Why does Operations production support become less effective as Delivery teams and applications increase in scale?
This is part of the Who Runs It series.
Introduction
An IT As A Cost Centre organisation beholden to Plan-Build-Run will have a Delivery group responsible for building applications, and an Operations group responsible for deploying applications and production support. When there are 10+ Delivery teams and applications, this can be referred to as You Build It Ops Run It at scale. For example, imagine a single technology value stream used by 10 delivery teams, and each team builds a separate customer-facing application.
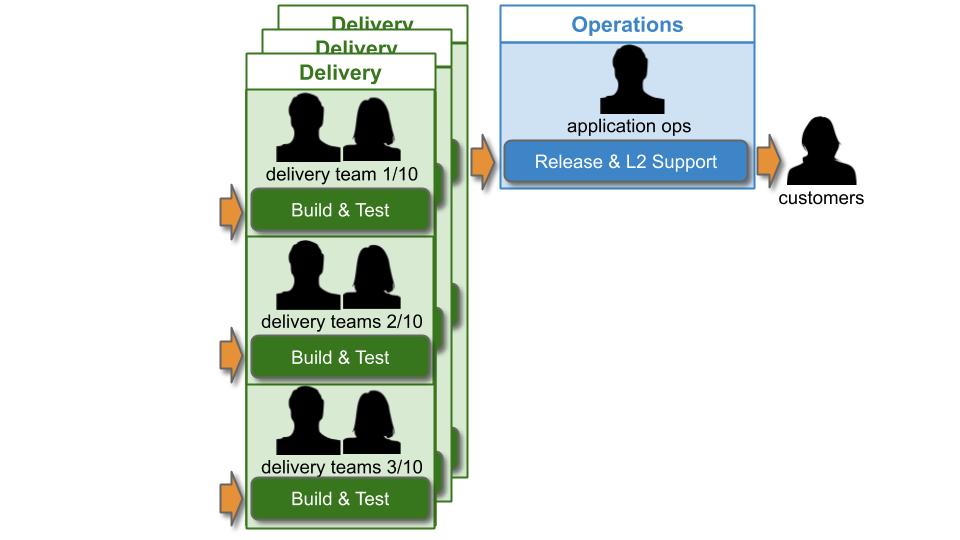
As with You Build It Ops Run It, there will be multi-level production support in accordance with the ITIL v3 Service Operation standard:
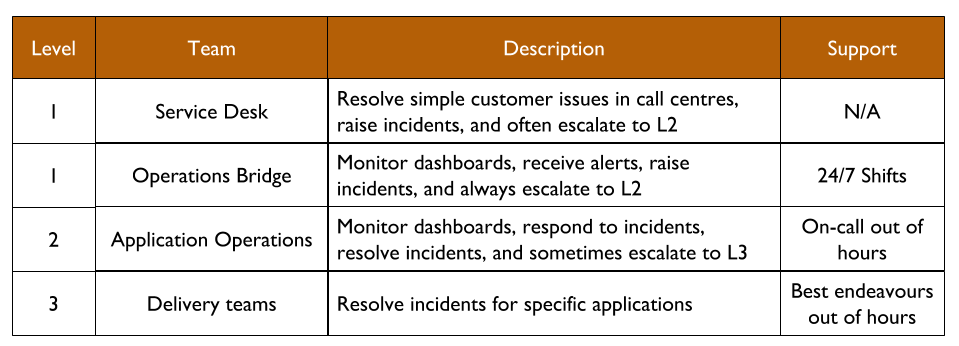
L1 and L2 Operations teams will be paid standby and callout costs out of Operational Expenditure (OpEx), and L3 Delivery team members on best endeavours are not paid. The key difference at scale is Operations workload. In particular, Application Operations will have to manage deployments and L2 incident response for 10+ applications. It will be extremely difficult for Application Operations to keep track of when a deployment is required, which alert corresponds to which application, and which Delivery team can help with a particular application.
