How does Site Reliability Engineering (SRE) approach production support? Why is it conditional, and how do error budgets try to avoid the inter-team conflicts of You Build It Ops Run It?
This is part of the Who Runs It series.
Introduction
The usual alternative to the You Build It Ops Run It production support method is You Build It You Run It. This means a development team is responsible for supporting its own services in production. It eliminates handoffs between developers and sysadmins, and maximises operability incentives for developers. It has the ability to unlock daily deployments, and improve production reliability.
A less common alternative to You Build It Ops Run It is a Site Reliability Engineering (SRE) on-call team. This can be referred to as You Build It SRE Run It. It is a conditional production support method, with an operations-focussed development team supporting critical services owned by other development teams.
SRE is a software engineering approach to IT operations. It started at Google in 2004, and was popularised by Betsey Byers et al in the 2016 book Site Reliability Engineering. In The SRE model, Jaana Dogan states ‘what makes Google SRE significantly different is not just their world-class expertise, but the fact that they are optional’. An SRE on-call team has strict entry and exit criteria for services. The process is:
- A development team does You Build It You Run It by default. Their service has a quarterly error budget.
- If user traffic becomes substantial, the development team requests SRE on-call assistance. Their service must pass a readiness review.
- If the review is successful, the development team shares the on-call rota with some SREs.
- If user traffic becomes critical, the development team hands over the on-call rota to a team of SREs.
- The SRE team automates operational tasks to improve service availability, latency, and performance. They monitor the service, and respond to any incidents.
- If the service is inside its error budget, the development team can launch new features without involving the SRE team.
- If the service is outside its error budget, the development team cannot launch new features until the SRE team is satisfied all errors are resolved.
- If the service is consistently outside its error budget, the SRE team hands the on-call rota back to the development team. The service reverts to You Build It You Run It.
In a startup with IT as a Business Differentiator, an SRE on-call team is a product team like any other development team. Those development teams might support their own services, or rely on the SRE on-call team.
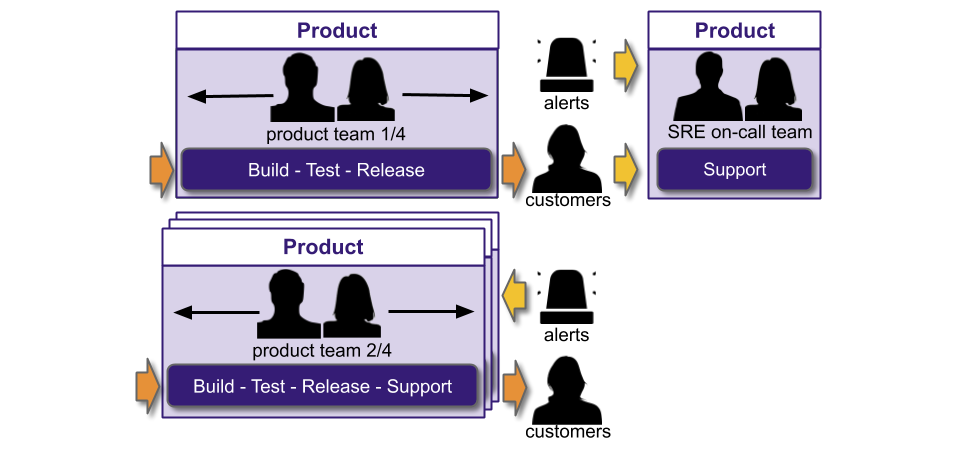
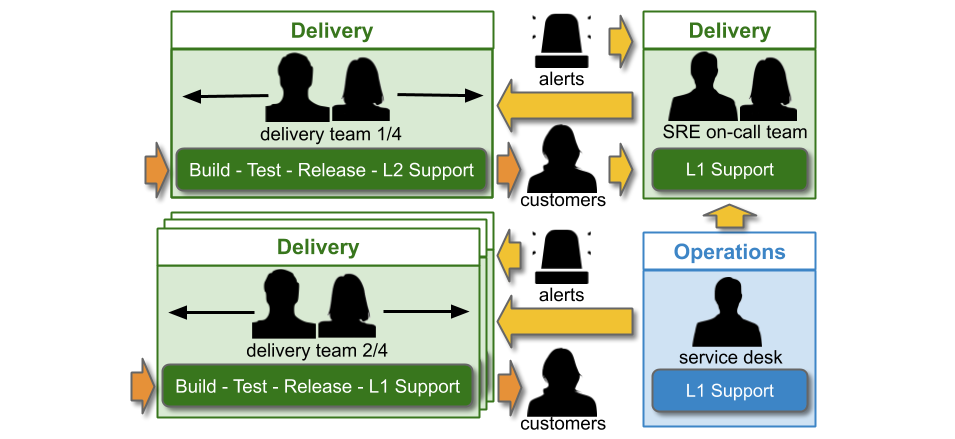
In an SME or enterprise organisation with IT as a Cost Centre, You Build It SRE Run It is very different. There are segregated Delivery and Operations functions, due to COBIT and Plan-Build-Run. The SRE on-call team could be within the Delivery function, and report into the Head of Delivery.
