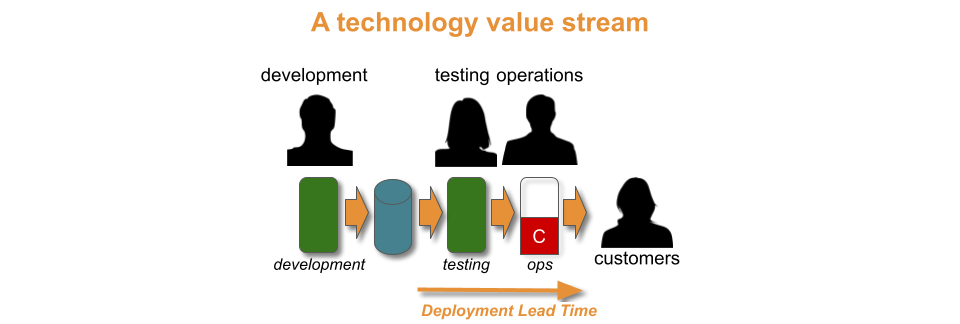
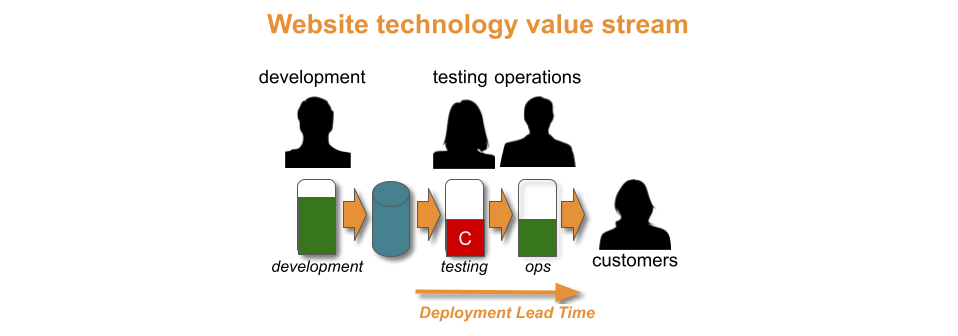
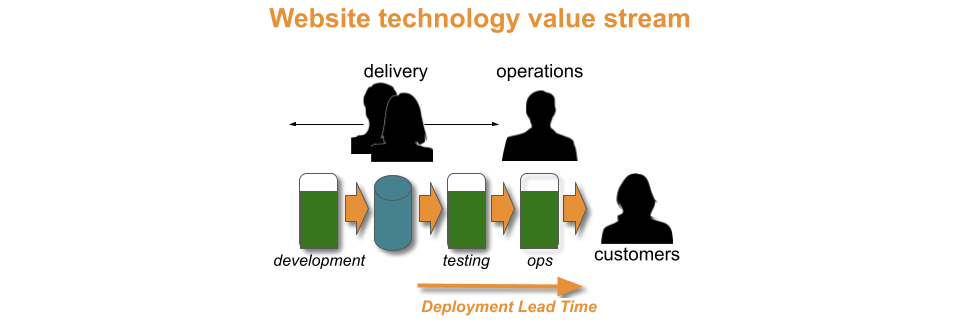
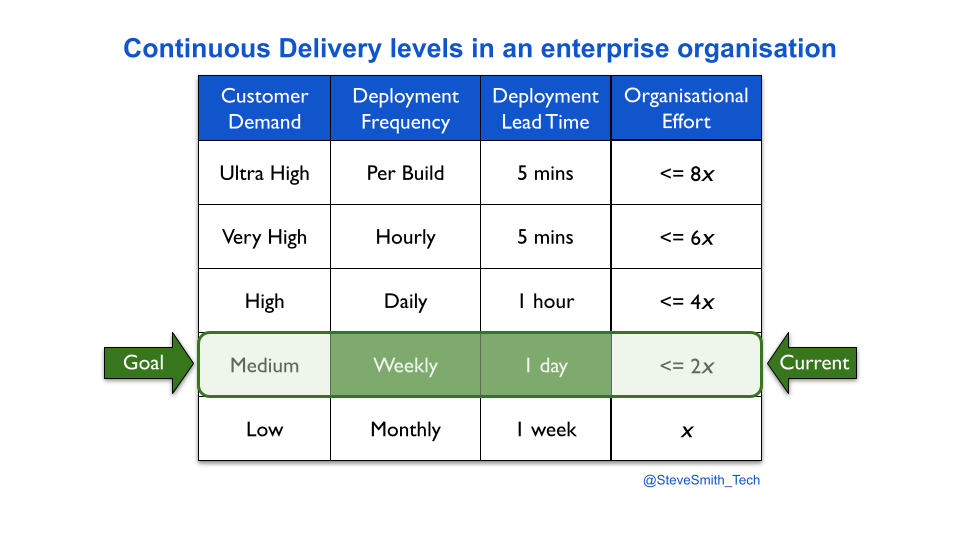
“Over the years, I’ve worked with many organisations who transition live software services into an operations team for maintenance mode. There’s usually talk of being feature complete, of costs needing to come under control, and the operations team being the right people for BAU work.
