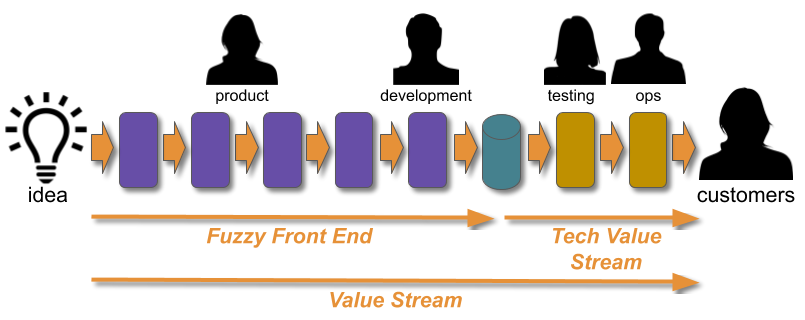
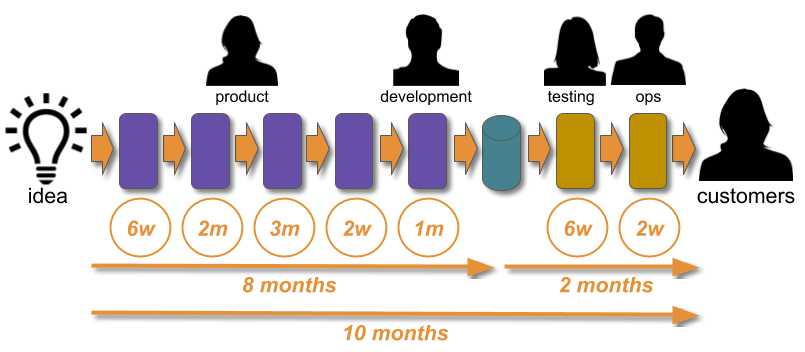
How can Multi-Demand Operations eliminate handoffs and adhere to ITIL? Why are Service Transition, Change Management, and Production Support activities inimical to Continuous Delivery? How can such Policy Rules can be turned into ITIL-compliant Policy Guidelines that increase flow?
This is part 5 of the Strategising for Continuous Delivery series
Know Operations activities
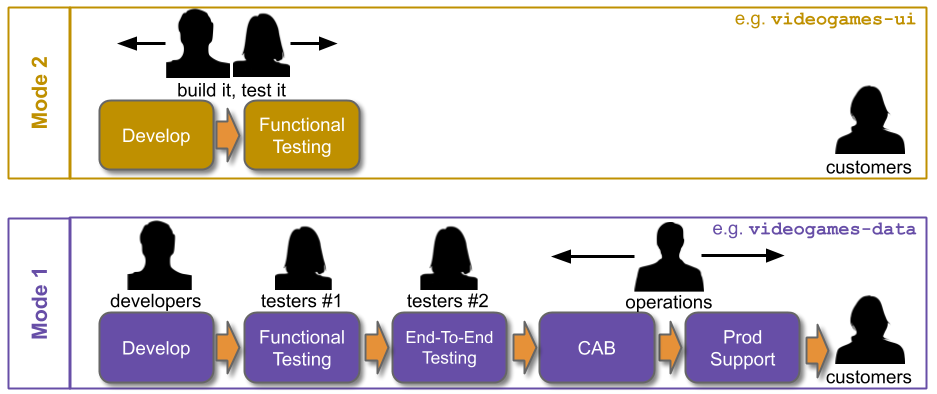
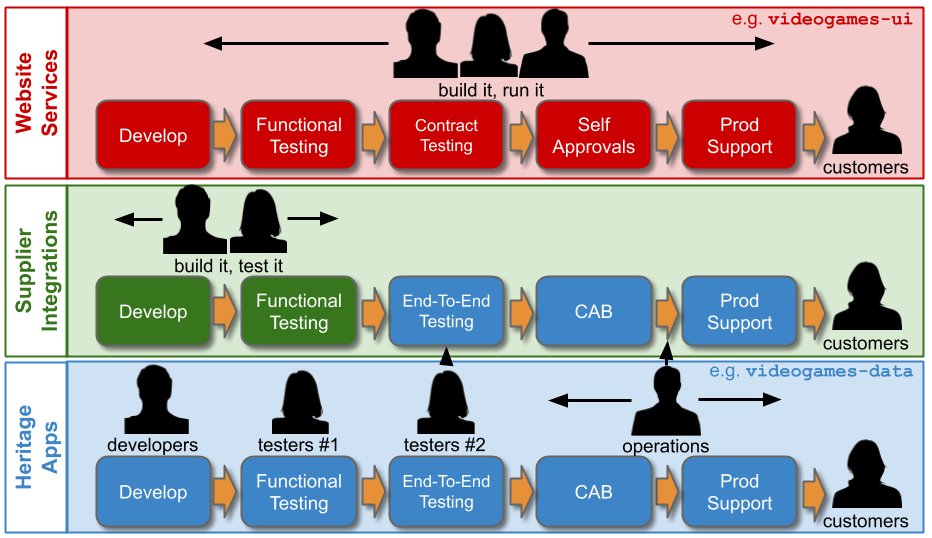
When an organisation has IT As A Cost Centre, its IT department will consist of siloed Delivery and Operations groups. This is based on the outdated COBIT notion of sequential Plan-Build-Run activities, with Delivery teams building applications and Operations teams running them. If the Operations group has adopted ITIL Service Management, its Run activities will include:
- Service Transition – perform operational readiness checks for an application prior to live traffic
- Change Management – approve releases for an application with live traffic
