Continuous Delivery often leads to the discovery of suboptimal practices within an organisation, and the Release Testing antipattern is a common example. What is Release Testing, and why is it an example of Risk Management Theatre?
Pre-Agile Testing
“I was a principal test analyst. I worked in a separate testing team to the developers. I spent most of my time talking to them to understand their changes, and had to work long hours to do my testing” – Suzy
The traditional testing strategy of many IT organisations was predicated upon a misguided belief described by Elisabeth Hendrickson as “testers test, programmers code, and the separation of the two disciplines is important“. Segregated development and testing teams worked in sequential phases of the value stream, with each product increment handed over to the testers for a prolonged period of testing prior to sign-off.

This strategy was certainly capable of uncovering defects, but it also had a detrimental impact on lead times and quality. The handover period between development and testing inserted delays into the value stream, creating large feedback loops that increased rework. Furthermore, the segregation of development and testing implicitly assigned authority for changes to developers and responsibility for quality to testers. This disassociated developers from defect consequences and testers from business requirements, invariably resulting in higher defect counts and lower quality over time.
Agile Testing
“I was a product tester. I worked in an agile team with developers and a business analyst. I contributed to acceptance tests and did exploratory testing. I don’t miss the old ways” – Dwayne
The publication of the Agile Manifesto in 2001 led to a range of lightweight development processes that introduced a radically different testing approach. Agile methods advocate cross-functional teams of co-located developers and testers, in which testing is considered a continuous activity and there is a shared commitment to product quality.
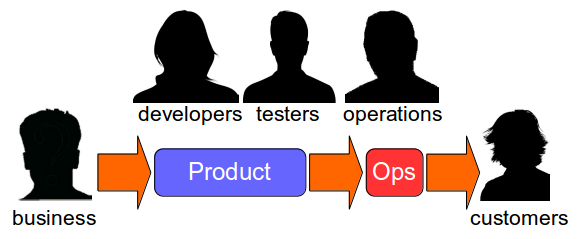
In an agile team developers and testers collaborate on practices such as Test Driven Development and Acceptance Test Driven Development in accordance with the Test Pyramid strategy, which recommends a large number of automated unit and acceptance tests in proportion to a small number of automated end-to-end and manual tests.
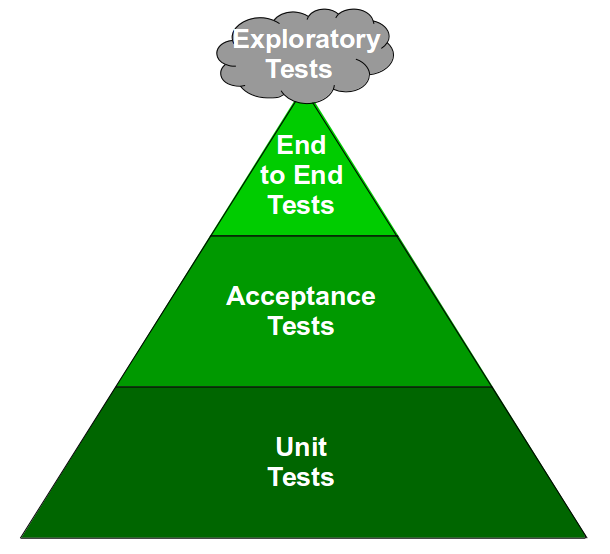
The Test Pyramid favours automated unit and acceptance tests as they offer a greater value at a lower cost. Test execution time and determinism are directly proportional to System Under Test size, and as automated unit and acceptance tests have minimal scope they provide fast, deterministic feedback. Automated end-to-end tests and exploratory testing are also valuable, but the larger System Under Test means feedback is slower and less reliable.
This testing strategy is a vast improvement upon its predecessor. Uniting developers and testers in a product team eliminates handover delays and recombines authority with responsibility, resulting in a continual emphasis upon product quality and lower lead times.