It’s all a myth. You’re never feature complete, you’re not measuring the cost of delay, and you’re expecting your operations team to preserve throughput, reliability, and quality on a shoestring budget.
You can ignore opportunity costs, but opportunity costs won’t ignore you.”
Steve Smith
Introduction
Maintenance mode is when a digital service is deemed to be feature complete, and transitioned into BAU maintenance work. Feature development is stopped, and only fixes and security patches are implemented. This usually involves a delivery team handing over their digital service to an operations team, and then the delivery team is disbanded.
Maintenance mode is everywhere that IT as a Cost Centre can be found. It is usually implemented by teams handing over their digital services to the operations team upon feature completion, and then the teams are disbanded. This happens with the Ops Run It operating model, and with You Build It You Run It as well. Its ubiquity can be traced to a myth:
Maintenance mode by an operations team preserves the same protection for the same financial exposure
This is folklore. Maintenance mode by your operations team might produce lower run costs, but it increases the risk of revenue losses from stagnant features, operational costs from availability issues, and reputational damage from security incidents.
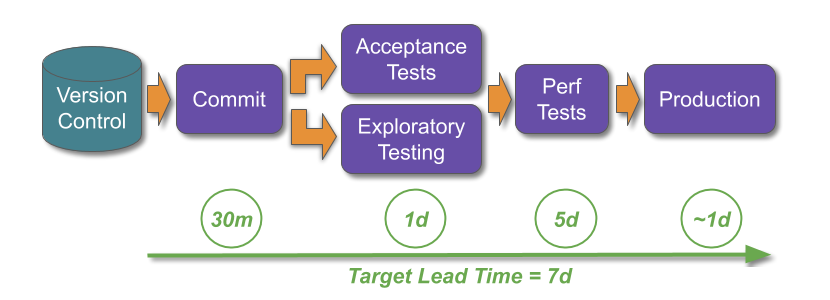
Imagine a retailer DIYers.com, with multiple digital services in multiple product domains. The product teams use You Build It You Run It, and have achieved their Continuous Delivery target measure of daily deployments. There is a high standard of quality and reliability, with incidents rapidly resolved by on-call product team engineers.
DIYers.com digital services are put into maintenance mode with the operations team after three months of live traffic. Product teams are disbanded, and engineers move into newer teams. There is an expected decrease in throughput, from daily to monthly deployments. However, there is also an unexpected decrease in quality and reliability. The operations team handles a higher number of incidents, and takes longer to resolve them than the product teams.
