What does it mean to optimise for resilience? Why is resilience so valuable to an organisation, and how can operability contribute to the adaptive capacity of IT services?
This is part of the Resilience As A Continuous Delivery Enabler series:
- The cost and theatre of Optimising For Robustness
- When Optimising For Robustness fails
- The value of Optimising For Resilience
- Resilience as a Continuous Delivery enabler
The value of resilience
When an organisation wants to improve the reliability of its IT services it should Optimise For Resilience. Resilience is the ability to “absorb or avoid damage without suffering complete failure“, and it is immensely valuable in IT. A production environment is a complex system of partial failures in which the potential for catastrophe is ever-present, so an ability to resist failure is vital.
Resilience can be thought of as graceful extensibility. In Four Concepts for Resilience and their Implications for Systems Safety in the Face of Complexity, David Woods describes graceful extensibility as “the ability of a system to extend its capacity to adapt when surprise events challenge its boundaries“. The graceful extensibility of a system is derived from its adaptive capacity, which represents the capacity for adaptation when a failure occurs.
Erik Hollnagel et al break down resilience in Resilience Engineering In Practice using a conceptual model known as the Four Cornerstones of Resilience:
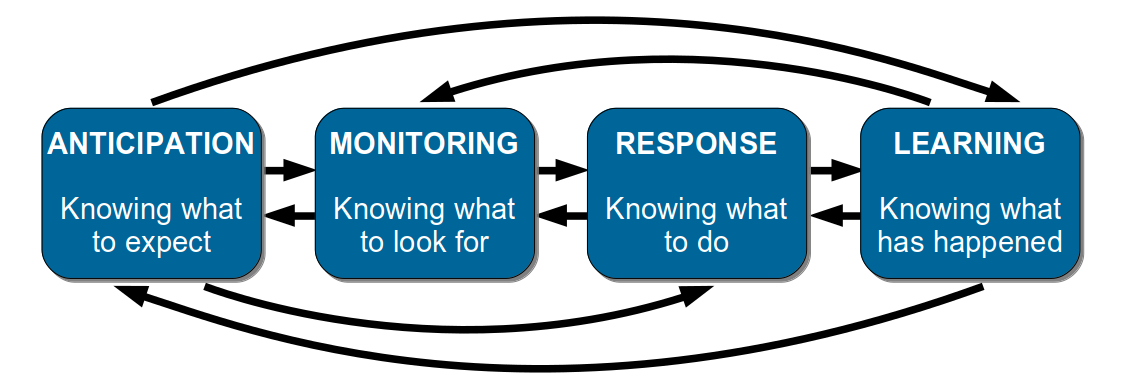
The cornerstones are non-linear, complementary aspects of resilience:
- Anticipation is knowing what to expect. This is imagining the potential for future failures, and mitigating for those scenarios in advance
- Monitoring is knowing what to look for. This is inspecting past and present operating conditions, and alerting when anomalies occur
- Response is knowing what to do. This is using guidelines, heuristics, improvisation skills, and situational awareness to mitigate a failure
- Learning is knowing what has happened. This is understanding the circumstances of a near-miss or failure, and sharing the observations
Creating adaptive capacity with Operability
Optimising For Resilience means creating a production environment in which running IT services can gracefully extend to deal with the unpredictable behaviours, unexpected changes, and periods of failure that will inevitably occur. When a service has sufficient adaptive capacity the cost per unit time and duration of production failures can potentially be minimised, reducing the direct revenue costs and indirect opportunity costs caused by a failure.
The adaptive capacity of IT services can be increased by explicitly prioritising a lower Mean Time To Repair (MTTR) over a higher Mean Time Between Failures (MTTR). Some classes of failure should never occur, some failures are more costly than others, and safety-critical services should never have failures, but in general organisations should adhere to John Allspaw’s advice that “being able to recover quickly from failure is more important than having failures less often“.