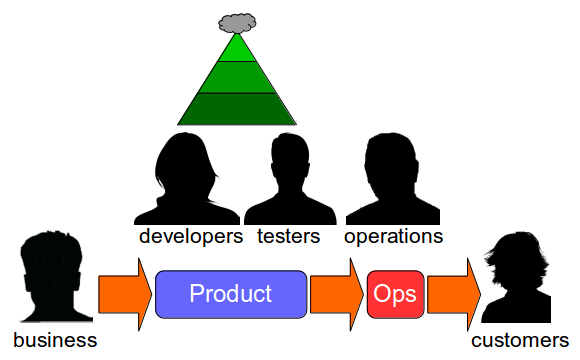
Release Testing
“I was an operational acceptance tester. I worked in a separate testing team to the developers and functional testers. I never had time to find defects or understand requirements, and always got the blame” – Jamie
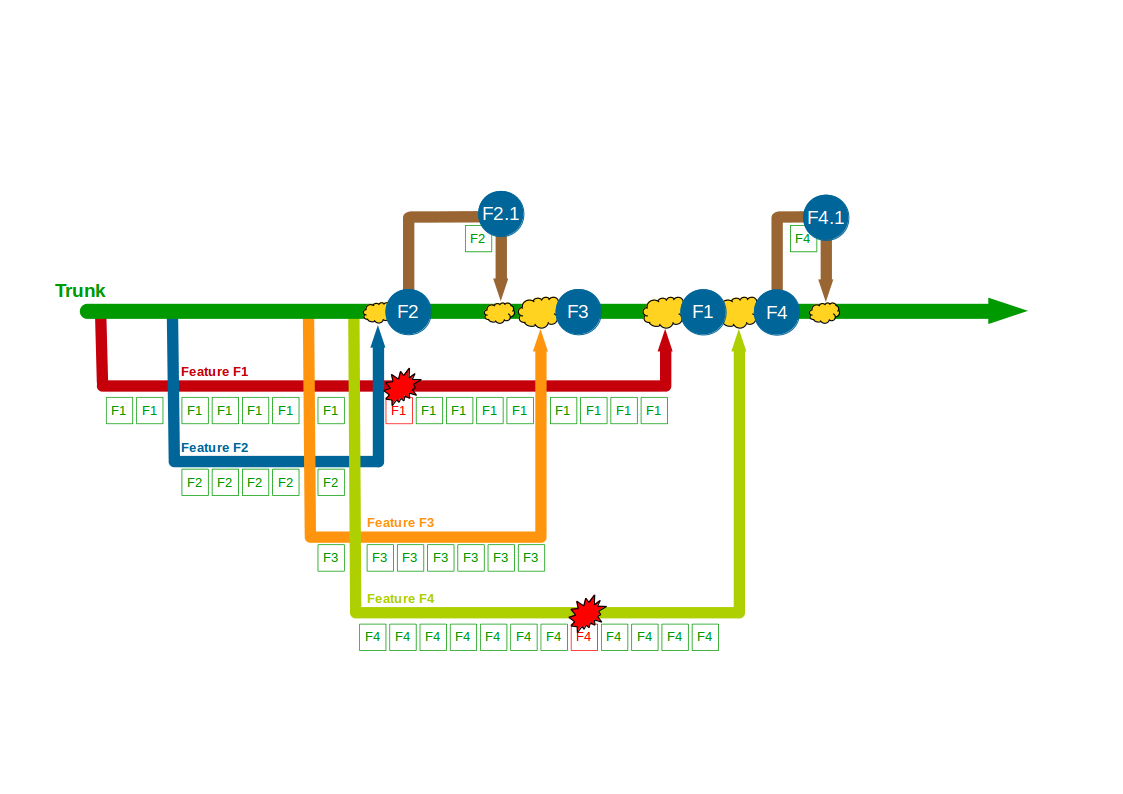
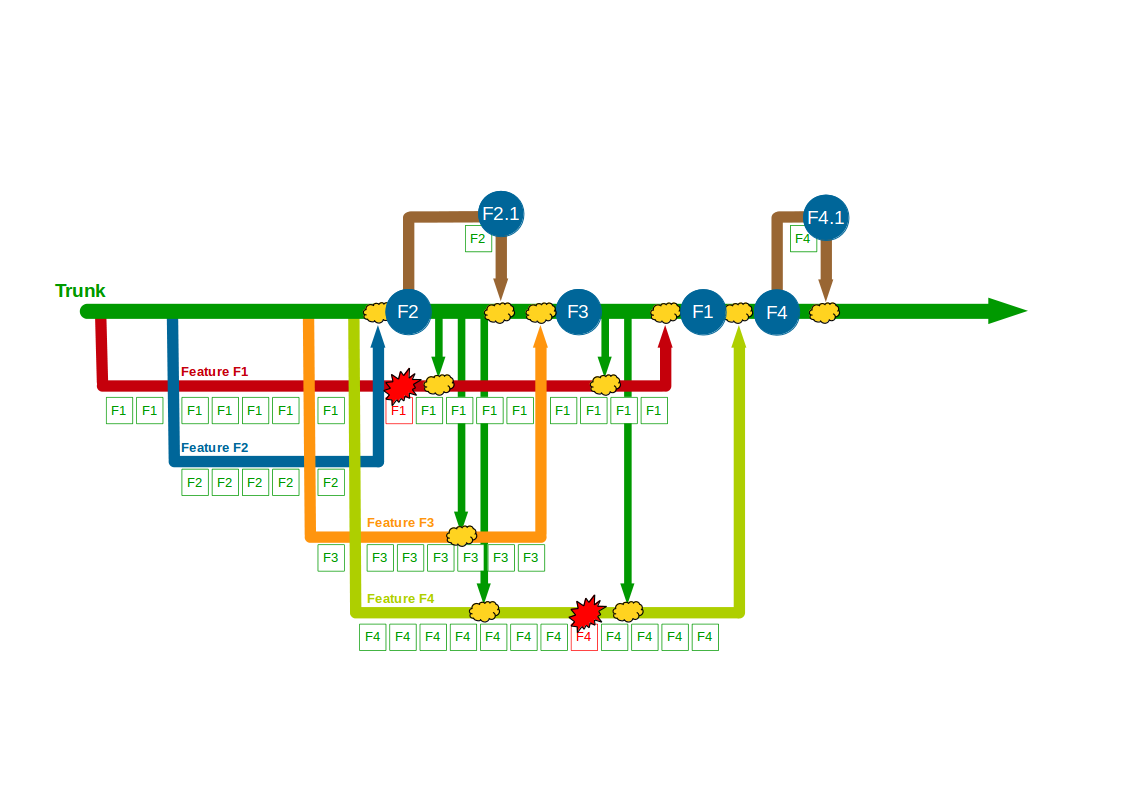