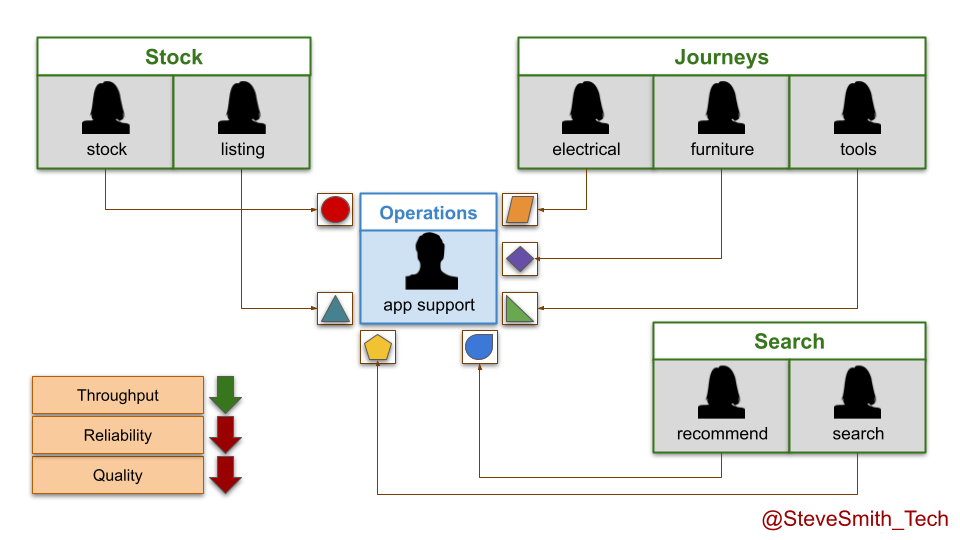
This produces some negative outcomes:
- Higher operational costs. The reduced run costs from fewer product teams are overshadowed by the financial losses incurred during more frequent and longer periods of DIYers.com website unavailability.
- Lower customer revenues. DIYers.com customers are making fewer website orders than before, spending less on merchandise per order, and complaining more about stale website features.
DIYers.com learned the hard way that maintenance mode by an operations team reduces protection, and increases financial exposure.
Maintenance mode reduces protection
Maintenance mode by an operations team reduces protection, because it increases deployment lead times.
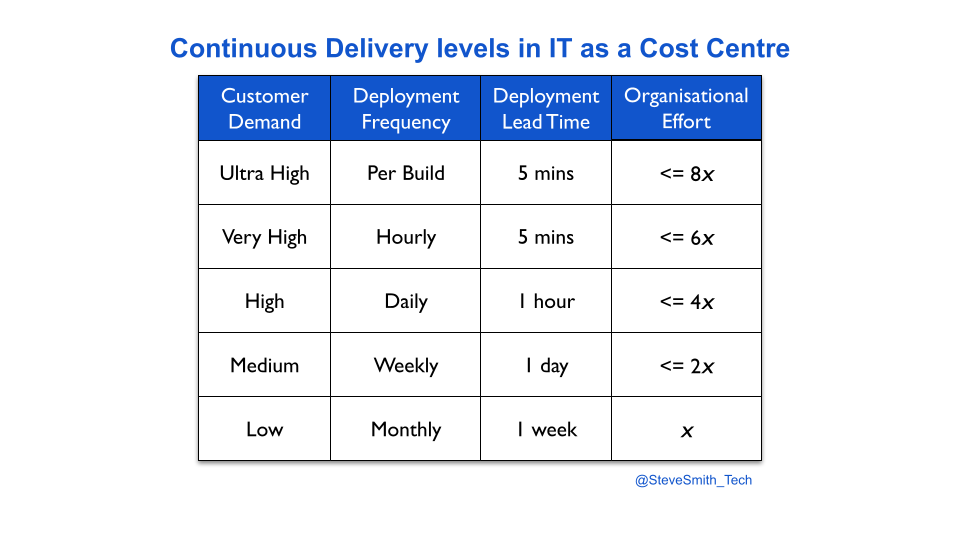
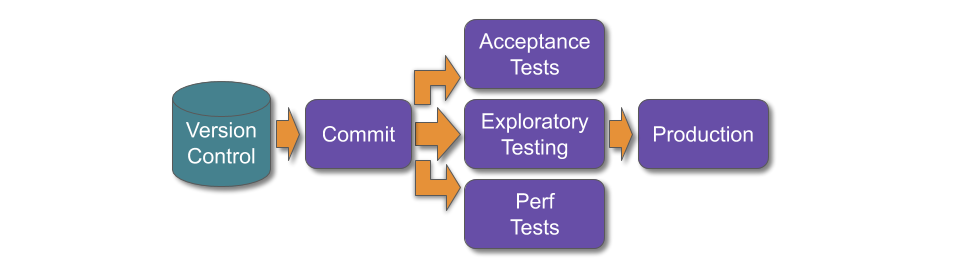
Transitioning a digital service into an operations team means fewer deployments. This can be visualised with deployment throughput levels. A You Build It You Run It transition reduces weekly deployments or more to a likely target measure of monthly deployments.
