How can You Build It You Run It at scale be implemented? How can support costs be balanced with operational incentives, to ensure multiple teams can benefit from Continuous Delivery and operability at scale?
This is part of the Who Runs It series.
Introduction
Traditionally, an IT As A Cost Centre organisation with roots in Plan-Build-Run will have Delivery teams responsible for building applications, and Operations teams responsible for deployments and production support. You Build It You Run It at scale fundamentally changes that organisational model. It means 10+ Delivery teams are responsible for deploying and supporting their own 10+ applications.
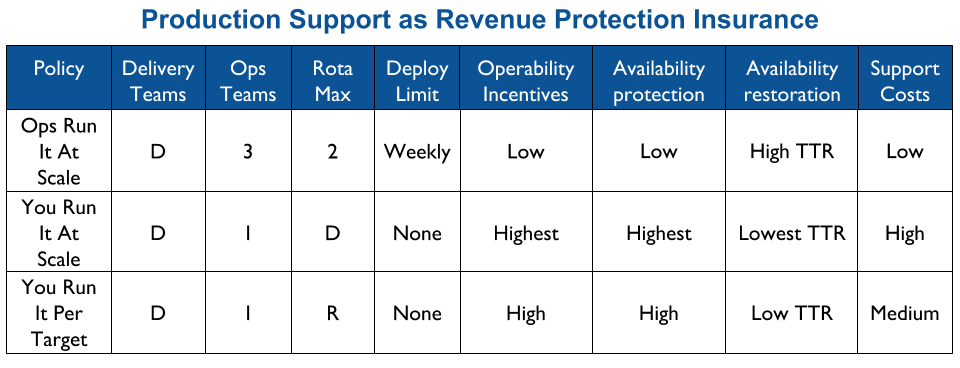
Applying You Build It You Run It at scale maximises the potential for fast deployment lead times, and fast incident resolution times across an IT department. It incentivises Delivery teams to increase operability via failure design, product telemetry, and cumulative learning. It is a revenue insurance policy, that offers high risk coverage at a high premium. This is in contrast to You Build It Ops Run It at scale, which offers much lower risk coverage at a lower premium.
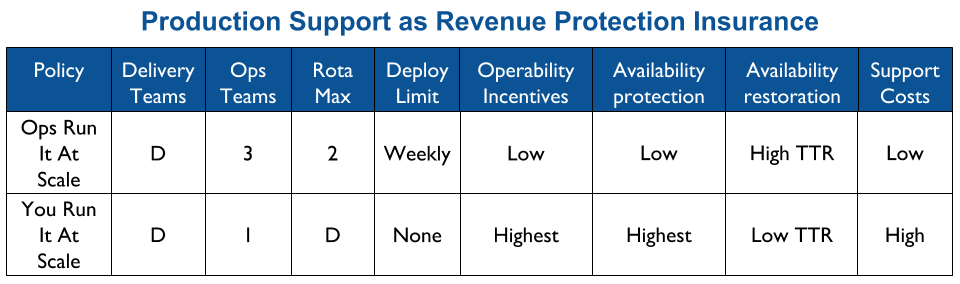
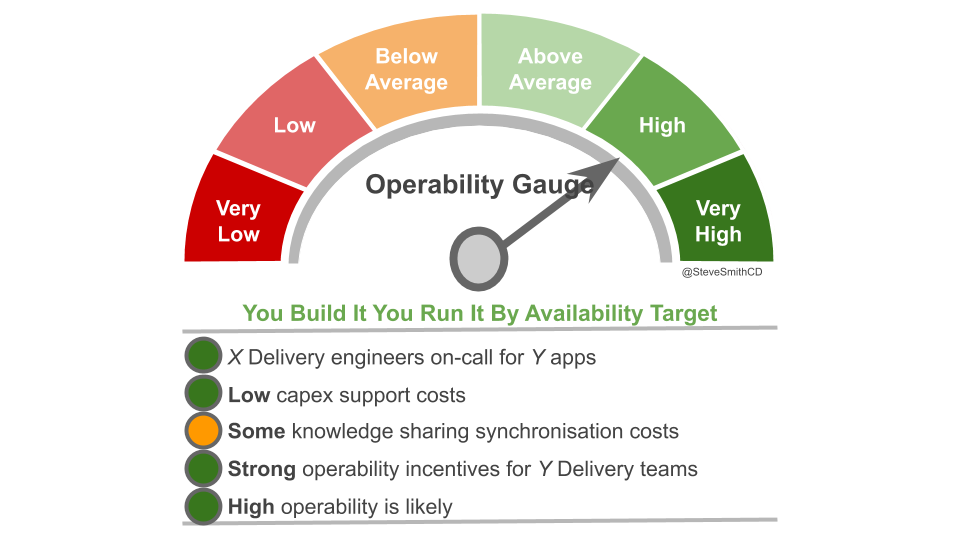
You Build It You Run It at scale can be intimidating. It has a higher engineering cost than You Build It Ops Run It at scale, as the table stakes are higher. These include a centralised catalogue of service ownership, detailed runbooks, on-call training, and global operability measures. It can also have support costs that are significantly higher than You Build It Ops Run It at scale.