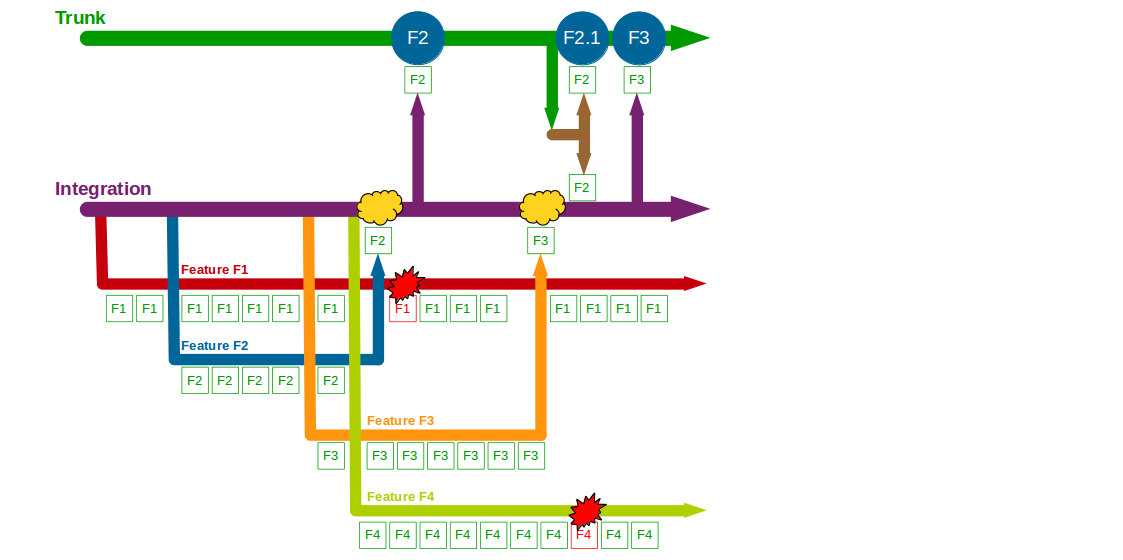
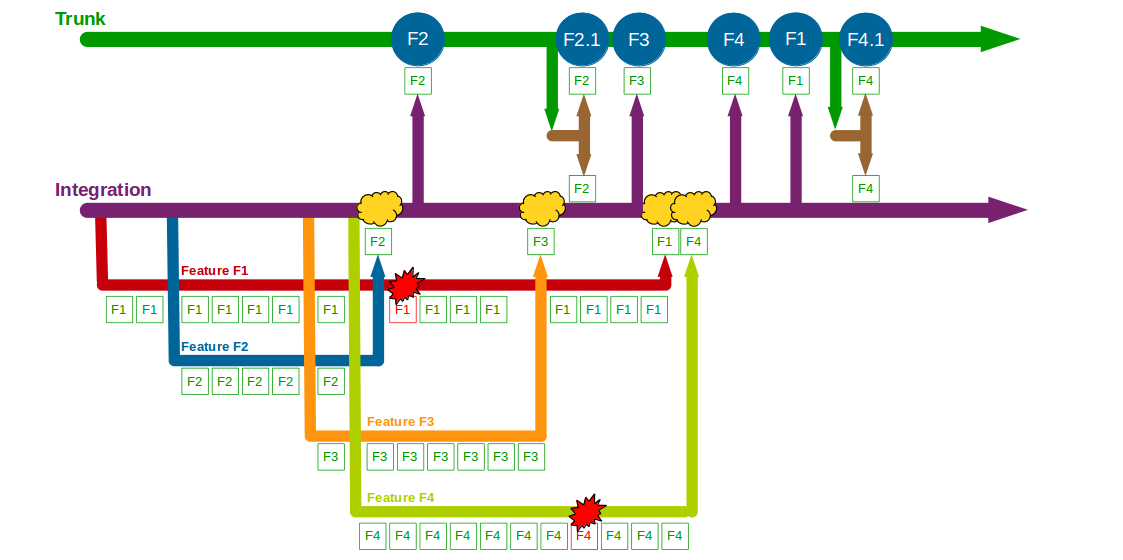
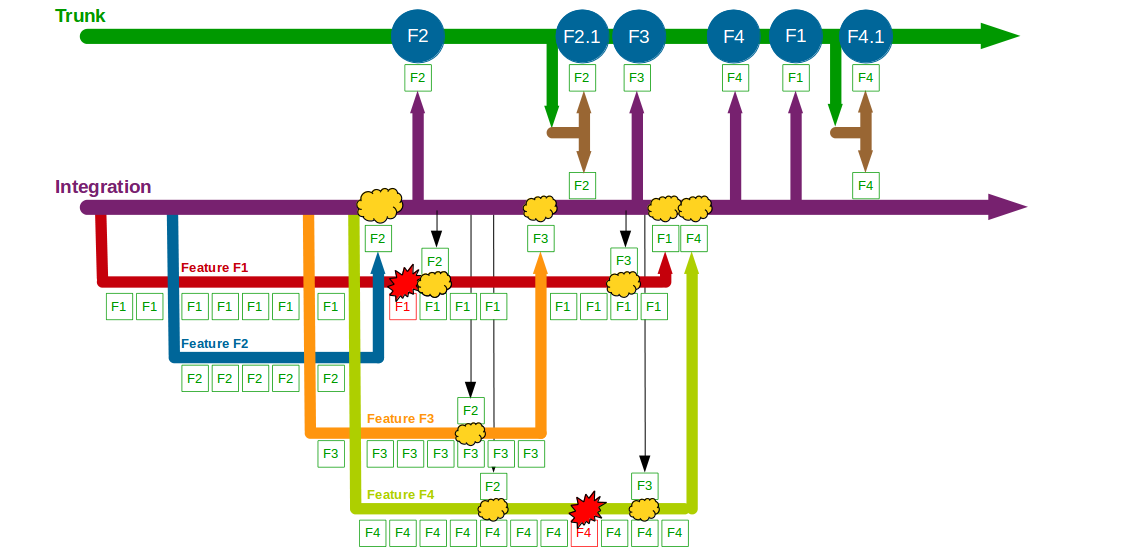
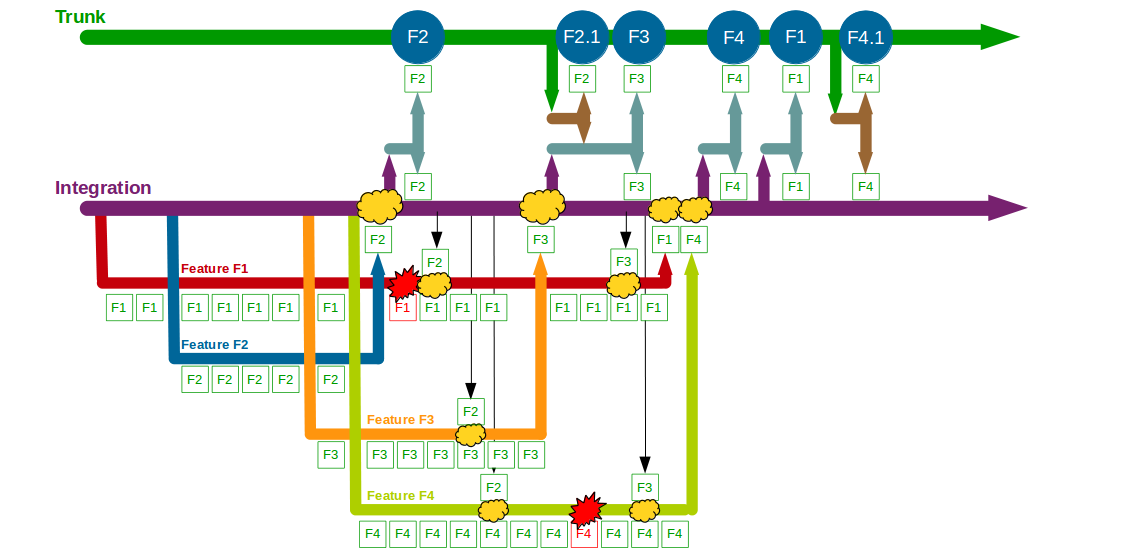
The transition from siloed development and testing teams to cross-functional product teams is a textbook example of how organisational change enables Continuous Delivery – faster feedback and improved quality will unlock substantial cycle time gains and decrease opportunity costs. However, all too often Continuous Delivery is impeded by Release Testing – an additional phase of automated and/or manual end-to-end regression testing, performed on the critical path independent of the product team.