- Tiered Production Support – monitor for and respond to production incidents for applications with live traffic
Well-intentioned, hard working Operations teams in IT As A Cost Centre will be incentivised to work in separate silos to implement these activities as context-free, centralised Policy Rules.
See rules as constraints
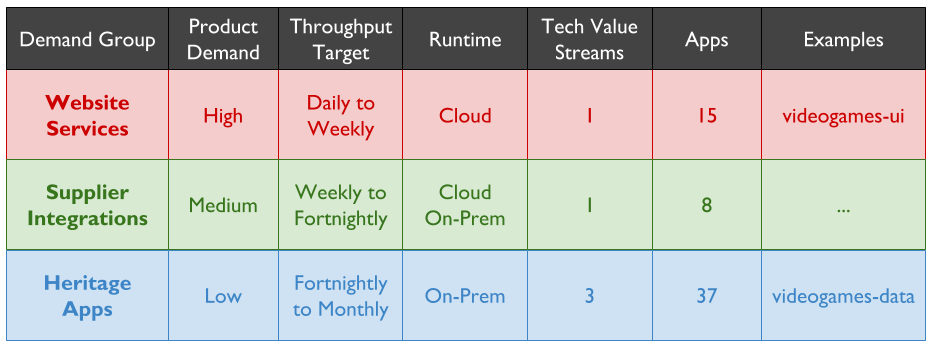
Policy Rules from Operations will inevitably inject delays and rework into a technology value stream, due to the handoffs and coordination costs involved. One of those Policy Rules will likely constrain throughput for all applications in a high demand group, even if it has existed without complaint in lower demand groups for years.
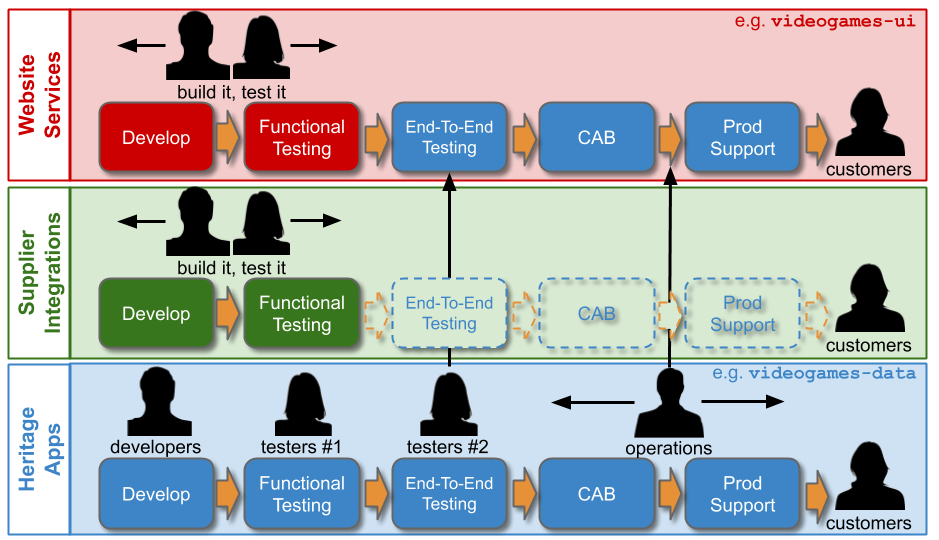
Service Transition can delay an initial live launch by weeks or months. Handing over an application from Delivery to Operations means operational readiness is only checked at the last minute. This can result in substantial rework on operational features when a launch deadline looms, and little time is available. Furthermore, there is little incentive for Delivery teams to assess and improve operability when Operations will do it for them.