At its extreme, You Build It You Run It at scale will have D support rotas for D Delivery teams. The out of hours support costs for D rotas will be greater than 2 rotas in You Build It Ops Run It at scale, unless Operations support is on an exorbitant third party contract. As a result You Build It Ops Run It at scale can be an attractive insurance policy, despite its severe disadvantages on risk coverage. This should not be surprising, as graceful extensibility trades off with robust optimality. As Mary Patterson et al stated in Resilience and Precarious Success, “fundamental goals (such as safety) tend to be sacrificed with increasing pressure to achieve acute goals (faster, better, and cheaper)”.
You Build It You Run It at scale does not have to mean 1 Delivery team on-call for every 1 application. It offers cost effectiveness as well as high risk coverage when support costs are balanced with operability incentives and risk of revenue loss. The challenge is to minimise standby costs without weakening operability incentives.
By availability target
The level of production support afforded to an application in You Build It You Run It at scale should be based on its availability target. In office hours, Delivery teams support their own applications, and halt any feature development to respond to an application alert. Out of hours, production support for an application is dictated by its availability target and rate of product demand.
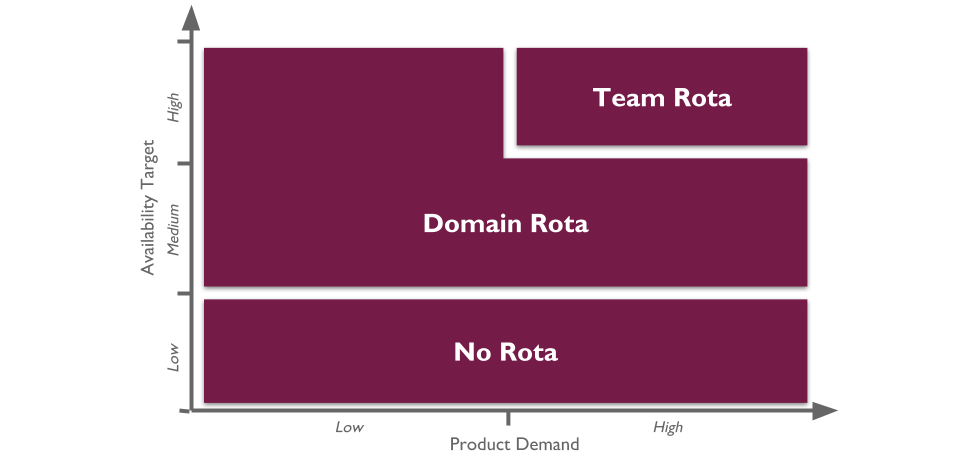
Applications with a low availability target have no out of hours support. This is low cost, easy to implement, and counter-intuitively does not sacrifice operability incentives. A Delivery team responsible for dealing with overnight incidents on the next working day will be incentivised to design an application that can gracefully degrade over a number of hours. No on-call is also fairer than best endeavours, as there is no expectation for Delivery team members to disrupt their personal lives without compensation.
Applications with a high availability target and a high rate of product demand each have their own team rota. A team rota is a single Delivery team member on-call for one or more applications from their team. This is classic You Build It You Run It, and produces the maximum operability incentives as the Delivery team have sole responsibility for their application. When product demand for an application is filled, it should be downgraded to a domain rota.
Applications with a medium availability target share a domain rota. A domain rota is a single Delivery team member on-call for a logical grouping of applications with an established affinity, from multiple Delivery teams.
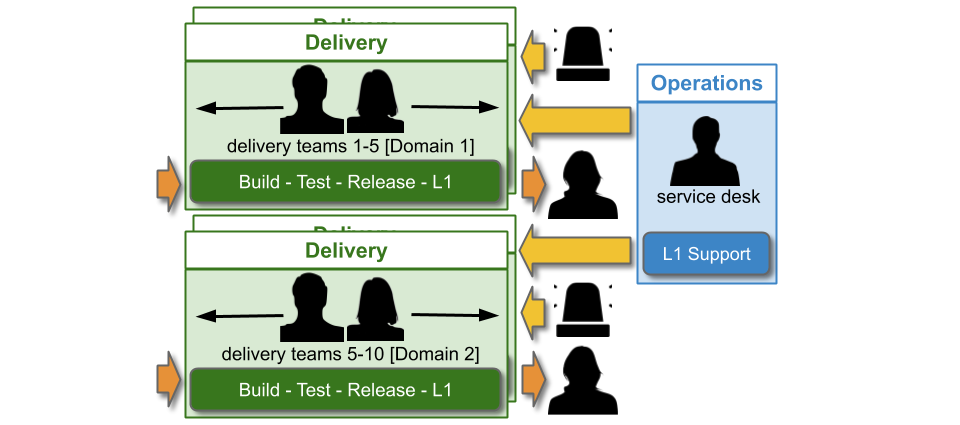
The domain construct should be as fine-grained and flexible as possible. It needs to minimise on-call cognitive load, simplify knowledge sharing between teams, and focus on organisational outcomes. The following constructs should be considered:
- Product domains – sibling teams should already be tied together by customer journeys and/or sales channels
- Architectural domains – sibling teams should already know how their applications fit into technology capabilities
The following constructs should be rejected:
- Geographic domains – per-location rotas for teams split between locations would produce a mishmash of applications, cross-cutting product and architectural boundaries and increasing on-call cognitive load
- Technology domains – per-tech rotas for teams split between frontend and backend technologies would completely lack a focus on organisational outcomes
A domain rota will create strong operability incentives for multiple Delivery teams, as they have a shared on-call responsibility for their applications. It is also cost effective as people on-call do not scale linearly with teams or applications. However, domain rotas can be challenging if knowledge sharing barriers exist, such as multiple teams in one domain with dissimilar engineering skills and/or technology choices. It is important to be pragmatic, and technology choices can be used as a tiebreaker on a product or architectural construct where necessary.