Release Testing is often justified as a guarantee of product quality, but in reality it is a disproportionately costly practice with little potential for defect discovery. The segregation of release testers from the product team reinserts handover delays into the value stream and dilutes responsibility for quality, increasing feedback loops and rework. Furthermore, as release testers must rely upon end-to-end tests their testing invariably becomes a Test Ice Cream Cone of slow, brittle tests with long execution times and high maintenance costs.
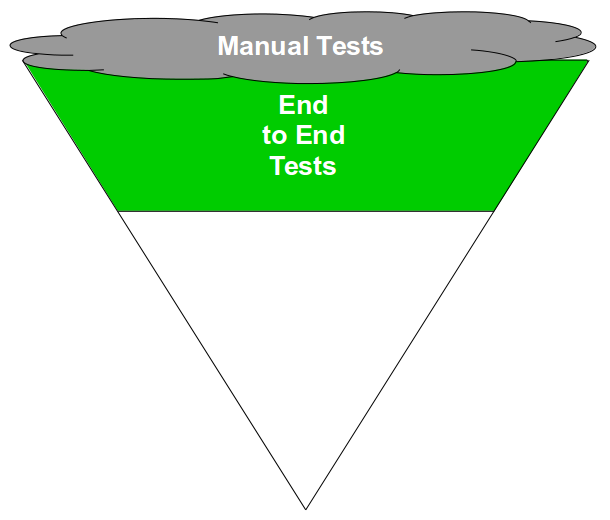
The reliance of Release Testing upon end-to-end testing on the critical path means a low degree of test coverage is inevitable. Release testers will always be working to a pre-arranged business deadline outside their control, and consequently test coverage will often be curtailed to such an extent the blameless testers will find it difficult to uncover any significant defects.
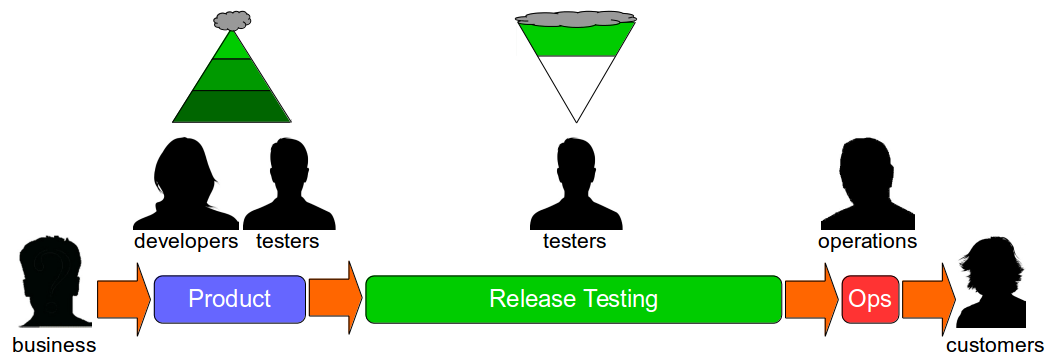
When viewed through a Continuous Delivery frame the high cost and low value of Release Testing become evident, and attempting to redress that imbalance is a zero-sum game. Decreasing the cost of Release Testing means fewer end-to-end tests, which will decrease execution time but also decrease test coverage. Increasing the value of Release Testing means more end-to-end tests, which will increase test coverage but also increase execution time. Release Testing can therefore be considered an example of what Jez Humble describes as Risk Management Theatre – an overly-costly practice with an artificial sense of value.