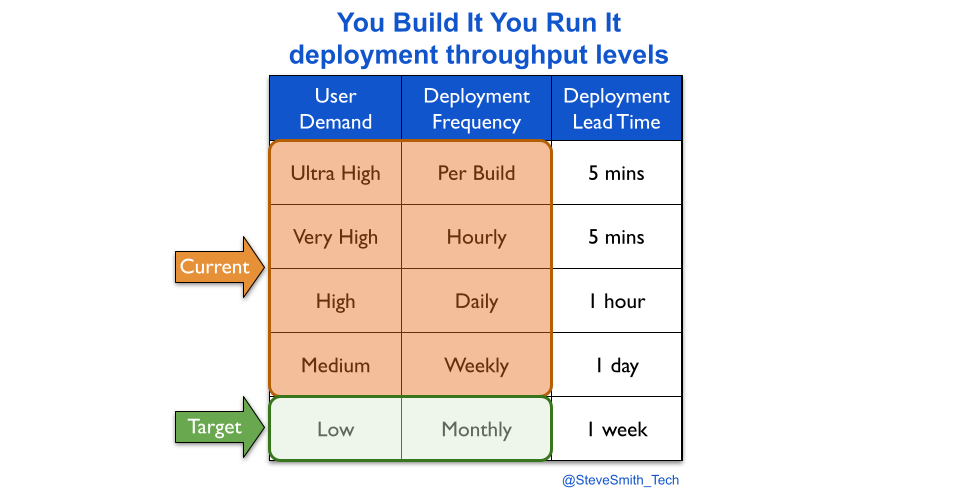
An Ops Run It transition probably reduces monthly deployments to a target measure of quarterly deployments.
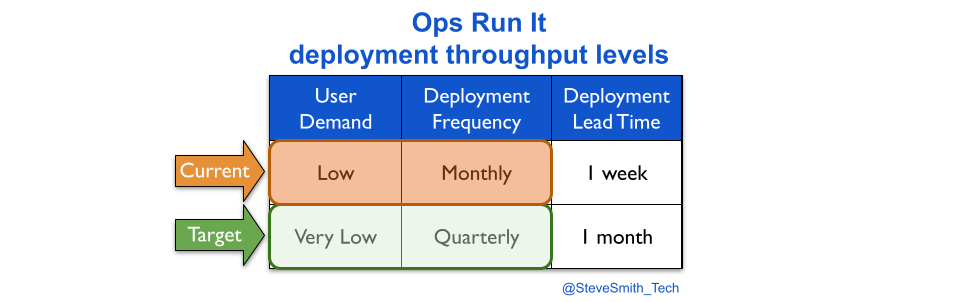
Maintenance mode also results in slower deployments. This happens silently, unless deployment lead time is measured. Reducing deployment frequency creates plenty of slack, and that additional time is consumed by the operations team building, testing, and deploying a digital service from a myriad of codebases, scripts, config files, deployment pipelines, functional tests, etc.
Longer deployment lead times result in:
- Lower quality. Less rigour is applied to technical checks, due to the slack available. Feedback loops become enlarged and polluted, as test suites become slower and non-determinism creeps in. Defects and config workarounds are commonplace.
- Lower reliability. Less time is available for proactive availability management, due to the BAU maintenance workload. More time is needed to identify and resolve incidents. Faulty alerts, inadequate infrastructure, and major financial losses upon failure become the norm.