A lower MTTR can be achieved by investing in the operability of IT services. Operability is defined as “the ability to keep a system in a safe and reliable functioning condition“, and is associated with a set of practices:
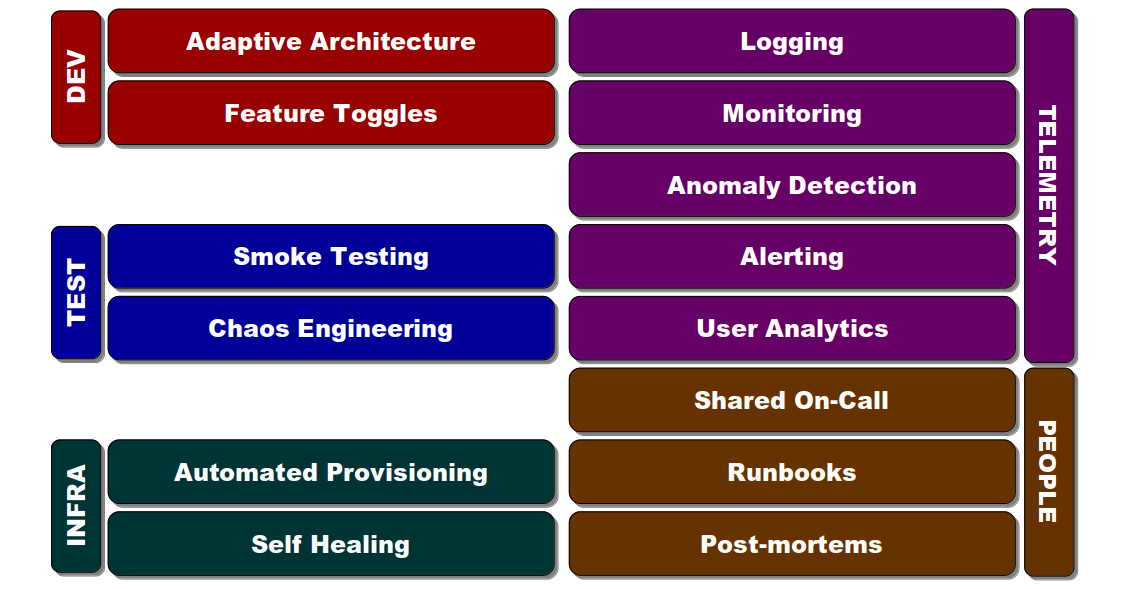
Each of these will increase the capacity of a service to adapt to unexpected operating conditions, and produce a more effective incident response:
- Development: an Adaptive Architecture limits the blast radius of a failure, and Feature Toggles allow features to be limited, tested in isolation, or turned off on failure
- Testing: Smoke Testing verifies service health, and Chaos Engineering uncovers latent failures in production
- Infrastructure: Automated Provisioning creates reproducible environments, and Self-Healing automatically restores failed service instances
- Telemetry: Logging radiates data on traffic, errors, latency, and saturation, and Monitoring visualises service metrics and events in a time series. Anomaly detection identifies events that breach normal operating conditions and Alerting notifies operators of abnormalities to act on. User analytics show success rates for user journeys
- People: Shared On-Call fosters a “You Build It, You Run It” culture and increases situational awareness, and Runbooks are a repository for operational knowledge. Blameless Post-Mortems uncover the multiple contributors to a near-miss or failure and suggest future preventative measures, while respecting the best efforts of individuals and the dangers of hindsight bias 1
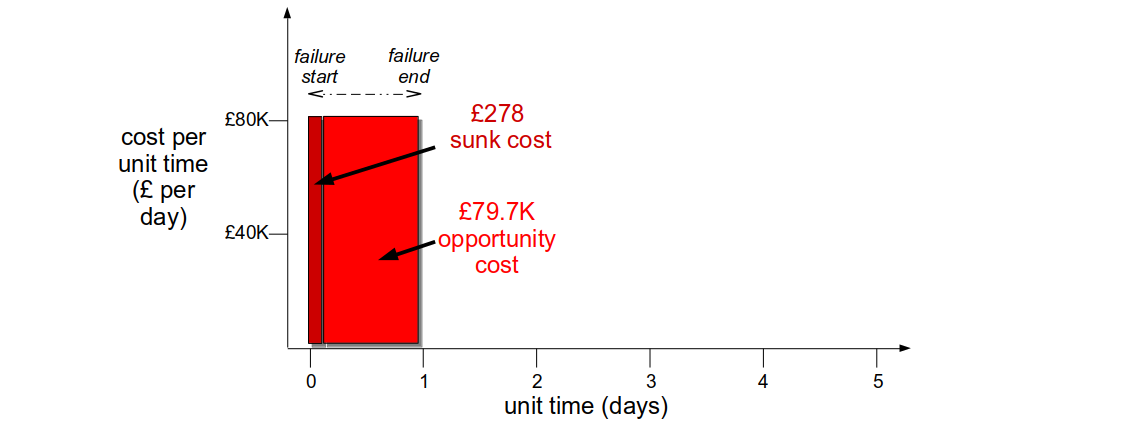
For example, incident response at Fruits-U-Like would be much improved if the organisation was optimising for resilience. Assume its third party registration service starts to struggle under load, new customers cannot checkout their purchases, and the failure cost per unit time is £80K per day. The checkout team would receive an automated alert for the failure, and their logging and monitoring dashboards would show a correlation between checkout and registration failures. The team would be able to triage a third party registration error within 5 minutes, and self-deploy an improvement to connection handling within a day. The failure would have a 1 day repair cost of £80K, with a detection sunk cost of £278 and a remediation opportunity cost of £79,722.
