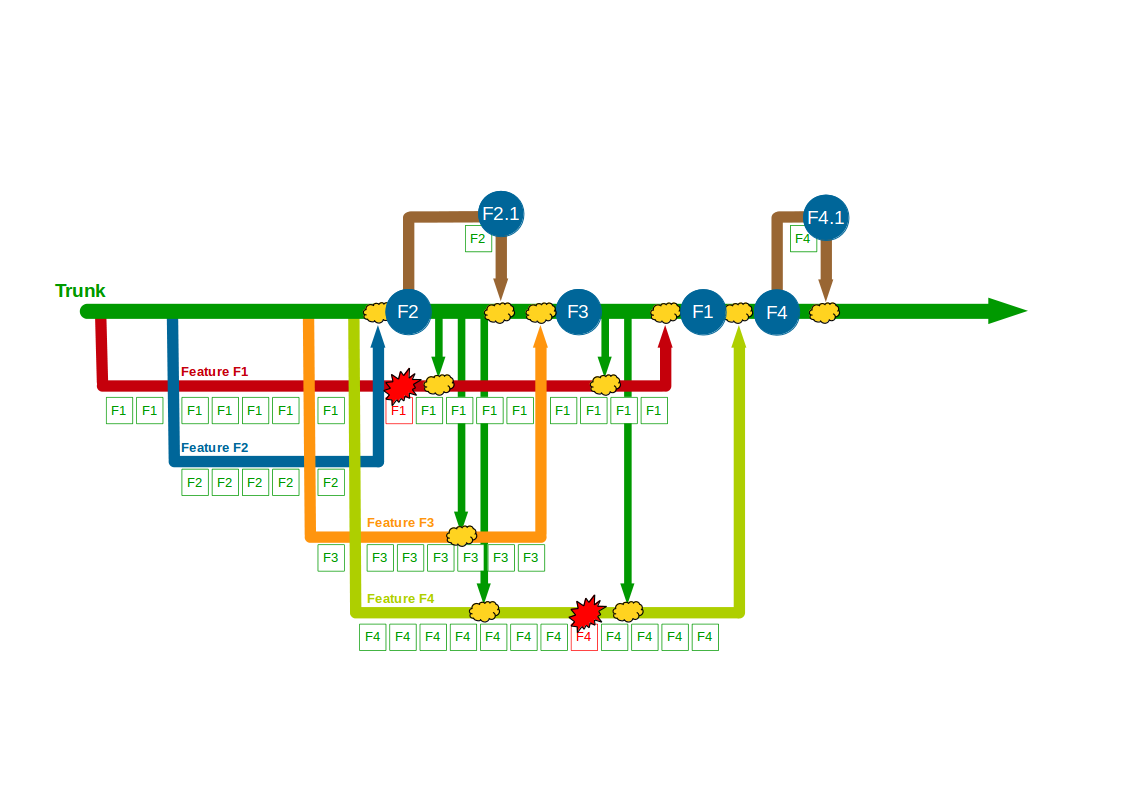
This example shows how Build Feature Branching typically inserts a costly integration phase into software delivery. Short-lived feature branches with Promiscuous Integration should ensure minimal integration costs, but the reality is feature branch duration is limited only by developer discipline – and even with the best of intentions that discipline is all too easily lost. A feature branch might be intended to last only for a day, but all too often it will grow to include bug fixes, usability tweaks, and/or refactorings until it has lasted longer than expected and requires a complex merge into Trunk. This is why Build Feature Branching is normally incompatible with Continuous Integration, which requires every team member to integrate and test their changes on Trunk on at least a daily basis. It is highly unlikely every member of a Build Feature Branching team will merge to Trunk daily as it is too easy to go astray, and while using a build server to continuously verify branch integrity is a good step it does not equate to shared feedback on the whole system.
Build Feature Branching advocates that the developer of a feature branch should have their changes reviewed and merged into Trunk by another developer, and this process is well-managed by tools such as GitHub Pull Requests. However, each code review represents a handover period full of opportunities for delay – the developer might wait for reviewer availability, the reviewer might wait for developer context, the developer might wait for reviewer feedback, and/or the reviewer might wait for developer rework. As Allan Kelly has remarked “code reviews lose their efficacy when they are not conducted promptly“, and when a code review is slow the feature branch grows stale and Trunk merge complexity increases. A better technique to adopt would be Pair Programming, which is a form of continuous code review with minimal rework.