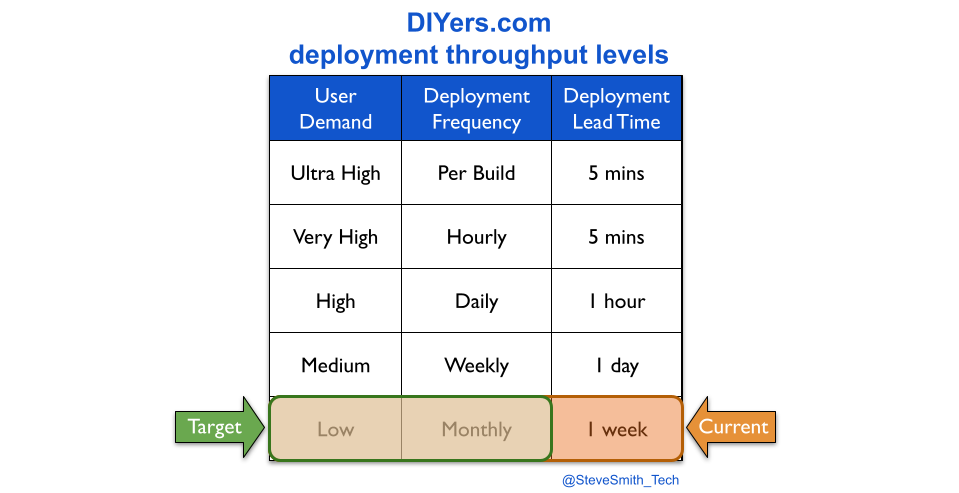
This situation worsens at scale. Each digital service inflicted on an operations team adds to their BAU maintenance workload. There is a huge risk of burnout amongst operations analysts, and deployment lead times subsequently rising until monthly deployments become unachievable.
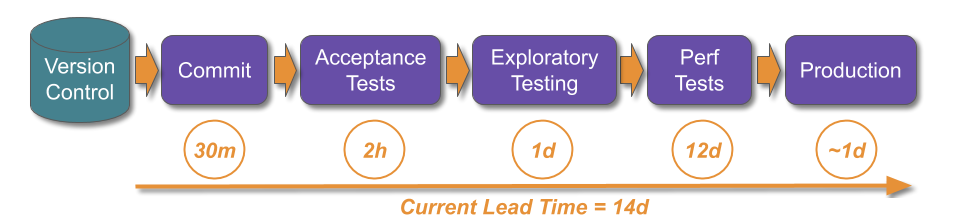
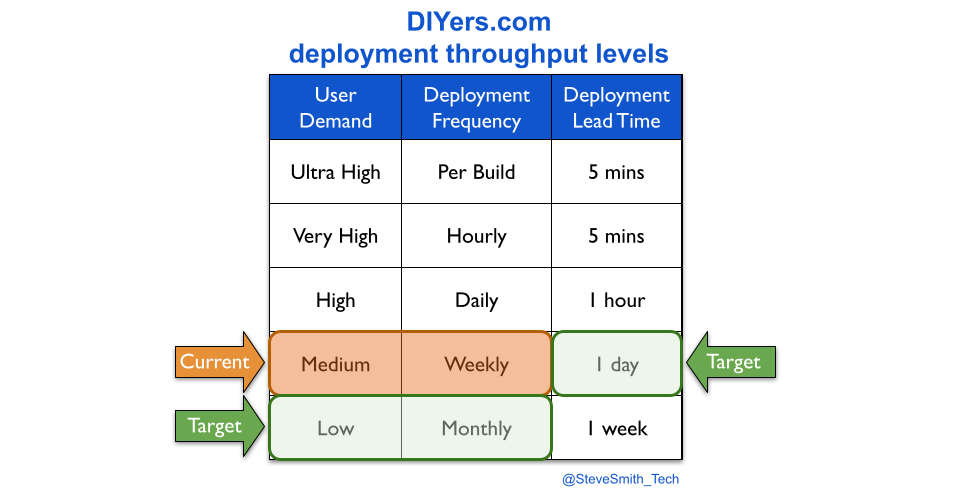
At DIYers.com, the higher operational costs were caused by a loss of protection. The drop from daily to monthly deployments was accompanied by a silent drop in deployment lead time from 1 hour to 1 week. This created opportunities for quality and reliability problems to emerge, and operational costs to increase.
