The Version Control Strategies series
- Organisation antipattern – Release Feature Branching
- Organisation pattern – Trunk Based Development
- Organisation antipattern – Integration Feature Branching
- Organisation antipattern – Build Feature Branching
Integration Feature Branching is overly-costly and unpredictable
Integration Feature Branching is a version control strategy where developers commit their changes to a shared remote branch of a source code repository prior to the shared trunk. Integration Feature Branching is applicable to both centralised Version Control Systems (VCS) and Distributed Version Control Systems (DVCS), with multiple variants of increasing complexity:
- Type 1 – Integration branch and Trunk. This was originally used with VCSs such as Subversion and TFS
- Type 2 – Feature branches, an Integration branch, and Trunk. This is used today with DVCSs such as Git and Mercurial
- Type 3 – Feature release branches, feature branches, an Integration branch, and Trunk. This is advocated by Git Flow
In all Integration Feature Branching variants Trunk represents the latest production-ready state and Integration represents the latest completed changes ready for release. New features are developed on Integration (Type 1), or short-lived feature branches cut from Integration and merged back into Integration on completion (Types 2 and 3). When Integration contains a new feature it is merged into Trunk for release (Types 1 and 2), or a short-lived feature release branch cut from Integration and merged into Trunk and Integration on release (Type 3). When a production defect occurs it is fixed on a release branch cut from Trunk, then merged back to Integration (Types 1 and 2) or a feature release branch if one exists (Type 3).
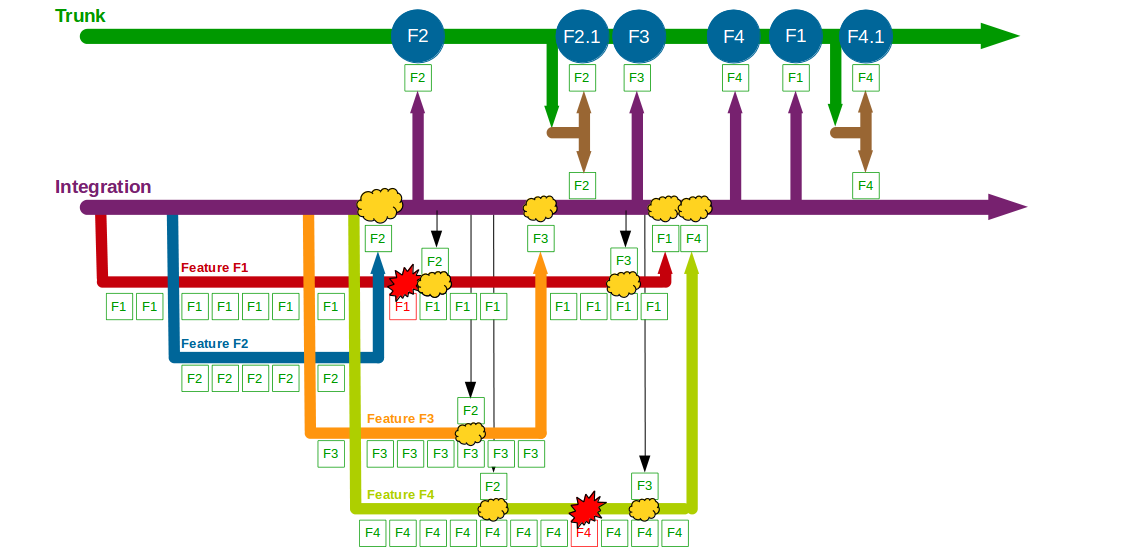
Consider an organisation that provides an online Company Accounts Service, with its codebase maintained by a team practising Type 2 Integration Feature Branching. Initially two features are requested – F1 Computations and F2 Write Offs – so F1 and F2 feature branches are cut from Integration and developers commit their changes to F1 and F2.