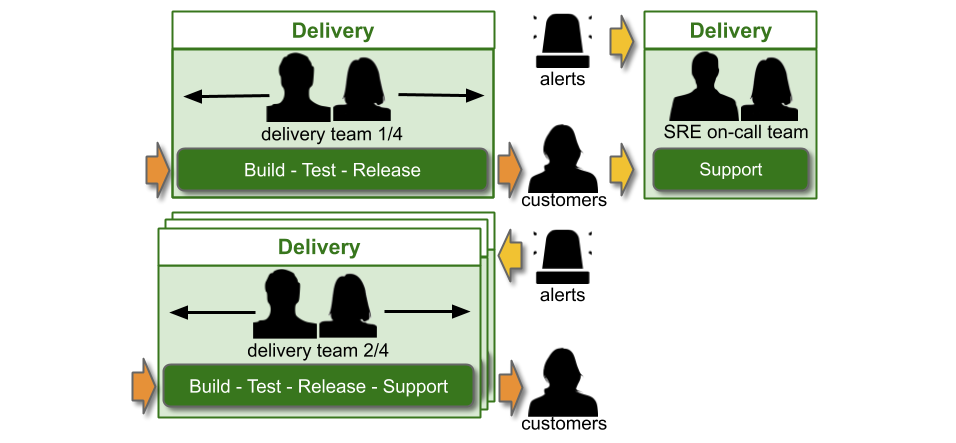
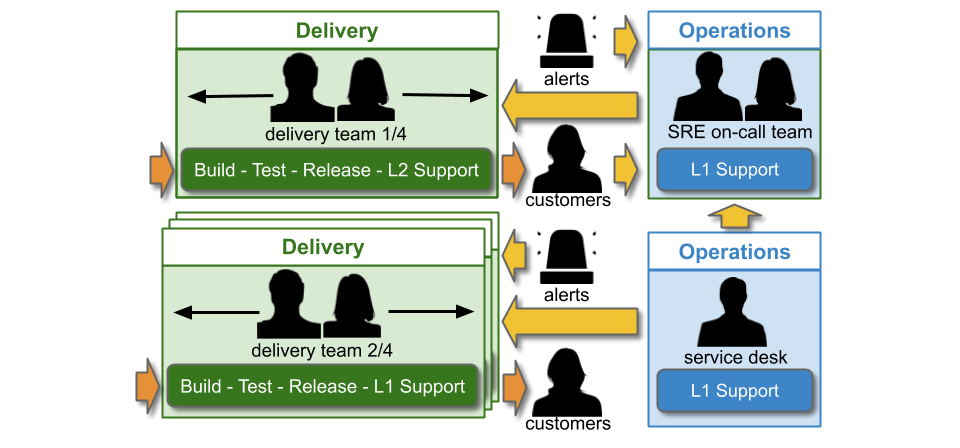
Alternatively, the SRE on-call team could be within the Operations function, and report into the Head of Operations.