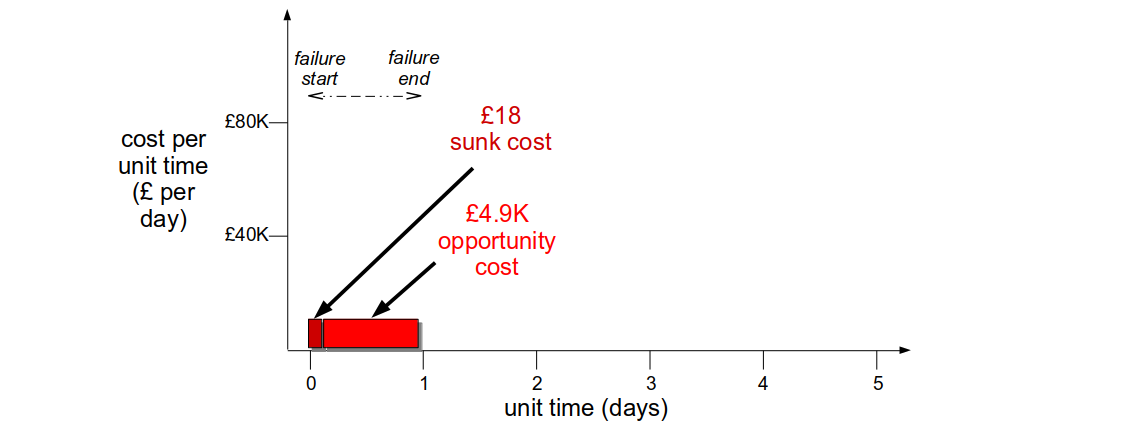
If the checkout team implemented an Adaptive Architecture they could combine a Circuit Breaker, a Bulkhead, and a Feature Toggle in anticipation of registration errors. If the registration service struggled under load the Circuit Breaker would regulate registration requests to allow a percentage to succeed, and the Bulkhead would warn the checkout frontend to skip registration for some customers. This approach would reduce the failure cost per unit time to a marketing opportunity cost of £5K a day. The checkout team would not receive an alert, but within minutes their dashboards would highlight registration errors and they could use a Feature Toggle to enable anonymous checkouts for new customers. This would allow them to deploy their connection handling fix within 3 hours with no customer impact. The result would be a 3 hour repair cost of £625, with a sunk cost of £18 and an opportunity cost of £607.
Optimising For Resilience sets the foundation for an organisation to act on market disruption and innovate. Once an organisation has the required level of graceful extensibility, it can continue to invest in its people and technology to achieve sustained adaptability. Sustained adaptability has been described by David Woods as “the ability to adapt to future surprises as conditions continue to evolve“, and can be thought of as innovation capability. An organisation that can quickly adapt to unexpected business events will hold a powerful First Mover Advantage over its competitors.
1 In How Complex Systems Fail, Richard Cook warns that “hindsight bias remains the primary obstacle to accident investigation. There is no such thing as a root cause in a complex production system, nor a blameworthy individual
The Resilience As A Continuous Delivery Enabler series:
- The Cost And Theatre Of Optimising For Robustness
- Responding To Failure When Optimising For Robustness
- The Value Of Optimising For Resilience
- Resilience As A Continuous Delivery Enabler
Acknowledgements
This series is indebted to John Allspaw and Dave Snowden for their respective work on Resilience Engineering and Cynefin.
Thanks to Beccy Stafford, Charles Kubicek, Chris O’Dell, Edd Grant, Daniel Mitchell, Martin Jackson, and Thierry de Pauw for their feedback on this series.
Recent Comments