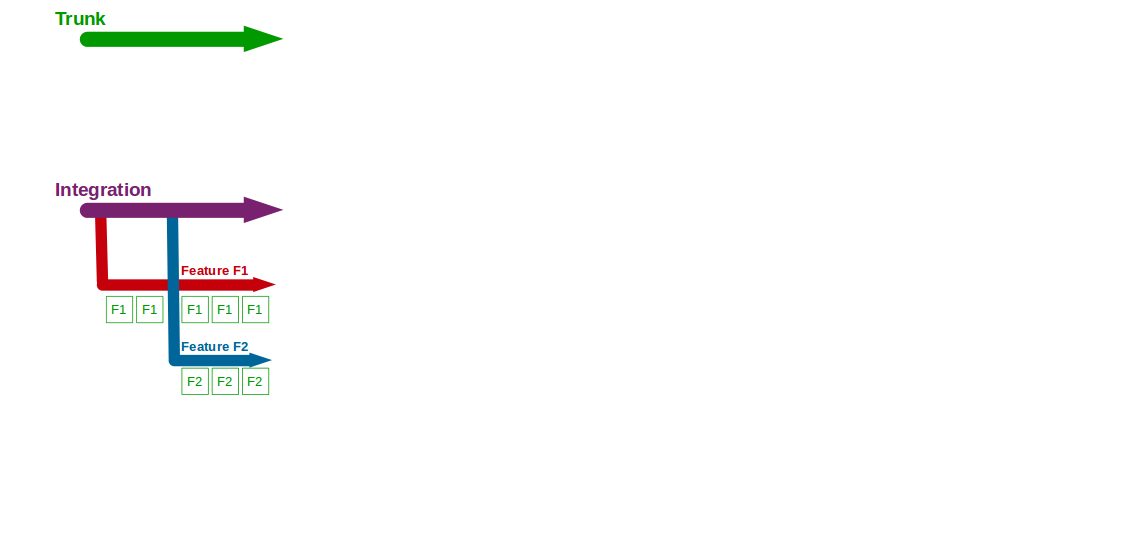
Two more features – F3 Bank Details and F4 Accounting Periods – then begin development, with F3 and F4 feature branches cut from Integration and developers committing to F3 and F4. F2 is completed and merged into Integration, and after testing it is merged into Trunk and regression tested before its production release. The F1 branch is briefly broken by a computations refactoring, with no impact on Integration.
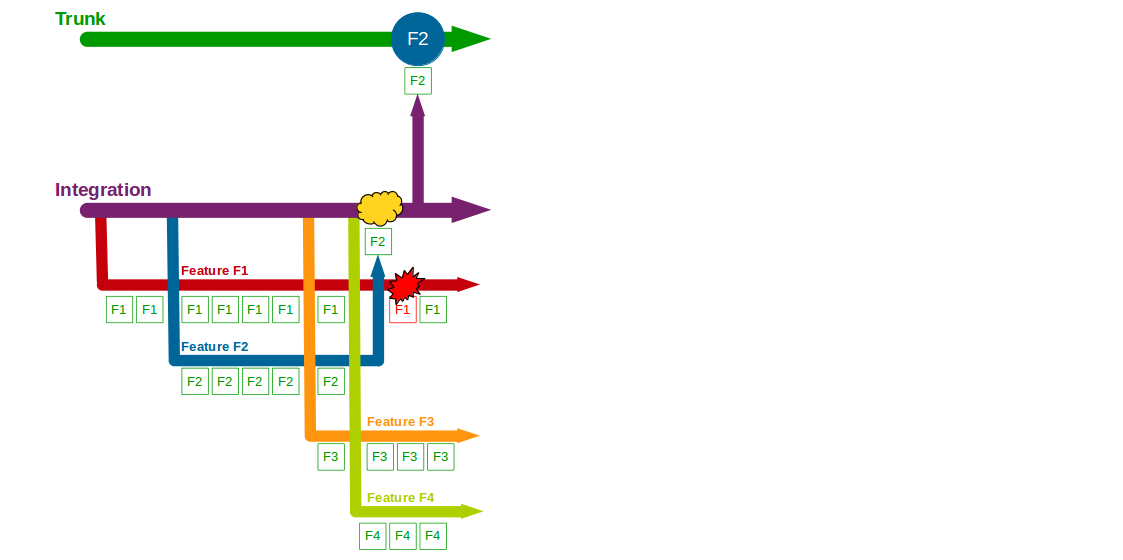
When F3 is completed it is merged into Integration + F2 and tested, but in the meantime a production defect is found in F2. A F2.1 fix is made on a F2.1 release branch cut from Trunk + F2, and after its release F2.1 is merged into and regression tested on both Integration + F2 + F3 and Trunk + F2. F3 is then merged into Trunk and regression tested, after which it is released into production. F1 continues development, and the F4 branch is temporarily broken by changes to the submissions system.