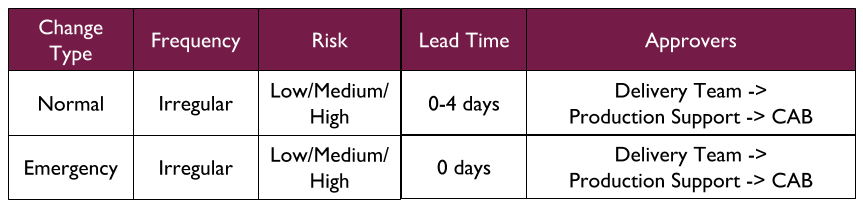
Change Management can delay a release by days or weeks. Requesting an approval means a Change Advisory Board (CAB) of Operations stakeholders must find the time to meet and assess the change, and agree a release date. An approval might require rework in the paperwork, or in the application changeset. Delays and rework are exacerbated during a Change Freeze, when most if not all approvals are suspended for days at a time. In Accelerate, Dr. Nicole Forsgren et al prove a negative correlation between external approvals and throughput, and conclude “it is worse than having no change approval process at all”.
Tiered Production Support can delay failure resolution by hours or days. Raising a ticket incurs a progression from a Level 1 service desk to Level 2 support agents, and onto Level 3 Delivery teams until the failure is resolved. Non-trivial tickets will go through one or more triage queues until the best-placed responder is found. A ticket might involve rework if repeated, unilateral reassignments occur between support levels, teams, and/or individuals. This is why Jon Hall argues in ITSM and why three-tier support should be replaced with Swarming “the current organizational structure of the vast majority of IT support organisations is fundamentally flawed”.
