Why is it wrong to assume failures are preventable in IT? Why does optimising for robustness leave organisations ill-equipped to deal with failure, and what are the usual outcomes?
This is part of the Resilience as a Continuous Delivery enabler series:
- The cost and theatre of Optimising For Robustness
- When Optimising For Robustness fails
- The value of Optimising For Resilience
- Resilience as a Continuous Delivery enabler
Underinvesting in operability
An organisation that optimises for robustness will attempt to maintain a production environment free from failure. This approach is based on the belief that failures in IT services are caused by isolated, faulty changes that are entirely preventable. A production environment is viewed as a set of homogeneous processes, with predictable interactions occurring in repeatable conditions. This matches the Cynefin definition of a complicated system, in which expert knowledge can be used to predict the cause and effect of events.
Optimising for robustness will inevitably lead to an overinvestment in pre-production risk management, and an underinvestment in production risk management. Symptoms of underinvestment include:
- Stagnant requirements – “non-functional” requirements are deprioritised for weeks or months at a time
- Snowflake infrastructure – environments are manually created and maintained in an unreproducible state
- Inadequate telemetry – logs and metrics are scarce, anomaly detection and alerting are manual, and user analytics lack insights
- Fragile architecture – services are coupled, service instances are stateful, failures are uncontained, and load vulnerabilities exist
- Insufficient training – operators are not given the necessary coaching, education, or guidance
This underinvestment creates an inoperable production environment, which makes it difficult for operators to keep IT services in a safe and reliable functioning condition. This will often be deemed acceptable, as production failures are expected to be rare.
The constancy of failure
A production environment of running IT services is not a complicated system. It is an intractable mass of heterogeneous processes, with unpredictable interactions occurring in unrepeatable conditions. It is a complex system of emergent behaviours, in which the cause and effect of an event can only be perceived in retrospect.
As Richard Cook explains in How Complex Systems Fail, “the complexity of these systems makes it impossible for them to run without multiple flaws being present“. A production environment always contains partial faults, and is constantly in a state of near-failure.
A failure will occur when unrelated faults unexpectedly coalesce such that one or more functions cannot succeed. Its revenue cost will be a function of cost per unit time and duration, with cost per unit time the economic impact and duration the time between start and end. Its opportunity costs will come from loss of customer confidence, and increased failure demand slowing feature development.
An organisation optimised for robustness will be ill-equipped to deal with a failure when it does occur. The inoperability of the production environment will produce a brittle incident response:
- Stagnant requirements and insufficient training will make it difficult to anticipate how services might fail
- Inadequate telemetry will impede the monitoring of normal versus abnormal operating conditions
- Snowflake infrastructure and a fragile architecture will prevent a rapid response to failure
For example, at Fruits-U-Like a third party registration service begins to suffer under load. The website rejects new customers on checkout, and a failure begins with a static cost per unit time of £80K per day. A lack of telemetry means the operations team cannot triage for 3 days. After triage an incident is assigned to the checkout team, who improve connection handling within a day. The Change Advisory Board agrees the fix can skip End-To-End Testing, and it is deployed the following day. The failure has a 5 day repair cost of £400K, with a detection sunk cost of £240K and a remediation opportunity cost of £160K.
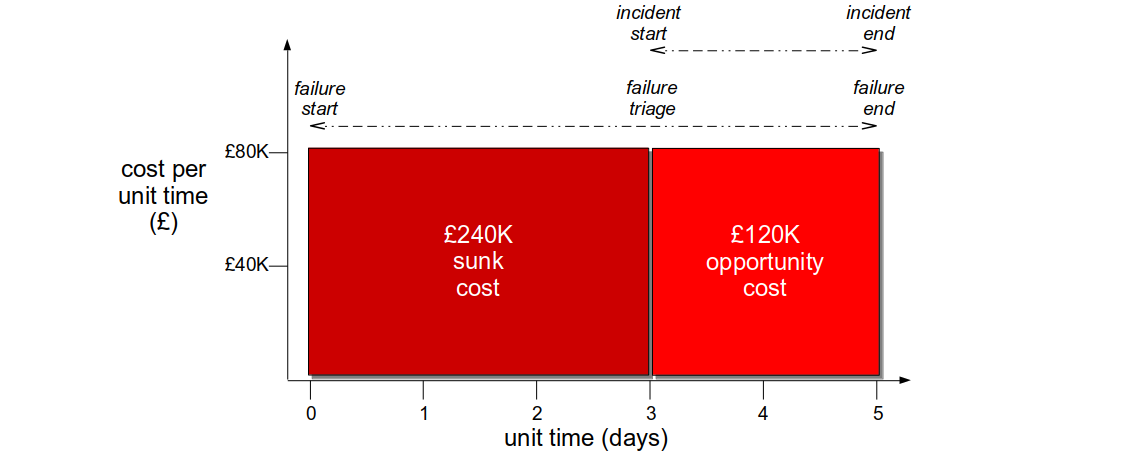
After a failure, the assumption that failures are caused by individuals will lead to a blame culture. There will be an attitude Sidney Dekker calls the Bad Apple Theory, in which production is considered absolutely reliable bar the actions of a few unreliable employees. The combination of the Bad Apple Theory and hindsight bias will create an oppressive culture of naming, blaming, and shaming the individuals involved. This discourages the sharing of operational knowledge and organisational learnings.