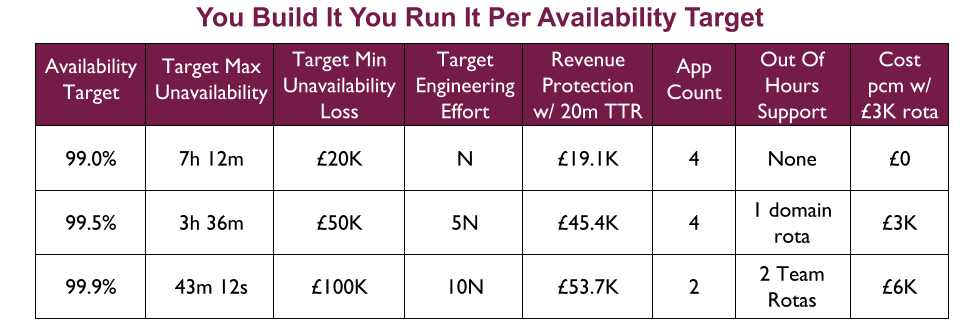
For example, a Fruits R Us organisation has 10 Delivery teams, each with 1 application. There are 3 availability targets of 99.0%, 99.5%, and 99.9%. An on-call rota is £3Kpcm in standby costs. If all 10 applications had their own rota, the support cost of £30Kpcm would likely be unacceptable.
Assume Fruits R Us managers assign minimum revenue losses of £20K, £50K, and £100K to their availability targets, and ask product owners to consider their minimum potential revenue losses per target. The Product and Checkout applications could lose £100K+ in 43 minutes, so they remain at 99.9% and have their own rotas. 4 applications in the same Fulfilment domain could lose £50K+ in 3 hours, so they are downgraded to 99.5% and share a Fulfilment domain rota across 4 teams. 4 applications in the Stock domain could lose £20K in 7 hours but no more, so they are downgraded to 99.0% with no out of hours on-call. This would result in a support cost of £9Kpcm while retaining strong operability incentives.
Optimising costs
A number of techniques can be used to optimise support costs for You Build It You Run It Per Availability Target:
- Recalibrate application availability targets. Application revenue analytics should regularly be analysed, and compared with the engineering time and on-call costs linked to an availability target. Where possible, availability targets should be downgraded. It should also be possible to upgrade a target, including fixed time windows for peak trading periods
- Minimise failure blast radius. Rigorous testing and deployment practices including Canary Deployments, Dark Launching, and Circuit Breakers should reduce the cost of application failure, and allow for availability targets to be gradually downgraded. These practices should be validated with automated and exploratory Chaos Engineering on a regular basis
- Align out of hours support with core trading hours. A majority of website revenue might occur in one timezone, and within core trading hours. In that scenario, production support hours could be redefined from 0000-2359 to 0600-2200 or similar. This could remove the need for out of hours support 2200-0600, and alerts would be investigated by Delivery teams on the following morning
- Automated, time-limited shuttering on failure. A majority of product owners might be satisfied with shuttering on failure out of hours, as opposed to application restoration. If so, an automated shutter with per-application user messaging could be activated on application failure, for a configurable time period out of hours. This could remove the need for out of hours support entirely, but would require a significant engineering investment upfront and operability incentives would need to be carefully considered
This list is not exhaustive. As with any other Continuous Delivery or operability practice, You Build It You Run It at scale should be founded upon the Improvement Kata. Ongoing experimentation is the key to success.
Production support is a revenue insurance policy, and implementing You Build It You Run It at scale is a constant balance between support costs with operability. You Build It You Run It Per Availability Target ensures on-call Delivery team members do not scale linearly with teams and/or applications, while trading away some operability incentives and some Time To Restore – but far less than You Build It Ops Run It at scale. Overall, You Build It You Run It Per Availability Target is an excellent starting point.
The Who Runs It series:
- You Build It Ops Run It
- You Build It You Run It
- You Build It Ops Run It at scale
- You Build It You Run It at scale
- You Build It Ops Sometimes Run It
- Implementing You Build It You Run It at scale
- You Build It SRE Run It
Acknowledgements
Thanks to Thierry de Pauw.