These Policy Rules will act as Risk Management Theatre to varying degrees in different demand groups. They are based on the misguided assumption that preventative controls on everyone will prevent anyone from making a mistake. They impede knowledge sharing, restrict situational awareness, increase opportunity costs, and actively contribute to Discontinuous Delivery.
Example – MediaTech
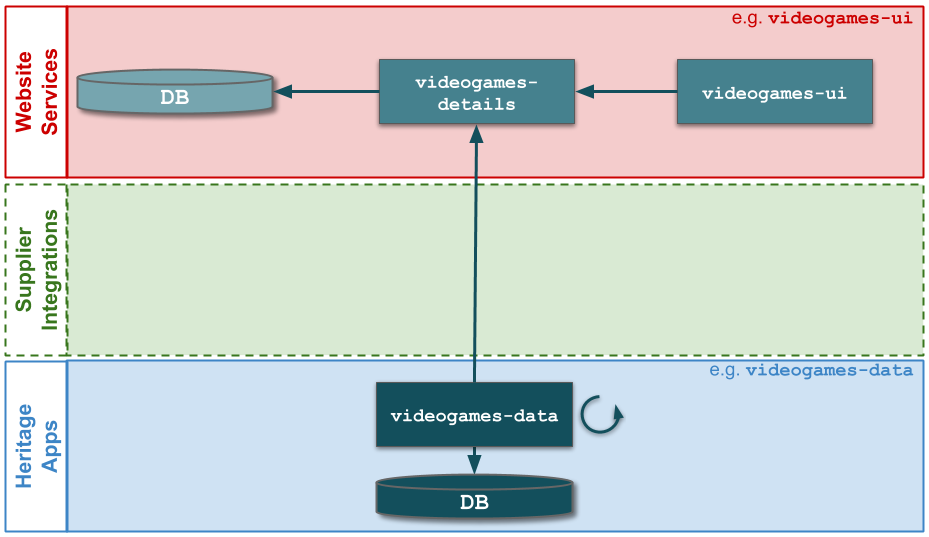
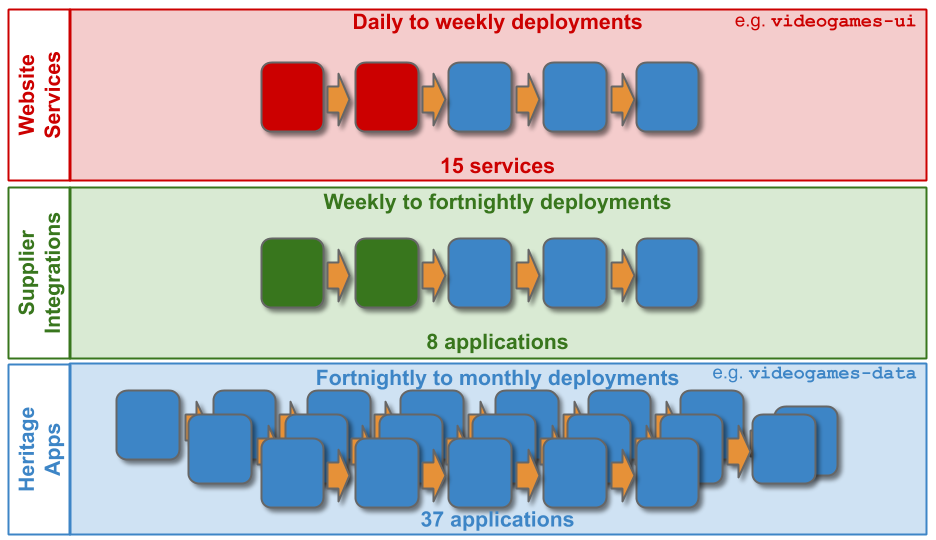
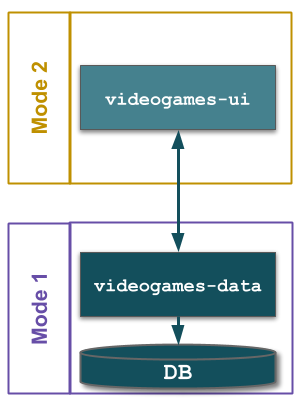
At MediaTech, an investment in re-architecting videogames-ui and videogames-data has increased videogames-ui deployment frequency to every 10 days. Yet the Website Services demand group has a target of 7 days, and using the Five Focussing Steps reveals Change Management is the constraint for all applications in the Website Services technology value stream.
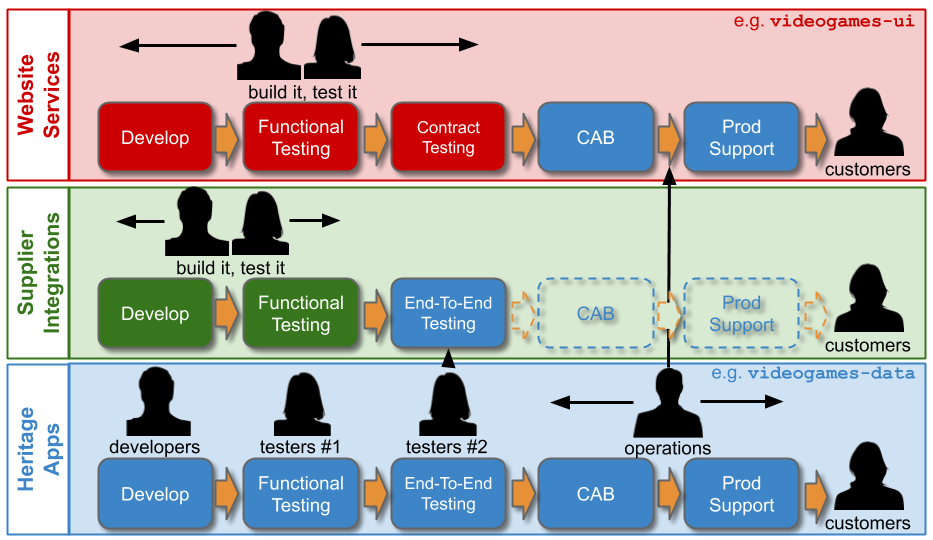
A Multi-Demand lens shows a Change Management policy inherited from the lower demand Supplier Integrations and Heritage Apps demand groups. All Website Services releases must have an approved Normal Change, as has been the case with Supplier Integrations and Heritage Apps for years. Normal Changes have a lead time of 0-4 days. This is the most time-consuming activity in Operations, due to the handoffs between approver groups. It is the constraint on Website Services like videogames-ui.
