Why do disparate Delivery and Operations teams result in long-term Discontinuous Delivery of inoperable applications?
This is part of the Who Runs It series.
Introduction
An organisation modelled on IT As A Cost Centre and Plan-Build-Run will have an Operations group in its IT department. Operations teams will be responsible for all Run activities, including deployments and production support for all applications. This can be referred to as You Build It Ops Run It. For example, consider a technology value stream comprising 1 development team in Delivery and an Application Operations team.
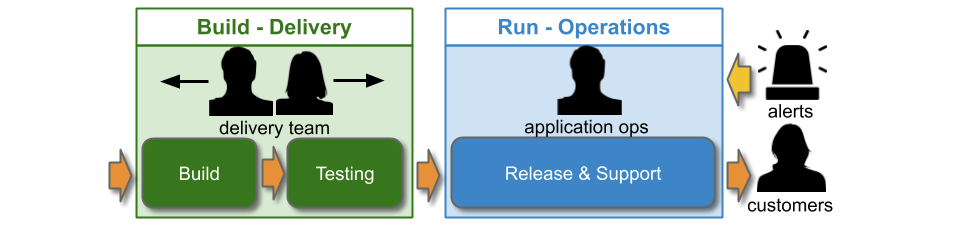
You Build It Ops Run It usually involves multi-level production support, in line with the ITIL v3 Service Operation standard:

The Service Desk will receive customer requests, and Operations Bridge will monitor dashboards and receive alerts. Both L1 teams will be trained to resolve simple technology issues, and to escalate more complicated tickets to L2. Application Operations will respond to incidents that require technology specialisation, and when necessary will escalate to an L3 Delivery team to contribute their expertise to an incident.
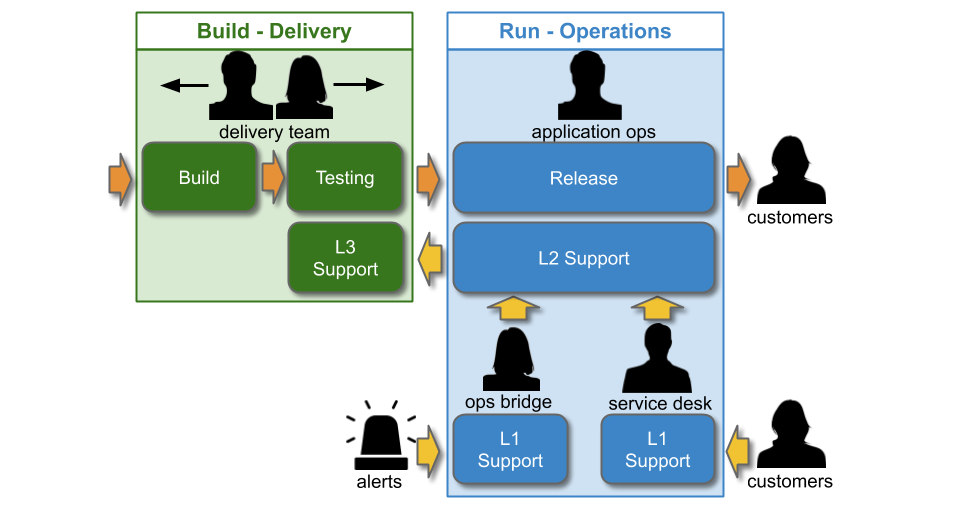
Cost accounting in IT As A Cost Centre creates a funding divide. A Delivery team will be budgeted under Capital Expenditure (CapEx), whereas Operations teams will be under Operational Expenditure (OpEx). An Operations team member will be paid a flat standby rate and a per-incident callout rate. A Delivery team member will not be paid for standby, and might be unofficially compensated per-callout with time off in lieu. Operations will be under continual pressure to reduce OpEx spending, and the Service Desk, Ops Bridge, and/or Application Operations might be outsourced to third party suppliers.