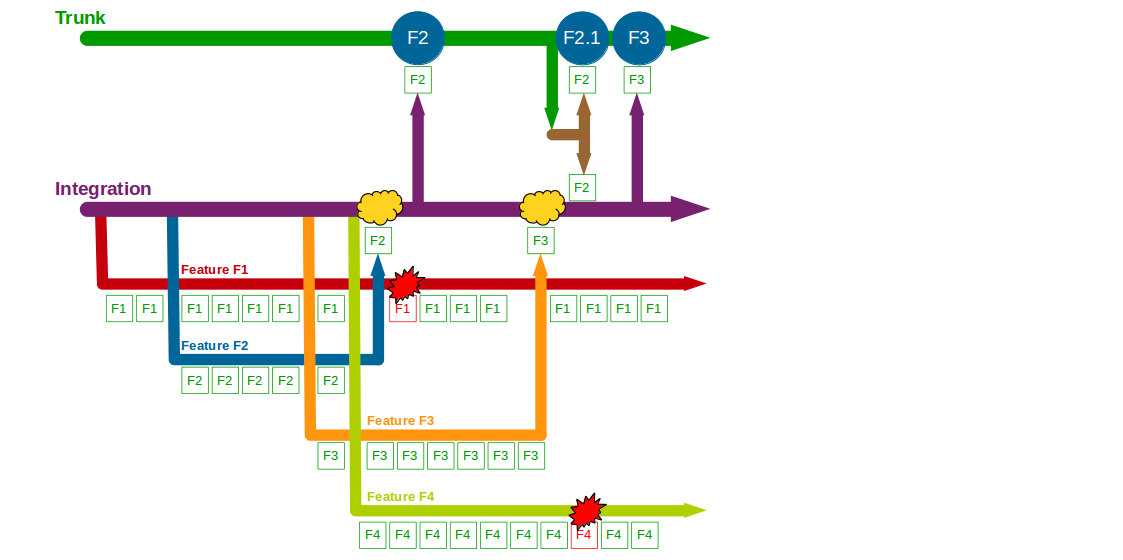
When F1 is completed and merged into Integration + F2 + F3 + F2.1 it is ready for production release, but a business decision is made to release F4 first. F4 is completed and after being merged into and tested on both Integration + F2 + F3 + F2.1 + F1 and Trunk + F2 + F3 + F2.1 it is released into production. Soon afterwards F1 is merged into and regression tested on Trunk + F2 + F2.1 + F3, then released into production. A production defect is found in F4, and a F4.1 fix is made on a release branch cut from Trunk + F2 + F2.1 + F3 + F4 + F1. Once F4.1 is released it is merged into and regression tested on both Integration + F2 + F3 + F2.1 + F1 + F4 and Trunk + F2 + F2.1 + F3 + F4 + F1.
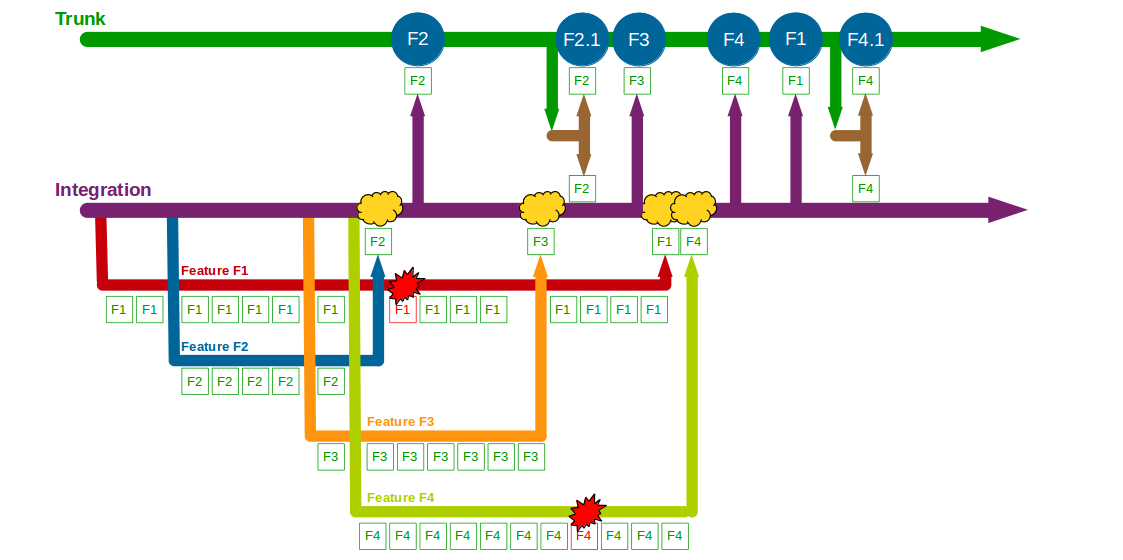
In this example F1, F2, F3, and F4 all enjoy uninterrupted development on their own feature branches. The use of an Integration branch reduces the complexity of each merge into Trunk, and allows the business stakeholders to re-schedule the F1 and F4 releases when circumstances change. However, the isolated development of F1, F2, F3, and F4 causes complex, time-consuming merges into Integration, and Trunk requires regression testing as it can differ from Integration – such as F4 being merged into Integration + F2 + F3 + F2.1 + F1 and Trunk + F2 + F2.1 + F3. The Company Accounts Service team might have used Promiscuous Integration on feature release to reduce the complexity of merging into Integration, but there would still be a need for regression testing on Trunk.