Maintenance mode increases financial exposure
Maintenance mode by an operations team increases financial exposure, because opportunity costs are constant, and unmanageable with long deployment lead times.
Opportunity costs are constant because user needs are unbounded. It is absurd to declare a digital service to be feature complete, because user demand does not magically stop when feature development is stopped. Opportunities to profit from satisfying user needs always exist in a market.
Maintenance mode is wholly ignorant of opportunity costs. It is an artificial construct, driven by fixed capex budgets. It is true that developing a digital service indefinitely leads to diminishing returns, and expected return on investment could be higher elsewhere. However, a binary decision to end all investment in a digital service squanders any future opportunities to proactively increase revenues.
Opportunity costs are unmanageable with long deployment times, because a market can move faster than an overworked operations team. The cost of delay can be enormous if days or weeks of effort are needed to build, test, and deploy. Critical opportunities can be missed, such as:
- Increasing revenues by building a few new features to satisfy a sudden, unforeseeable surge in user demand.
- Protecting revenues when a live defect is found, particularly in a key trading period like Black Friday.
- Protecting revenues, costs, and brand reputation when a zero day security vulnerability is discovered.
The log4shell security flaw left hundreds of millions of devices vulnerable to arbitrary code execution. It is easy to imagine operations teams worldwide, frantically trying to patch tens of different digital services they did not build themselves, in the face of long deployment lead times and the threat of serious reputational damage.
At DIYers.com, the lower customer revenues were caused by feature stagnation. The lack of funding for digital services meant customers became dissatisfied with the DIYers.com website, and many of them shopped on competitor websites instead.
Maintenance mode is best performed by product teams
Maintenance mode is best performed by product teams, because they are able to protect the financial exposure of digital services with minimal investment.
Maintenance mode makes sense, in the abstract. IT as a Cost Centre dictates there are only so many fixed capex budgets per year. In addition, sometimes a digital service lacks the user demand to justify continuing with a dedicated product team. Problems with maintenance mode stem from implementation, not the idea. It can be successful with the following conditions:
- Be transparent. Communicate maintenance mode is a consequence of fixed capex budgets, and digital services do not have long-term funding without demonstrating product/market fit e.g. with Net Promoter Score.
- Transition from Ops Run It to You Build It You Run It. Identify any digital services owned by an operations team, and transition them to product teams for all build and run activities.
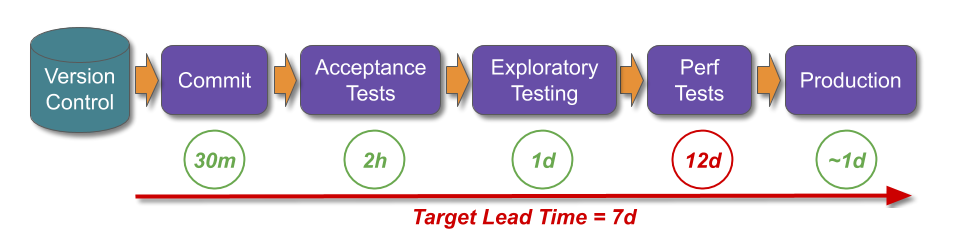
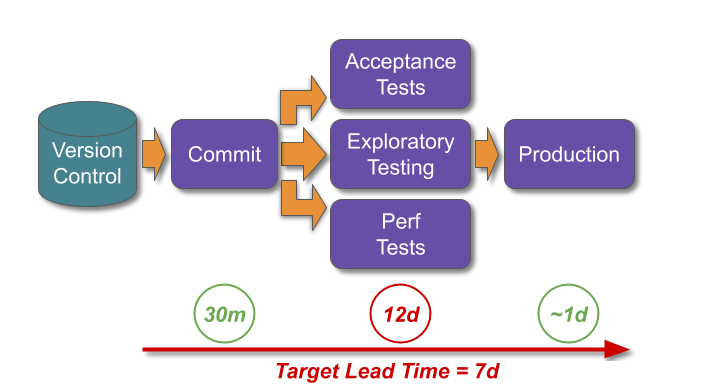
- Target the prior deployment lead time. Ensure maintenance mode has a target measure of less frequent deployments and the pre-transition deployment lead time.