Create ITIL guidelines
Siloed Operations activities are predicated on high compute costs, and the high transaction cost of a release. That may be true for lower demand applications in an on-premise estate. However, Cloud Computing and Continuous Delivery have invalidated that argument for high demand applications. Compute and transaction costs can be reduced to near-zero, and opportunity costs are far more significant.
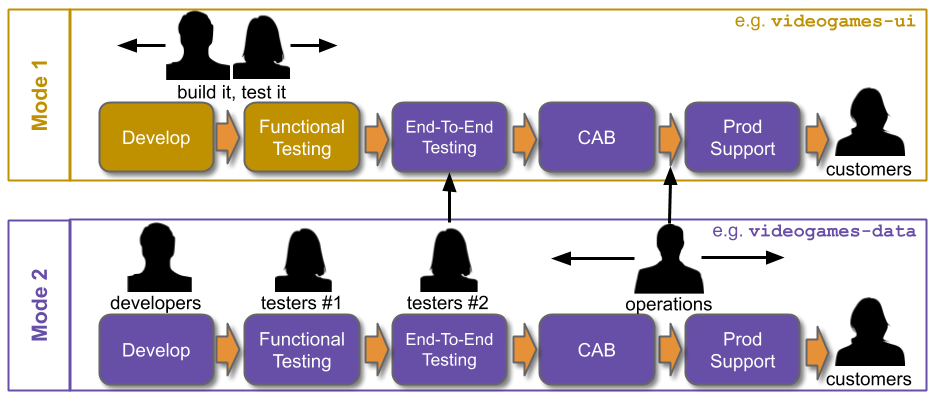
The intent behind Service Transition, Change Management, and Production Support is laudable. It is possible to re-design such Policy Rules into Policy Guidelines, and implement ITIL principles according to the throughput target of a demand group as well as its service management needs. Those Policy Rules can be replaced with Policy Guidelines, so high demand applications have equivalent lightweight activities while lower demand applications retain the same as before.
Converting Operations Policy Rules into Policy Guidelines will be more palatable to Operations stakeholders if a Multi-Demand Architecture is in place, and hard dependencies have previously been re-designed to shrink failure blast radius. A deployment pipeline for high demand applications that offers extensive test automation and stable deployments is also important.
Multi-Demand Service Transition
Service Transition can be replaced by Delivery teams automating a continual assessment of operational readiness, based on ITIL standards and Operations recommendations. Operational readiness checks should include availability, request throughput, request latency, logging dashboards, monitoring dashboards, and alert rules.
There should be a mindset of continual service transition, with small batch sizes and tight production feedback loops used to identify leading signals of inoperability before a live launch. For example, an application might have automated checks for the presence of a Four Golden Signals dashboard, and Service Level Objective alerts based on Request Success Rate.
Multi-Demand Change Management
Change Management can be streamlined by Delivery teams automating change approval creation and auditing. ITIL has Normal and Emergency Changes for irregular changes. It also has Standard Changes for repeatable, low risk changes which can be pre-approved electronically. Standard Changes are entirely compatible with Continuous Delivery.
Regular, low risk changes for a high demand application should move to a Standard Change template. Low risk, repeatable changes would be pre-approved for live traffic as often as necessary. The criteria for Standard Changes should be pre-agreed with Change Management. Entry criteria could be 3 successful Normal Changes, while exit criteria could be 1 failure.
