Why do so many organisations optimise their IT delivery for robustness? What risk management practices are normally involved, and do their capabilities outweigh their costs?
This is part of the Resilience as a Continuous Delivery enabler series:
- The cost and theatre of Optimising For Robustness
- When Optimising For Robustness fails
- The value of Optimising For Resilience
- Resilience as a Continuous Delivery enabler
The tradition of robustness
As software continues to eat the world, organisations must position IT at the heart of their business strategy. The speed of IT delivery needs to be capable of satisfying customer demand, and at the same time the reliability of IT services must be ensured to protect daily business operations. In Practical Reliability Engineering, Patrick O’Connor and Andre Kleyner define reliability as “The probability that [a system] will perform a required function without failure under stated conditions for a stated period of time“, or as a function of Mean Time Between Failures (MTBF) and Mean Time To Repair (MTTR). When an organisation has unreliable IT services its business operations are left vulnerable to IT outages, and the cost of downtime could prove ruinous if market conditions are unfavourable.
Many organisations have a lack of confidence in their IT services, and an ingrained fear of failure. There is often a simultaneous belief that failures are preventable, based on the assumption that IT services are predictable and failures are caused by isolated changes. In such circumstances an organisation will traditionally Optimise For Robustness. It will focus on maximising the ability of its IT services to “resist change without adapting [their] initial stable configuration“, by implicitly favouring a higher MTBF over a lower MTTR. It will use robustness-centric risk management practices in its technology value streams to reduce the risk of future failures, such as 1:
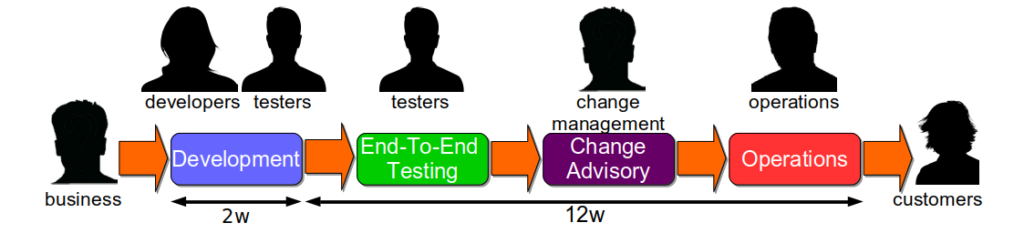
- End-To-End Testing to verify the functionality of a new service version against its unowned dependent services
- Change Advisory Boards to assess, prioritise, and approve the deployment of new service versions
- Change Freezes to restrict the deployment of new service versions for a period of time derived from market conditions
Consider a fictional Fruits-U-Like organisation, with development teams working to 2 week iterations and a quarterly release cycle. Fruits-U-Like has optimised itself for robustness ever since a 24 hour website outage 5 years ago. Each release goes through 6 weeks of End-To-End Testing with the testing team, a 2 week Change Advisory Board, and 1 week of preparation with the operations team. There are also several 4 week Change Freezes throughout the year, to coincide with marketing campaigns.
The costs and theatre of robustness
Robustness is a desirable capability of an IT service, but optimising for robustness invariably means spending too much time for too little risk reduction. The risk management practices used will be far more costly and less valuable than expected:
- End-To-End Testing incurs long test execution times and significant maintenance time, and test coverage will be low
- Change Advisory Boards involve extensive documentation and slow approval times, and deployments can still fail
- Change Freezes cause huge productivity impediments and delayed value-add, and production failures can still occur
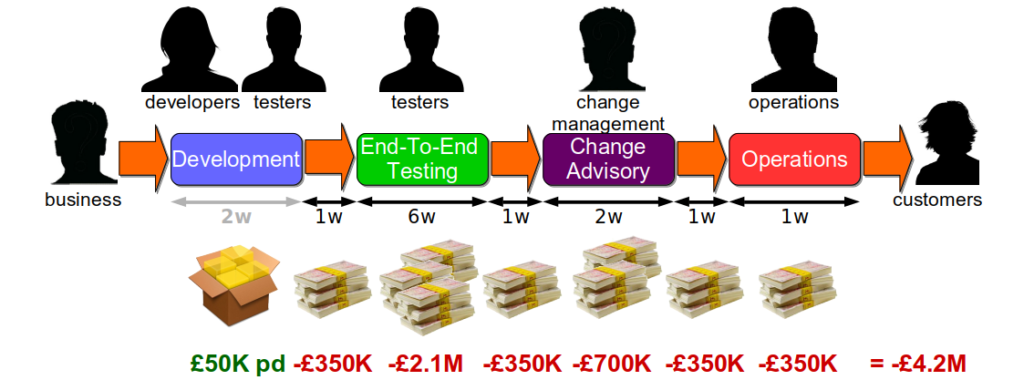
If the next Fruits-U-Like release was estimated to be worth £50K per day in new revenue, the 12 week lead time would create a total opportunity cost of £4.2 million. This would include the handover delays between the development, testing, and operations teams due to misaligned priorities. If a Change Freeze delayed the deployment by another 4 weeks the opportunity cost would increase to £5.6 million.
These risk management practices are what Jez Humble calls Risk Management Theatre. They are based on the misguided assumption that preventative controls on everyone will prevent anyone from making a mistake. Furthermore, they actually increase risk by ensuring a large batch size and a sizeable amount of requirements/technology changes per service version 2. They impede knowledge sharing, restrict situational awareness, create enormous opportunity costs, and doom organisations to a state of Discontinuous Delivery.
1 Other practices include manual regression testing, segregation of duties, and uptime incentives for operators
2 The Principles of Product Development Flow by Don Reinertsen describes in detail how large batch sizes increase risk
The Resilience As A Continuous Delivery Enabler series:
- The Cost And Theatre Of Optimising For Robustness
- When Optimising For Robustness Fails
- The Value Of Optimising For Resilience
- Resilience As A Continuous Delivery Enabler
Acknowledgements
This series is indebted to John Allspaw and Dave Snowden for their respective work on Resilience Engineering and Cynefin.
Thanks to Beccy Stafford, Charles Kubicek, Chris O’Dell, Edd Grant, Daniel Mitchell, Martin Jackson, and Thierry de Pauw for their feedback on this series.
Recent Comments