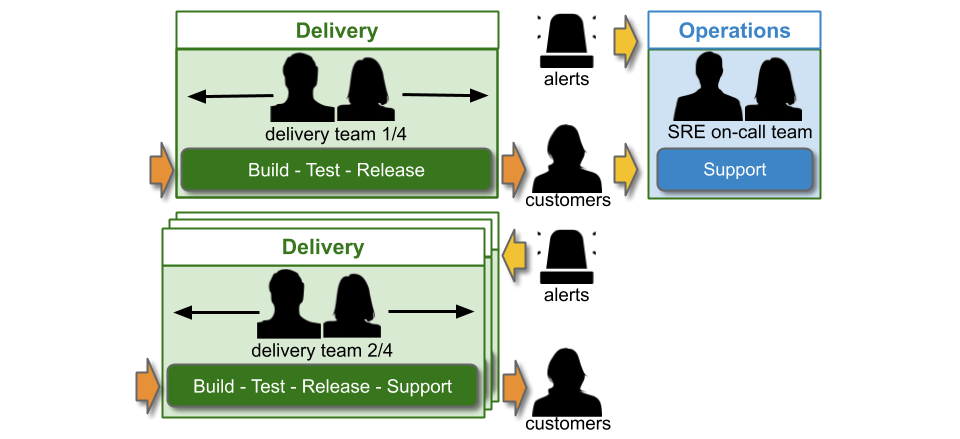
In IT as a Cost Centre, You Build It SRE Run It consists of single-level and multi-level support. An SRE on-call team participates in multiple support levels, with the Delivery teams that rely on them. A Delivery team supporting its own service has single level swarming.
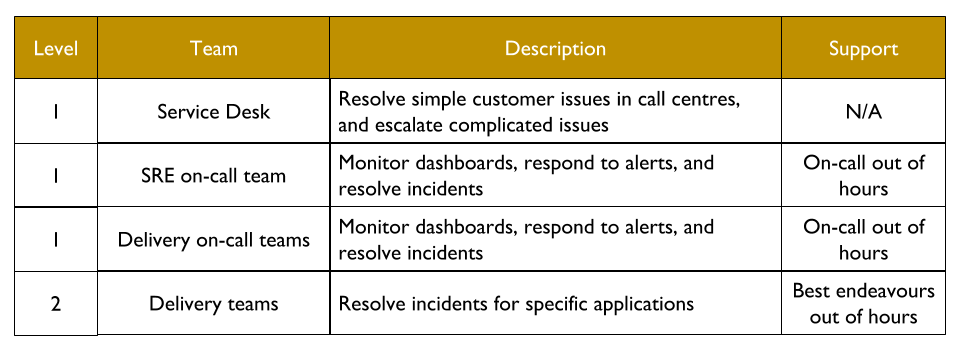
The Service Desk handles incoming customer requests. They can link a ticket in the incident management system to a specific web page or user journey, which reassigns the ticket to the correct on-call team. Delivery teams doing You Build It You Run It are L1 on-call for their own services. The SRE on-call team is L1 on-call for critical services, and when necessary they can escalate issues to the L2 Delivery teams building those services.
If the SRE on-call team is in Delivery, they will be funded by a capex Delivery budget. The Service Desk will be funded out of an Operations opex budget.
If the SRE on-call team is in Operations, they will be funded by an Operations opex budget like the Service Desk team.
Continuous Delivery and Operability
In You Build It SRE Run It, delivery teams on-call for their own production services experience the usual benefits of You Build It You Run It. Using an SRE on-call team and error budgets is a different way to prioritise service availability and incident resolution. Delivery teams reliant on an SRE on-call team are encouraged to limit their failure blast radius, to protect their error budget. The option for an SRE on-call team to hand back an on-call rota to a delivery team is a powerful reminder that operability needs a continual investment.
You Build It SRE Run It has these advantages for product development:
- Short deployment lead times. Lead times are minimised as there are no handoffs to the SRE on-call team.
- Focus on outcomes. Delivery teams are empowered to test product hypotheses and deliver outcomes.
- Short incident resolution times. Incident response from the SRE on-call team is rapid and effective.
- Adaptive architecture. Services will be architected for failure, including Circuit Breakers and Canary Deployments.
- Product telemetry. Delivery teams continually update dashboards and alerts for the SRE on-call team, according to the product context.
