Why is a hybrid of You Build It Ops Run It and You Build It You Run It doomed to fail at scale?
This is part of the Who Runs It series.
Introduction
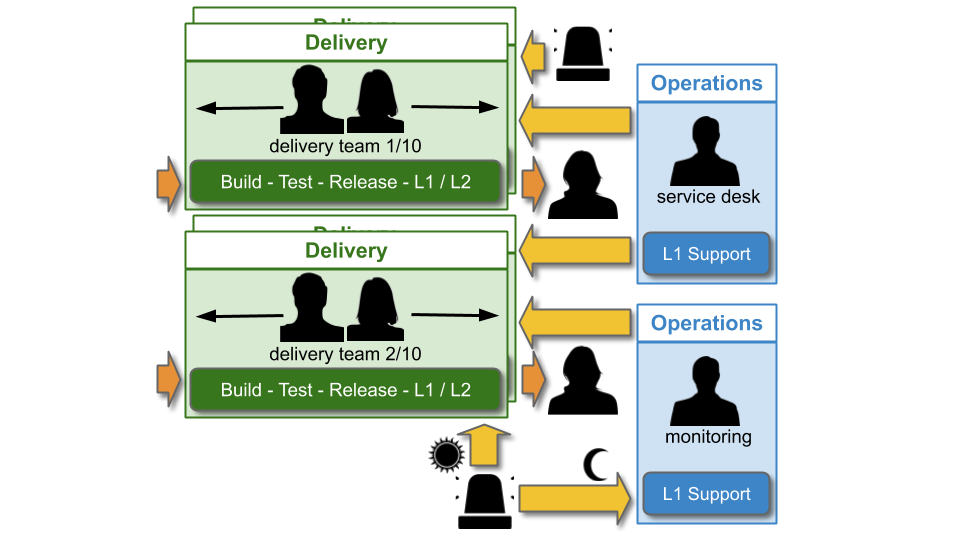
You Build It Ops Sometimes Run It refers to a mix of You Build It You Run It and You Build It Ops Run It. A minority of applications are supported by Delivery teams, whereas the majority are supported by a Monitoring team in Operations. This can be accomplished by splitting applications into higher and lower availability targets.
Some vendors may erroneously refer to this as Site Reliability Engineering (SRE). SRE refers to a central, on-call Delivery team supporting high availability, stable applications that meet stringent entry criteria. You Build It Ops Sometimes Run It is completely different to SRE, as the Monitoring team is disempowered and supports lower availability applications . The role and responsibilities of the Monitoring team are simply a hybrid of the Operations Bridge and Application Operations teams in the ITIL v3 Service Operation standard.

Out of hours, higher availability applications are supported by their L1 Delivery teams. Lower availability applications are supported by the L1 Monitoring team, who will receive alerts and respond to incidents. When necessary, the Monitoring team will escalate to L2 Delivery team members on best endeavours.
Support costs for Monitoring will be paid out of OpEx. Support costs for L1 Delivery teams should be paid out of CapEx, to ensure product managers balance desired availability with on-call costs. An L1 Delivery team member will be paid a flat standby rate, and a per-incident callout rate. An L2 Delivery team member will do best endeavours unpaid, and might be compensated per-callout with time off in lieu.
Inherited Discontinuous Delivery and inoperability
Proponents of You Build It Ops Sometimes Run It will argue it is a low cost, wafer thin support team that simply follows runbooks to resolve straightforward incidents, and Delivery teams can be called out when necessary. However, many of the disadvantages of You Build It Ops Run It are inherited:
- Long time to restore – support ticket handoffs between Monitoring and Delivery teams will delay availability restoration during complex incidents
- Very high knowledge synchronisation costs – application and incident knowledge will not be shared between multiple Delivery teams and the Monitoring team without significant coordination costs, such as handover meetings
- Slow operational improvements – problems and workarounds identified by Monitoring will languish in Delivery backlogs for weeks or months, building up application complexity for future incidents
- No focus on outcomes – applications will be built as outputs only, with little regard for product hypotheses
- Fragile architecture – failure scenarios will not be designed into applications, increasing failure blast radius
- Inadequate telemetry – dashboards and alerts by the Monitoring team will only be able to include low-level operational metrics
- Traffic ignorance – challenges in live traffic management will be localised, and unable to inform application design decisions
- Restricted collaboration – joint incident response between Monitoring and Delivery teams will be hampered by different ways of working and tools
- Unfair on-call expectations – Delivery team members will be expected to be available out of hours without compensation for the inconvenience, and disruption to their lives
The Delivery teams on-call for high availability applications will have strong operability incentives. However, with a Monitoring team responsible for a majority of applications, most Delivery teams will be unaware of or uninvolved in incidents. Those Delivery teams will have little reason to prioritise operational features, and the Monitoring team will be powerless to do so. Widespread inoperability, and an increased vulnerability to production incidents is unavoidable.
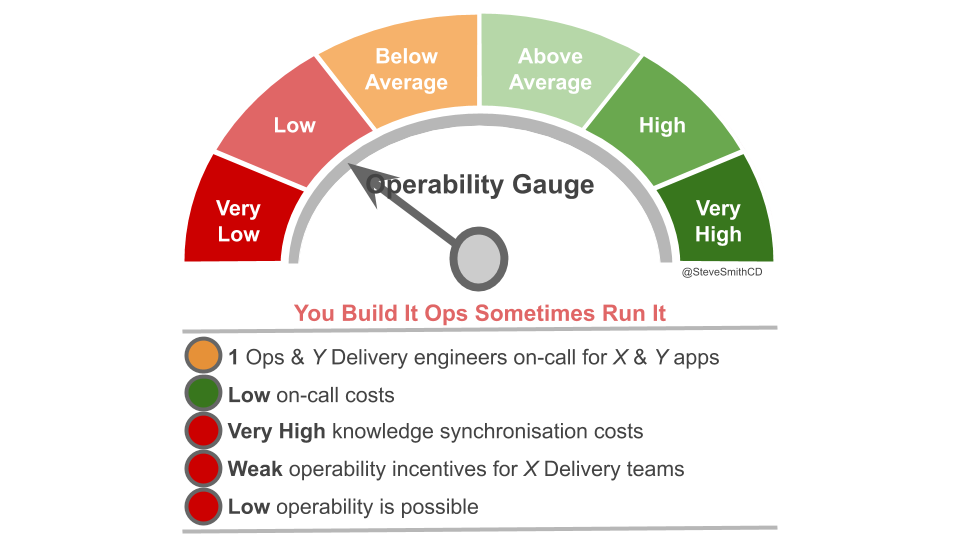
The notion of a wafer thin Monitoring team is fundamentally naive. If an IT department has an entrenched culture of You Build It Ops Run It At Scale, there will be a predisposition towards Operations support. Delivery teams on-call for higher availability applications will be viewed as a mere exception to the rule. Over time, there will be a drift to the Monitoring team taking over office hours support, and then higher availability applications out of hours. At that point, the Monitoring team is just another Application Operations team, and all the disadvantages of You Build It Ops Run It At Scale are assured.
The Who Runs It series:
- You Build It Ops Run It
- You Build It You Run It
- You Build It Ops Run It at scale
- You Build It You Run It at scale
- You Build It Ops Sometimes Run It
- Implementing You Build It You Run It at scale
- You Build It SRE Run It
Acknowledgements
Thanks to Thierry de Pauw.
Recent Comments