Release Testing is high cost, low value Risk Management Theatre
Build Quality In
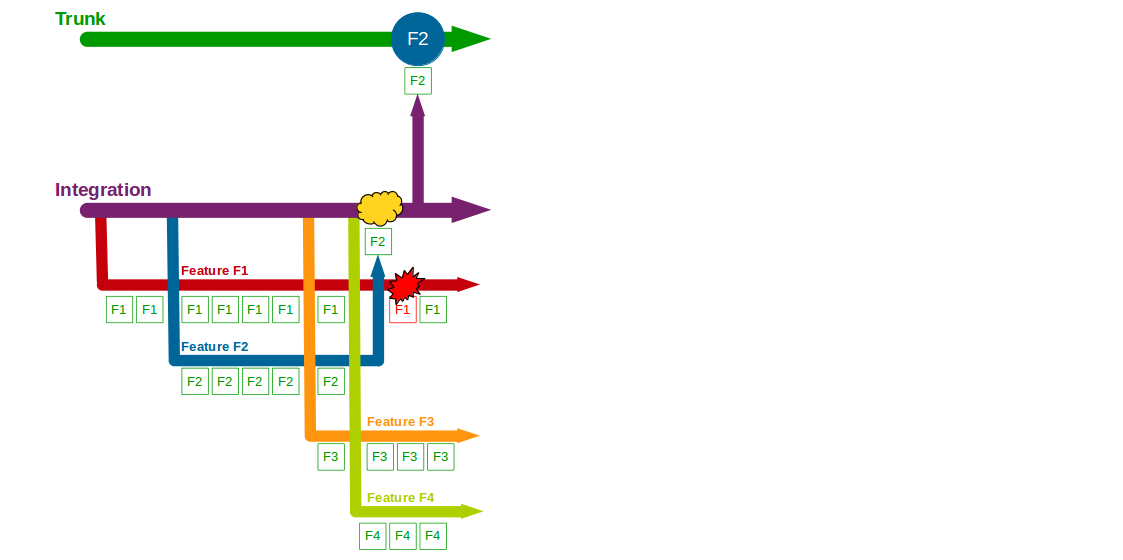
Continuous Delivery is founded upon the Lean Manufacturing principle of Build Quality In, and the advice of Dr. W. Edwards Deming that “we cannot rely on mass inspection to improve quality” is especially pertinent to Release Testing. An organisation should build quality into its product rather than expect testers to inspect quality in at a later date, and that means eliminating Release Testing by moving release testers back into the product team.
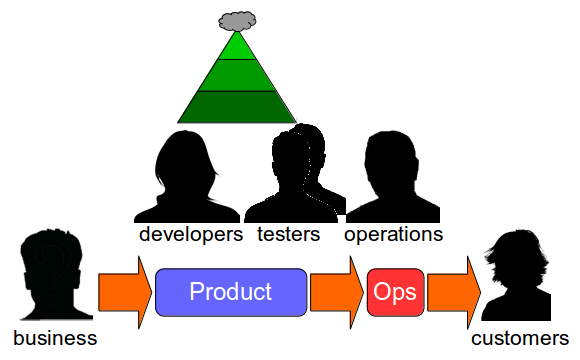
Folding release testers into product development removes the handover delays and responsibility barriers imposed by Release Testing. End-to-end regression tests can be audited by all stakeholders, with valuable tests retained and the remainder discarded. More importantly, ex-release testers will be freed up to work on higher-value activities off the critical path, such as exploratory testing and business analysis.
Batch Size Reduction
Given the limited value of Release Testing it is prudent to consider other risk reduction strategies, and a viable alternative supported by Continuous Delivery is Batch Size Reduction – releasing smaller changesets more frequently into production. Splitting a large experiment into smaller independent experiments reduces variation in outcomes, so by decomposing large changesets into smaller unrelated changesets we can reduce the probability of failure associated with any one changeset.
For example, assume an organisation has a median cycle time of 12 weeks – perhaps due to Release Testing – and a pending release of 4 features. The probability of failure for this release has been estimated as 1 in 2 (50%), and there is a desire to reduce that level of risk.