Irregular, variable risk changes for high demand applications should move to team-approved Normal Changes. The approver group for low and medium risk changes would be the Delivery team, and high risk changes would have Delivery team leadership as well. Entry criteria could be 3 successful Normal Changes and 100% on operational readiness checks.
A Change Freeze should be minimised for high demand applications. For 1-2 weeks before a peak business event, there could be a period of heightened awareness that allows Standard Changes and low-risk Normal Changes only. There could be a 24 hour Change Freeze for the peak business event itself, that allows Emergency Changes only.
The deployment pipeline should have traceability built in. A change approval should be linked to a versioned deployment, and the underlying code, configuration, infrastructure, and/or schema changes. This should be accompanied by a comprehensive engineering effort from Delivery teams for ever-smaller changesets, so changes can remain low risk as throughput increases. This should include Expand-Contract, Decouple Release From Launch, and Canary Deployments for zero downtime deployments.
Multi-Demand Production Support
Tiered Production Support can be replaced by Delivery teams adopting You Build It, You Run It. A Level 1 service desk should remain for any applications with direct customer contact. Level 2 and Level 3 support should be performed by Delivery team engineers on-call 24/7/365 for the applications they build.
Logging dashboards, monitoring dashboards, and alert rules should be maintained by engineers, and alert notifications should be directed to the team. In working hours, a failure should be prioritised over feature development, and be investigated by multiple team members. Outside working hours, a failure should be handled by the on-call engineer. Teams should do their own incident management and post-incident reviews.
You Build It, You Run It maximises incentives for Delivery teams to build operability into their applications from the outset of development. Operational accountability should reside with the product owner. They should have to prioritise operational features against user features, from a single product backlog. There should be an emphasis on reliable live traffic over feature development, cross-functional collaboration within and between teams, and a cross-pollination of skills.
Example – MediaTech
At MediaTech, a prolonged investment is made in Operations activities for Website Services. The Service Transition and Tiered Production Support teams are repurposed to concentrate solely on lower demand, on-premise applications. Website Services teams take on continual service transition and You Build It, You Run It themselves. This provokes a paradigm shift in how operability is handled at MediaTech, as Website Services teams start to implement their own telemetry and share their learnings when failures occur.
Change Management agree with the Website Services teams that any application with a deployment pipeline and automated rollback can move to Standard Change after 3 successful Normal Changes. In addition, agreement is reached on experimental, team-approved Normal Changes. Applications with the Standard Change entry criteria and have passed all operational checks no longer require CAB approval for irregular changes.
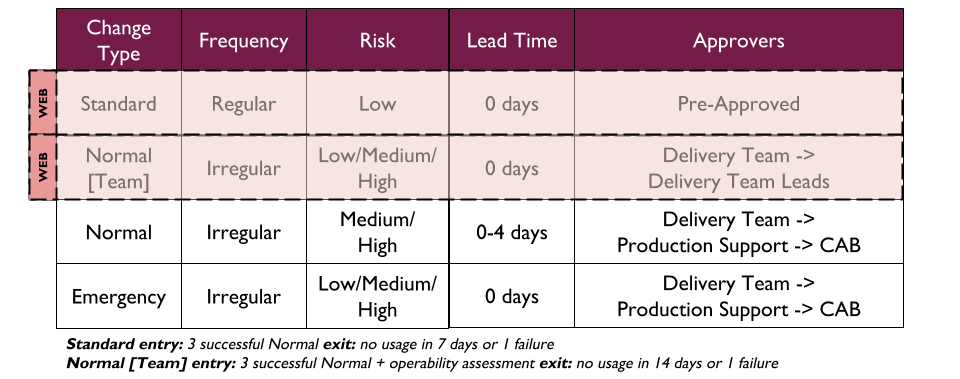
The elimination of handoffs and rework between Website Services and Operations teams means videogames-ui and videogames-ui deployment frequency can be increased to every 5 days. The applications are finally in a state of Continuous Delivery, and the next round of improvements can begin elsewhere in the MediaTech estate.
This is part 5 of the Strategising for Continuous Delivery series
- Strategising for Continuous Delivery
- The Bimodal Delusion
- Multi-Demand IT
- Multi-Demand Architecture
- Multi-Demand Operations
Acknowledgements
Thanks to Thierry de Pauw for reviewing this series.