- Make product managers accountable. Empower budget holders for product teams to transition digital services in and out of maintenance mode, based on business metrics and funding scenarios.
- Block transition routes to operations teams. Update service management policies to state only self-hosted COTS and back office foundational systems can be run by an operations team.
- Track financial exposure. Retain a sliver of funding for user research into fast moving opportunities, and monitor financial flows in a digital service during normal and abnormal operations.
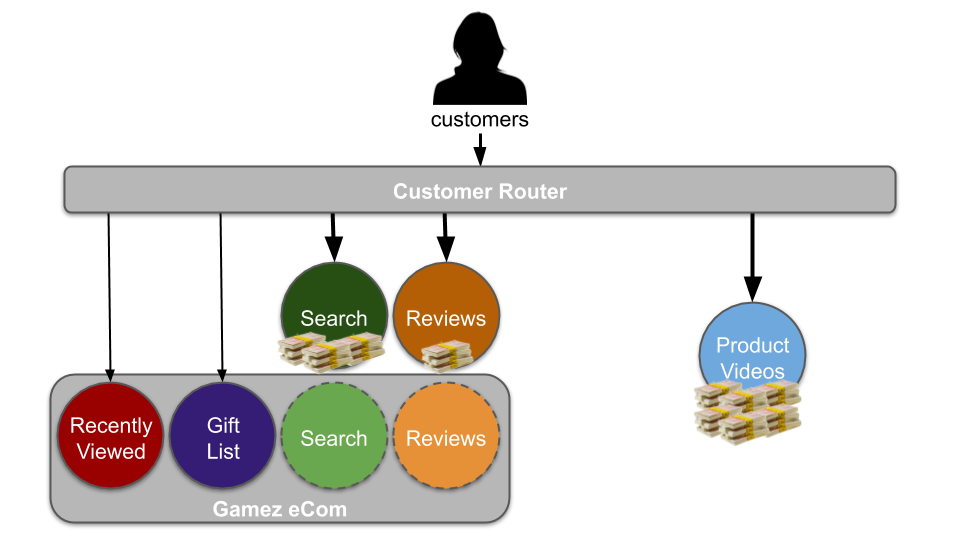
- Run maintenance mode as background tasks. Empower product teams to retain their live digital services, then transfer those services into sibling teams when funding dries up.
Maintenance mode works best when product teams run their own digital services. If a team has a live digital service #1 and new funding to develop digital service #2 in the same product domain, they monitor digital service #1 on a daily basis and deploy fixes and patches as necessary. This gives product teams a clear understanding of the pitfalls and responsibilities of running a digital service, and how to do better in the future.
If funding dictates a product team is disbanded or moved into a different product domain, any digital services owned by that team need to be transferred to a sibling team in the current product domain. This minimises the knowledge sharing burden and BAU maintenance workload for the new product team. It also protects deployment lead times for the existing digital services, and consequently their reliability and quality standards.
Maintenance mode by product teams requires funding for one permanent product team in each product domain. This drives some positive behaviours in organisational design. It encourages teams working in the same product domain to be sited in the same geographic region, which encourages a stronger culture based on a shared sense of identity. It also makes it easier to reawaken a digital service, as the learning curve is much smaller when sufficient user demand is found to justify further development.
Consider DIYers.com, if maintenance mode was by owned product teams. The organisation-wide target measures for maintenance mode would be expanded, from monthly deployments to monthly deployments performed in under a day.