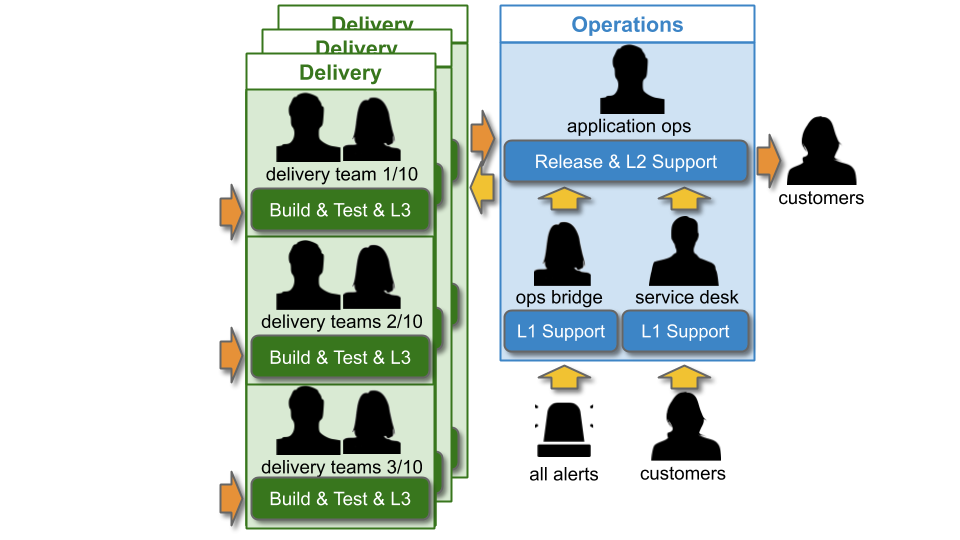
Discontinuous Delivery and inoperability
At scale, You Build It Ops Run It magnifies the problems with You Build Ops Run It, with a negative impact on both Continuous Delivery and operability:
- Long time to restore – support ticket handoffs between Ops Bridge, Application Operations, and multiple Delivery teams will delay availability restoration on failure
- Very high knowledge synchronisation costs – Application Operations will find it difficult to ingest knowledge of multiple applications and share incident knowledge with multiple Delivery teams
- No focus on customer outcomes – applications will be built as outputs only, with little time for product hypotheses
- Fragile architecture – failure scenarios will not be designed into user journeys and applications, increasing failure blast radius
- Inadequate telemetry – dashboards and alerts from Applications Operations will only be able to show low-level operational metrics
- Traffic ignorance – applications will be built with little knowledge of how traffic flows through different dependencies
- Restricted collaboration – incident response between Application Operations and multiple Delivery teams will be hampered by different ways of working
- Unfair on-call expectations – Delivery team members will be expected to do unpaid on-call out of hours
These problems will make it less likely that application availability targets can consistently be met, and will increase Time To Restore (TTR) on availability loss. Production incidents will be more frequent, and revenue impact will potentially be much greater. This is a direct result of the lack of operability incentives. Application Operations cannot build operability into 10+ applications they do not own. Delivery teams will have little reason to do so when they have little to no responsibility for incident response.
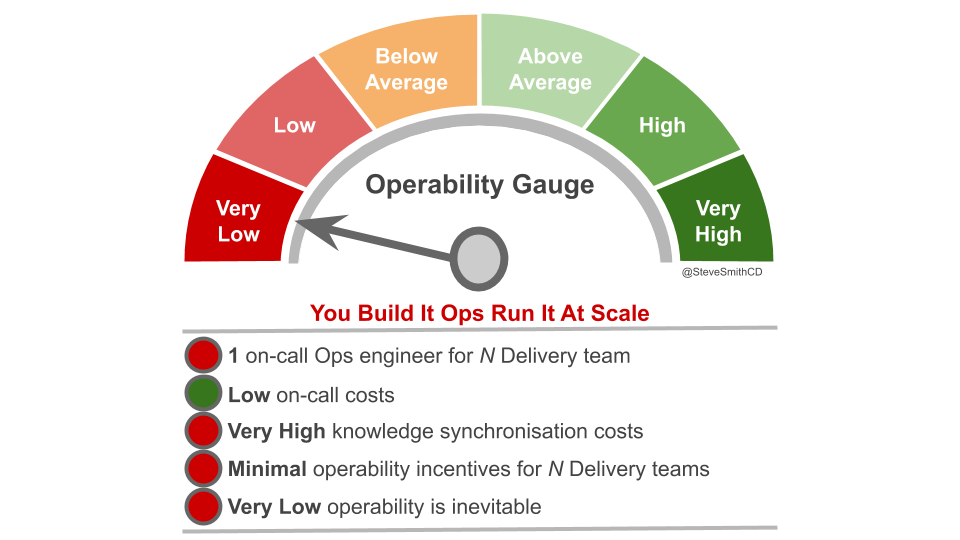
A Theory Of Constraints lens on Continuous Delivery shows that reducing rework and queue times is key to deployment throughput. With 10+ Delivery teams and applications the Application Operations workload will become intolerable, and team member burnout will be a real possibility. Queue time for deployments will mount up, and the countermeasure to release candidates blocking on Application Operations will be time-consuming management escalations. If product demand calls for more than weekly deployments, the rework and delays incurred in Application Operations will result in long-term Discontinuous Delivery.
The Who Runs It series
- You It Build It Ops Run It
- You Build It You Run It
- You Build It Ops Run It at scale
- You Build It You Run It at scale
- You Build It Ops Sometimes Run It
- Implementing You Build It You Run It at scale
- You Build IT SRE Run It
Acknowledgements
Thanks to Thierry de Pauw.
Recent Comments