Asking developers working on orthogonal tasks to share responsibility for integrating a feature into Trunk dilutes responsibility. When one developer has authority for a feature branch and another is responsible for its Trunk merge both individuals will naturally feel less responsible for the overall outcome, and less motivated to obtain rapid feedback on the feature. It is for this reason Build Feature Branching often leads to what Jim Shore refers to as Asynchronous Integration, where the developer of a feature branch starts work on the next feature immediately after asking for a review, as opposed to waiting for a successful review and Trunk build. In the short-term Asynchronous Integration leads to more costly build failures, as the original developer must interrupt their new feature and context switch back to the old feature to resolve a Trunk build failure. In the long-term it results in a slower Trunk build, as a slow build is more tolerable when it is monitored asynchronously. Developers will resist running a full build locally, developers will then checkin less often, and builds will gradually slowdown until the entire team grinds to a halt. A better solution is for developers to adopt Synchronous Integration in spite of Build Feature Branching, and by waiting on Trunk builds they will be compelled to optimise it using techniques such as acceptance test parallelisation.
Build Feature Branching works well for open-source projects where a small team of experienced developers must integrate changes from a disparate group of contributors, and the need to mitigate different timezones and different levels of expertise outweighs the need for Continuous Integration. However, for commercial software development Build Feature Branching fits the Wikipedia definition of an antipattern – “a common response to a recurring problem that is usually ineffective and risks being highly counterproductive“. A small, experienced team practising Build Feature Branching could theoretically accomplish Continuous Integration given a well-structured architecture and a predictable flow of features, but it would be unusual. For the vast majority of co-located teams working on commercial software Build Feature Branching is a costly practice that discourages collaboration, inhibits refactoring, and by implicitly sacrificing Continuous Integration acts as a significant impediment to Continuous Delivery. As Paul Hammant has said, “you should not make branches for features regardless of how long they are going to take“.
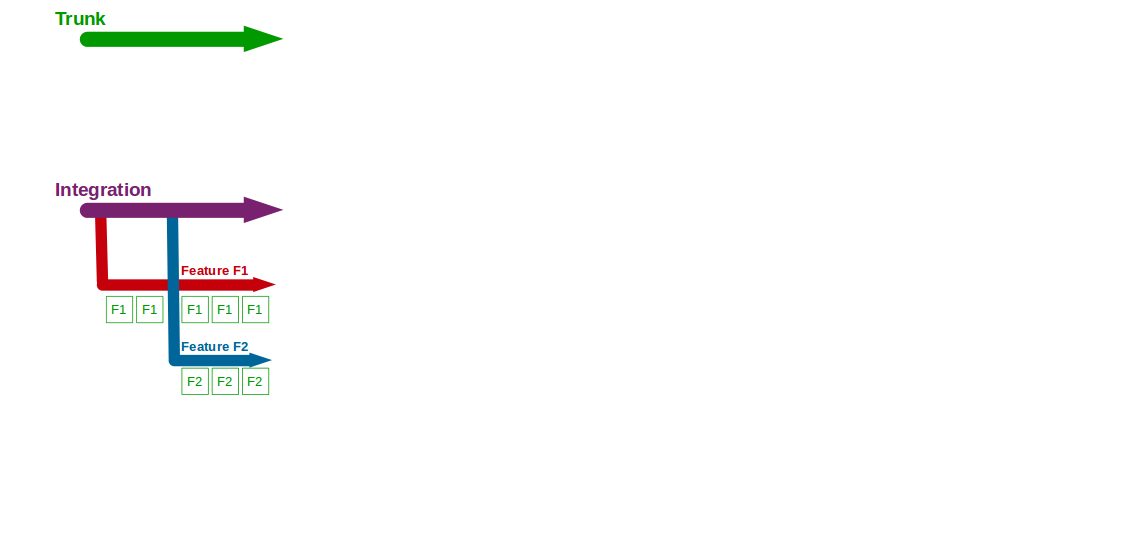

Recent Comments