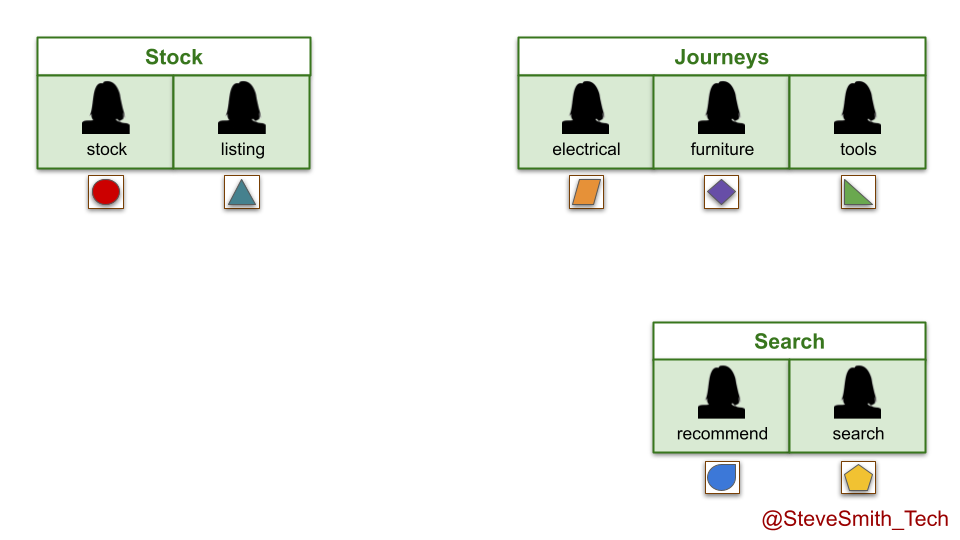
In the stock domain, the listings team is disbanded when funding ends. Its live service is moved into the stock team, and runs in the background indefinitely while development efforts continue on the stock service. The same happens in the search domain, with the recommend service moving into the search team.
In the journeys domain, the electricals and tools teams both run out of funding. Their live digital services are transferred into the furniture team, which is renamed the journeys team and made accountable for all live digital services there.
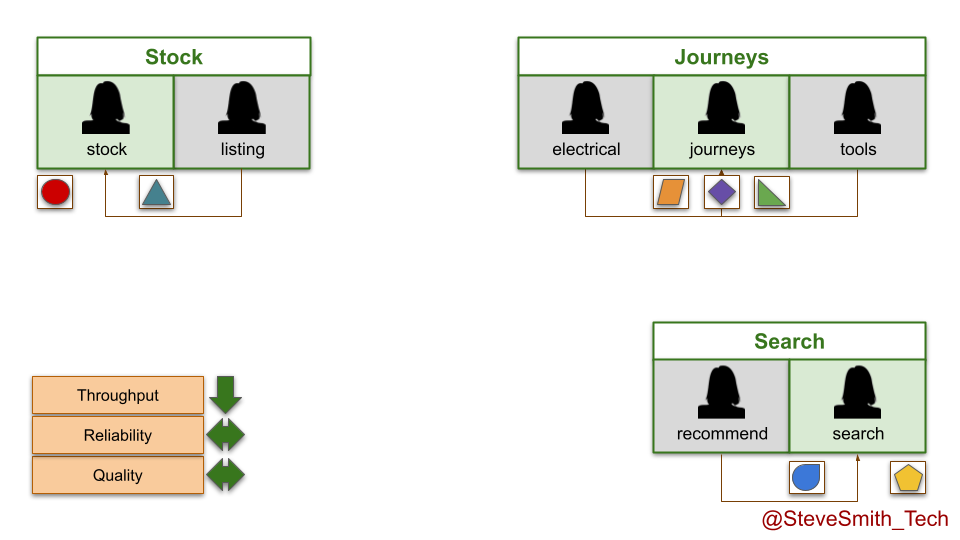
Of course, there is another option for maintenance mode by product teams. If a live digital service is no longer competitive in the marketplace and funding has expired, it can be deleted. That is the true definition of done.