Discontinuous Delivery and inoperability
In ITSM and why three-tier support should be replaced with Swarming, Jon Hall argues “the current organizational structure of the vast majority of IT support organisations is fundamentally flawed”. Multi-level support in You Build It Ops Run It means non-trivial tickets will go from Service Desk or Ops Bridge through triage queues until the best-placed responder team is found. Repeated, unilateral ticket reassignments can occur between teams and individuals. Those handoffs can increase incident resolution time by hours, days, or even weeks. Rework can also be incurred as Application Operations introduce workarounds and data fixes, which await resolution in a Delivery backlog for months before prioritisation.
In addition, You Build It Ops Run It has major disadvantages for fast customer feedback and iterative product development:
- Long deployment lead times – handoffs with Application Operations will inflate lead times by hours or days
- High knowledge synchronisation costs – Delivery team application knowledge and Application Operations incident knowledge will be lost in handoffs, without substantial synchronisation efforts
- Focus on outputs – software will be built as an output, with little to no understanding of product hypotheses or customer outcomes
- Fragile architecture – applications will be architected without limits on failure blast radius, and exposed to high impact incidents
- Inadequate telemetry – dashboards and alerts created by Application Operations in isolation will only be able to use operational metrics
- Traffic ignorance – challenges involved in managing live traffic will be localised and unable to inform design decisions
- Restricted collaboration – Application Operations and Delivery teams will find joint incident response hard, due to differences in ways of working and tools, and lack of Delivery team access to production
- Unfair on-call expectations – Delivery team members will be expected to be available out of hours without compensation for the inconvenience, and disruption to their lives
These problems can be traced back to incentives. With Application Operations responsible for production support, a Delivery team will be unaware of or uninvolved in production incidents. Application Operations cannot build operability into applications they do not own, and a Delivery team will have little reason to prioritise operational features. As a result, inoperability is inevitable.
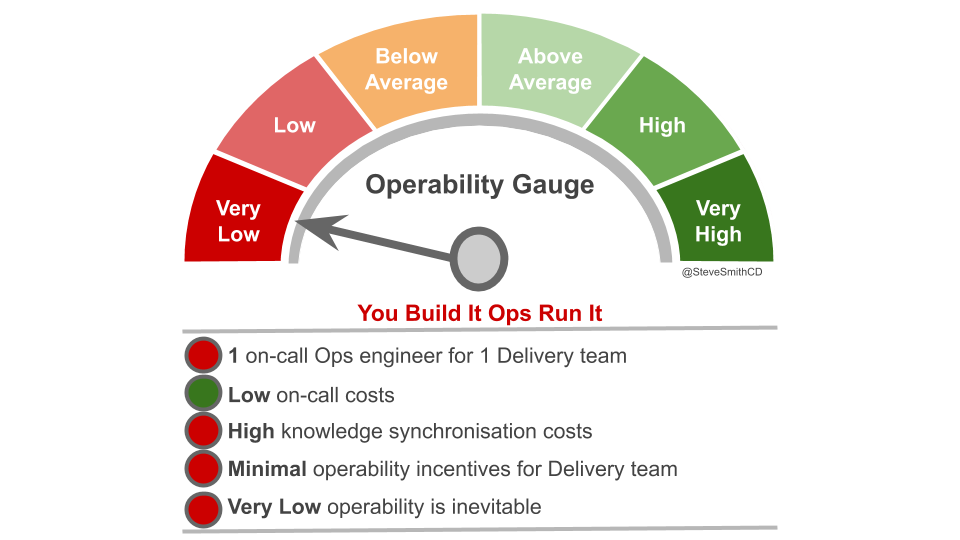
You Build It Ops Run It injects substantial delays and rework into a technology value stream. This is likely to constrain Continuous Delivery if product demand is high. If weekly or fewer deployments are sufficient to meet demand, then Continuous Delivery is possible. However, if product demand calls for more than weekly deployments then You Build It Ops Run It can only lead to Discontinuous Delivery.
The Who Runs It series:
- You Build It Ops Run It
- You Build It You Run It
- You Build It Ops It at scale
- You Build It You Run It at scale
- You Build It Ops Sometimes Run It
- Implementing You Build It You Run It at scale
- You Build It SRE Run It
Acknowledgements
Thanks to Thierry de Pauw.
Recent Comments