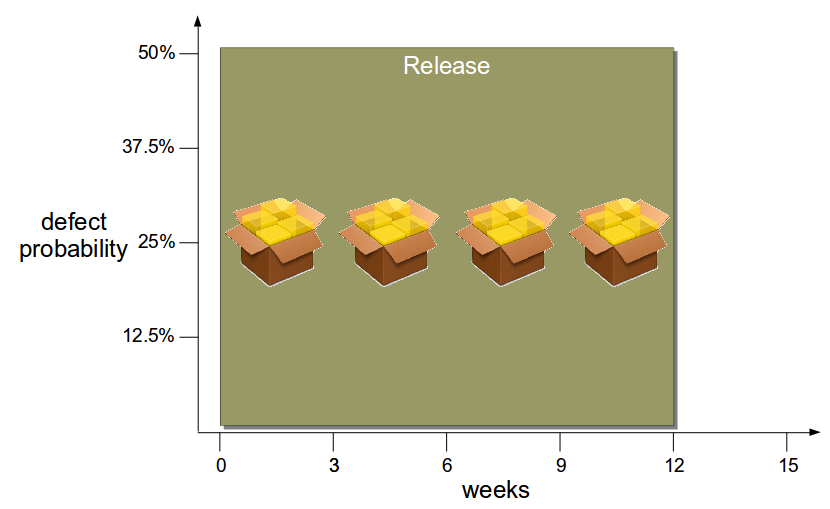
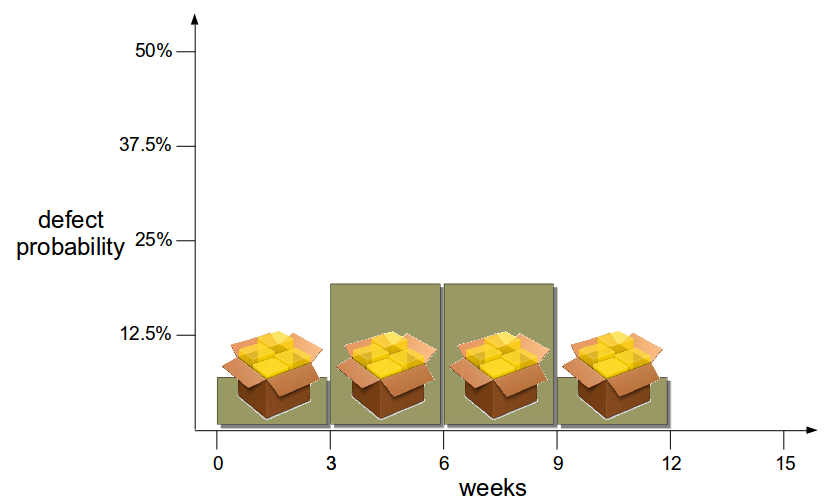
As the 50% estimate is aggregated from 4 features it can be improved by reducing delivery costs – perhaps by eliminating Release Testing – and releasing features independently every 3 weeks. While this theoretically produces 4 homogeneous releases with a 1 in 8 (12.5%) failure probability, the heterogeneity of product development creates variable feature complexity – and smaller changesets enable more accurate estimation of comparative failure probabilities. In this example the 4 changesets allow a more detailed risk assessment that assigns features 2 and 3 a higher failure probability, which means more exploratory testing time can be allocated to those specific features to reduce overall failure probability.
When a production defect does occur, batch size reduction has the ability to significantly reduce defect cost. The cost of a defect is comprised of the sunk cost incurred between activation and discovery, and the opportunity cost incurred between discovery and resolution. Those costs are a function of cost per unit time and duration, where cost per unit time represents economic impact and duration represents time.
For example, assume the organisation unwisely retained its 12 week lead time and a production defect D1 has been found 3 weeks after release. An assessment of external market conditions calculates a static cost per unit time of £10,000 a week, which means a sunk cost of £30,000 has already been incurred and a £120,000 opportunity cost is looming.
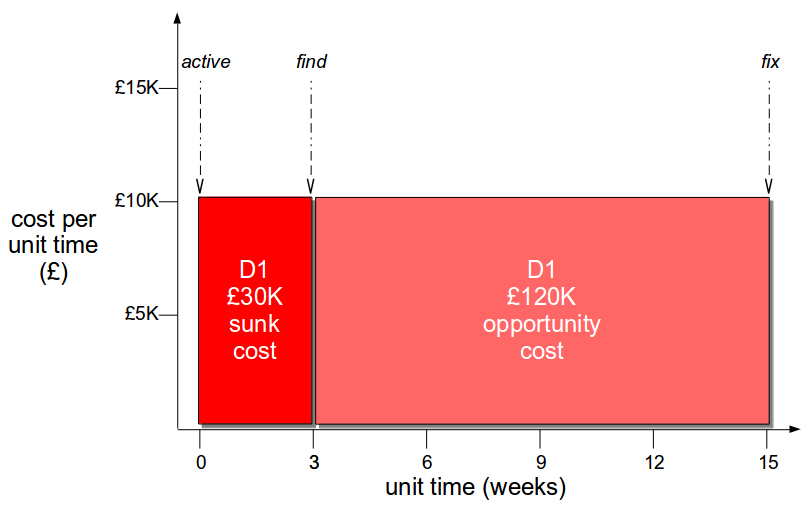
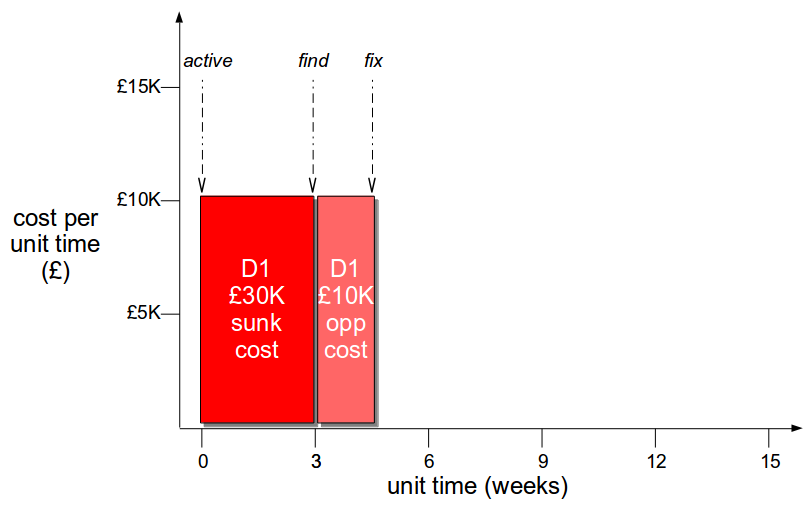