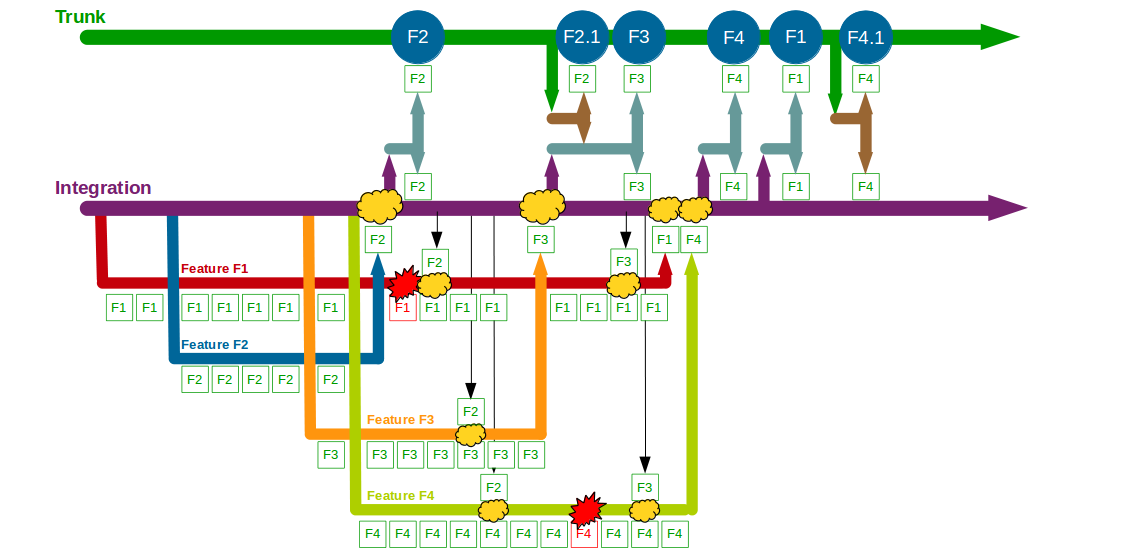
If the Company Accounts Service team used Type 3 Integration Feature Branching the use of feature release branches between Integration and Trunk could reduce the complexity of merging into Trunk, but regression testing would still be required on Trunk to garner confidence in a production release. Type 3 Integration Feature Branching also makes the version control strategy more convoluted for developers, as highlighted by Adam Ruka criticising Git Flow’s ability to “create more useless merge commits that make your history even less readable, and add significant complexity to the workflow“.
The above example shows how Integration Feature Branching adds a costly, unpredictable phase into software development for little gain. The use of an Integration branch in Type 1 creates wasteful activities such as Integration merges and Trunk regression testing, which insert per-feature variability into delivery schedules. The use of feature branches in Type 2 discourages collaborative design and refactoring, leading to a gradual deterioration in codebase quality. The use of feature release branches in Type 3 lengthens feedback loops, increasing rework and lead times when defects occur.
Integration Feature Branching is entirely incompatible with Continuous Integration. Continuous Integration requires every team member to integrate and test their code on Trunk at least once a day in order to minimise feedback loops, and Integration Feature Branching is the polar opposite of this. While Integration Feature Branching can involve commits to Integration on a daily basis and a build server constantly verifying both Integration and Trunk integrity, it is vastly inferior to continuously integrating changes into Trunk. As observed by Dave Farley, “you must have a single shared picture of the state of the system… there is no point having a separate integration branch“.
Recent Comments