The Dual Value Streams countermeasure
An organisation optimised for robustness will be in a state of Discontinuous Delivery. Attempting to increase the Mean Time Between Failures (MTBF) with practices such as End-To-End Testing will increase feature lead times to the extent that business demand will be unsatisfiable. However, the rules for deploying a production fix will be very different.
When a production fix for a failure is available, people will share a sense of urgency. Regardless of how cost per unit time is estimated, there will be a recognition that a sunk cost has been incurred and an opportunity cost needs to be minimised. There will be a consensus that a different approach is required to avoid long feature lead times.
Dual Value Streams is a common countermeasure to failure when optimising for robustness. For each technology value stream in situ, there will actually be two different value streams. The feature value stream will retain all the advertised pre-production risk management practices, and will take weeks or months to complete. The fix value stream will strip out most if not all pre-production activities, and will take days to complete.
At Fruits-U-Like, that means a 12 week feature value stream from code to production and a 5 day fix value stream from failure start to end 2.
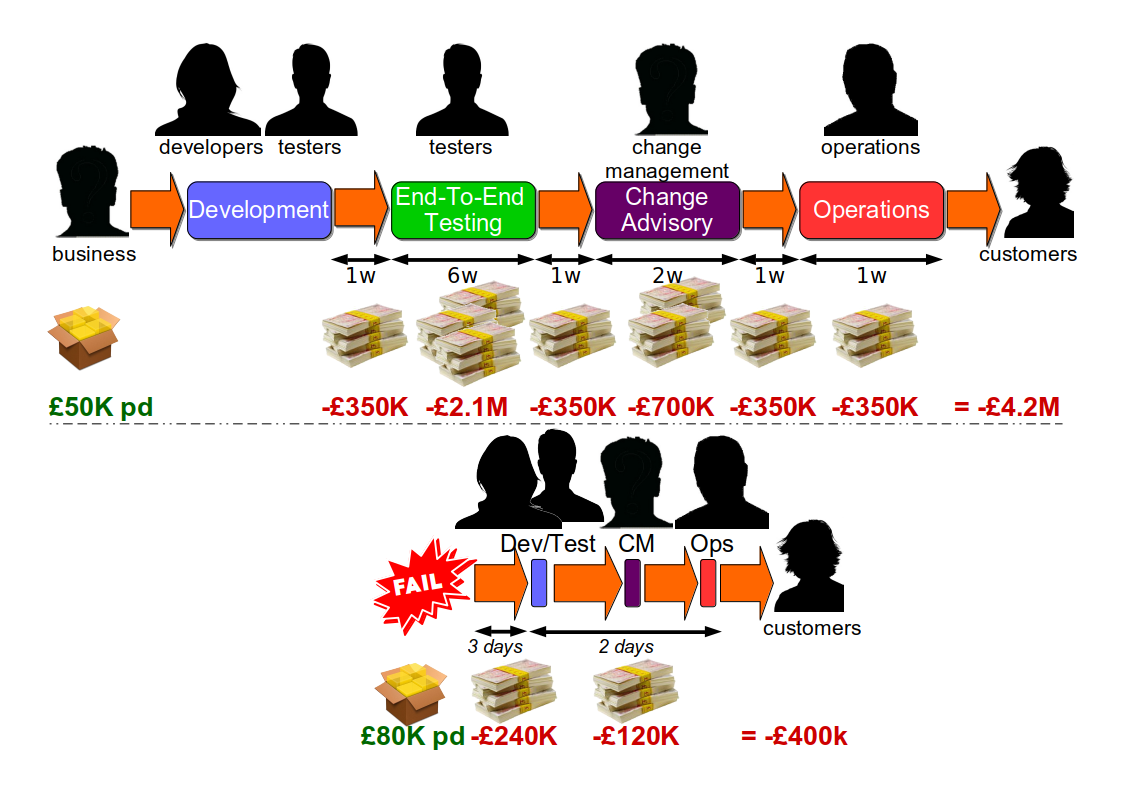
Dual Value Streams signify Discontinuous Delivery, but they also show potential for Continuous Delivery. The fix value stream indicates the lead times that can be accomplished when people have a shared sense of urgency, actively collaborate on releases, and omit the risk management theatre.
1 In The DevOps Handbook by Patrick Debois et al telemetry is defined as a logical grouping of logging, monitoring, anomaly detection, alerting, and user analytics
2 Measuring Continuous Delivery details why deployment failure recovery time should include development time and deployment lead time should not. Deployment failure recovery time is measured from failure start to failure end, while deployment lead time is measured from master commit to production deployment
The Resilience As A Continuous Delivery Enabler series:
- The Cost And Theatre Of Optimising For Robustness
- Responding To Failure When Optimising For Robustness
- The Value Of Optimising For Resilience
- Resilience As A Continuous Delivery Enabler
Acknowledgements
This series is indebted to John Allspaw and Dave Snowden for their respective work on Resilience Engineering and Cynefin.
Thanks to Beccy Stafford, Charles Kubicek, Chris O’Dell, Edd Grant, Daniel Mitchell, Martin Jackson, and Thierry de Pauw for their feedback on this series.
Recent Comments