As cost per unit time is governed by external market conditions it is difficult to influence, but duration is controlled by Little’s Law which states that lead time is directly proportional to work in progress. This means the opportunity cost duration of a defect can be decreased by releasing the defect fix in a smaller changeset, which will result in a shorter lead time and a reduced defect cost. If a fix for D1 is released in its own changeset in 1 week, that would decrease the opportunity cost by 92% to £10,000 and produce a 73% overall reduction in defect cost to £40,000.
Conclusion
Release Testing is the definitive example of Risk Management Theatre in the IT industry today and a significant barrier to Continuous Delivery. End-to-end regression testing on the critical path cannot provide any meaningful reduction in defect probability without incurring costs that harm product quality and inflate lead times. Continuous Delivery advocates a lower cost, higher value alternative in which the product team owns responsibility for product quality, with an emphasis upon exploratory testing and batch size reduction to decrease risk.
Tester names have been altered
Further Reading
- Leading Lean Software Development by Mary and Tom Poppendieck
- Assign Responsibility And Authority by Shelley Doll
- Integrated Tests Are A Scam by JB Rainsberger
- Continuous Delivery by Dave Farley and Jez Humble
- Organisation Antipattern – Release Testing by Steve Smith
- The Essential Deming by W. Edwards Deming
- Explore It! by Elisabeth Hendrickson
- Principles Of Product Development Flow by Don Reinertsen

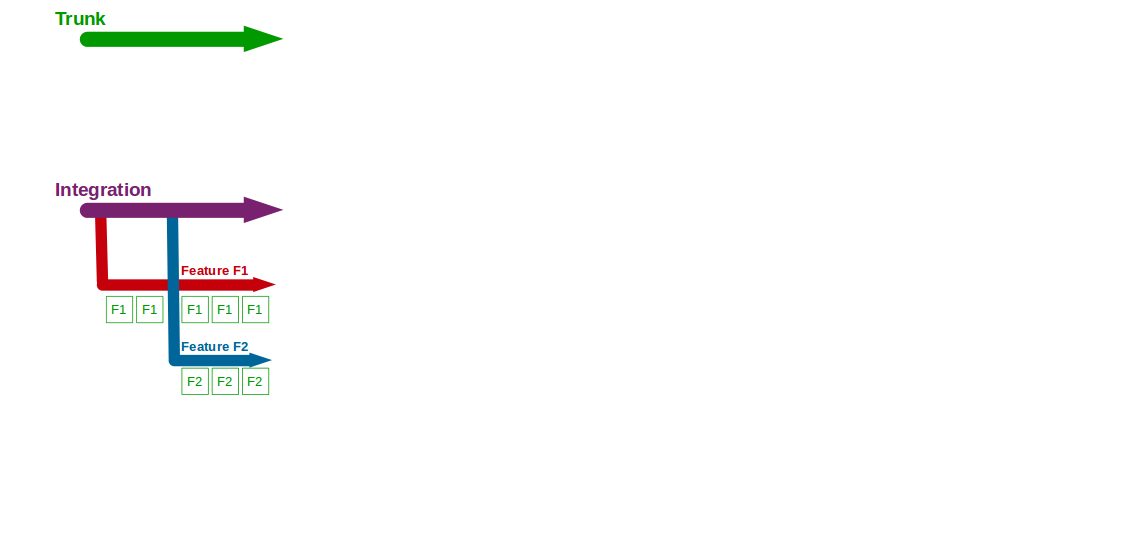
Recent Comments