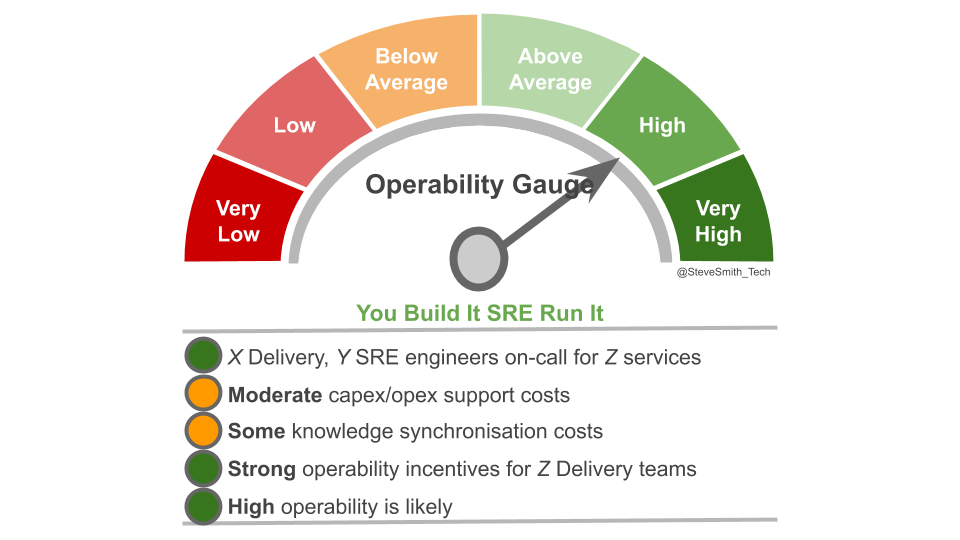
You Build It SRE Run It creates strong incentives for operability. Delivery teams on-call for their own services will have the maximum incentives to balance operational features with product features. There is 1 on-call engineer per team, at a low capex cost with no knowledge synchronisation costs between teams.
Delivery teams collaborating with an SRE on-call team do not have maximum operability incentives, as another team supports critical services with high levels of user traffic on their behalf. Theoretically, strong incentives remain due to error budgets. The ability of a delivery team to maintain a high deployment throughput without intervention depends on protecting service availability. This should ensure product managers prioritise operational features alongside product features. There is 1 on-call SRE for critical services at a capex or opex cost, and knowledge synchronisation costs between teams are inevitable.
Overinvesting in inapplicability
Production support is revenue insurance. At first glance, it might make sense to pay a premium for a high-powered SRE team to support highly available services with critical levels of user traffic. However, investing in an SRE on-call team should be questioned when its applicability to IT as a Cost Centre is so challenging.
Funding a SRE on-call team will be constrained by cost accounting. An SRE team in Delivery will have a capex budget, and undergo periodic funding renewals. An SRE team in Operations will have an opex budget, and endure regular pressure to find cost efficiencies. Either approach is at odds with a long term commitment to a large team of highly paid software engineers.
Error budgets are unlikely to magically solve the politics and bureaucracy that exists between Delivery teams and an SRE on-call team. Product managers, developers, and/or sysadmins might not agree on a service availability level, availability losses in recent incidents, and/or the remaining latitude in an error budget. A Head of Product might not accept an SRE block on deployments, when an error budget is lost. A Head of Delivery or Operations might not accept deployments at all hours, even with an error budget in place. In addition, an SRE on-call team might be unable to hand over an on-call rotation back to a Delivery team, if it was disbanded when its capex funding ended.
In Site Reliability Engineering, Betsey Byers et al describe near-universally applicable SRE practices, such as revenue-based availability targets and service level objectives. The authors also make the astute observation ‘an additional nine of reliability requires an order of magnitude improvement. A 99.99% service requires 10x more engineering effort than 99.9%, and 100x more than 99.0%. You Build It SRE Run It is not easily applied to IT as a Cost Centre, and it requires a sizable investment in culture, people, process, and tools. It is best suited to organisations with a website that genuinely requires 99.99% availability, and the maximum revenue loss in a large-scale failure could jeopardise the organisation itself. In a majority of scenarios, You Build It You Run It will be a simpler and more cost effective alternative.
Acknowledgements
Thanks to Thierry de Pauw.
The Who Runs It series:
- You Build It Ops Run It
- You Build It You Run It
- You Build It Ops Run It at scale
- You Build It You Run It at scale
- You Build It Ops Sometimes Run It
- Implementing You Build It You Run It at scale
- You Build It SRE Run It
Acknowledgements
Thanks to Thierry de Pauw.
Recent Comments