API Examples enable consumer unit testing of producer APIs
When an application consumes data from a remote service, we wish to verify the correctness of consumer-producer interactions via a testing strategy that encompasses the following characteristics:
- Fast feedback
- 100% scenario coverage
- Representative test data
- Auto-detect API changes
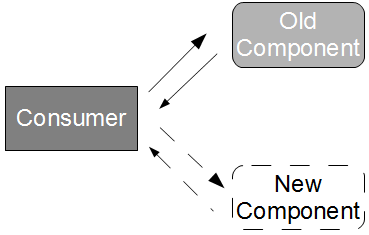
The simplest method of verifying parser behaviour would be to use Test Driven Development and create a suite of unit tests reliant upon self-generated test data. These tests could provide feedback in milliseconds, and would be able to cover all happy/sad path scenarios. However, consumer ownership of test data increases the probability of errors as highlighted by Brandon Byars warning that “hard-coding assumptions about data available at the time of the test can be a fragile approach“, and it leaves the consumer entirely unaware of API changes when a new producer version is released.
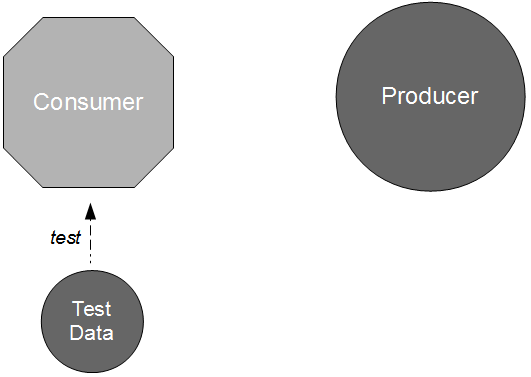
To address these concerns, we could write some integration tests to trigger interactions between running instances of the producer and consumer applications to implicitly test parser behaviour. This could encourage the use of representative test data and warn the consumer of producer API changes, but the increase in run time from milliseconds to minutes would result in significant feedback delays and a corresponding reduction in scenario coverage. Given JB Rainsberger’s oft-quoted assertion that “integrated tests are a scam… you write integrated tests because you can’t write perfect unit tests“, it seems prudent to explore how we might equip our unit testing strategy with representative test data and an awareness of API changes.
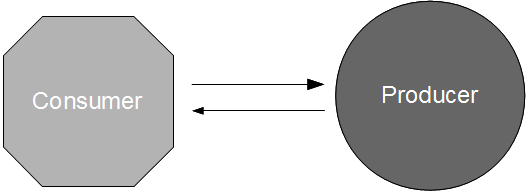
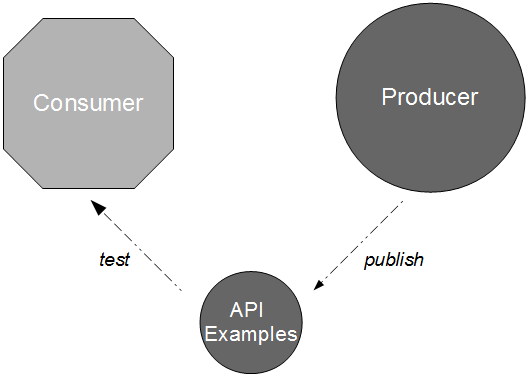
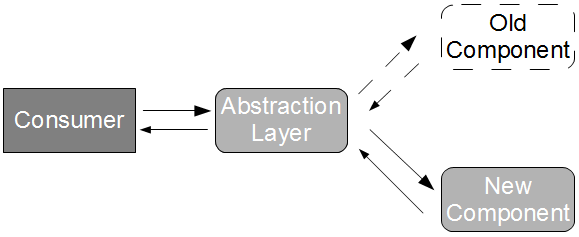
API Examples is an application pattern originally devised by Daniel Worthingon-Bodart, in which a new version of a producer application is accompanied by a sibling artifact that solely contains example API requests and example API responses. These example files should be raw textual data recorded from the acceptance tests of the producer application, meaning that all happy/sad path scenarios known to the producer become freely available for unit testing within the consumer commit build without any binary dependencies or feedback delays. This approach satisfies Brandon’s recommendation that “each service publish a cohesive set of golden test data that it guarantees to be stable“, and when combined with a regular update policy ensures new versions of the consumer application will have early warning of API changes.
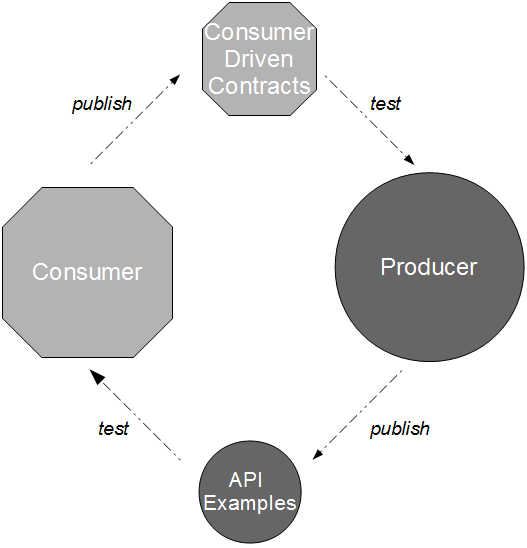
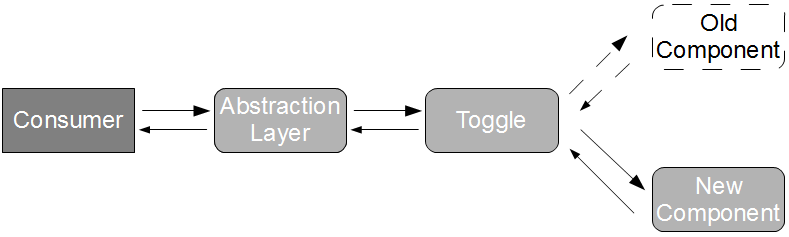
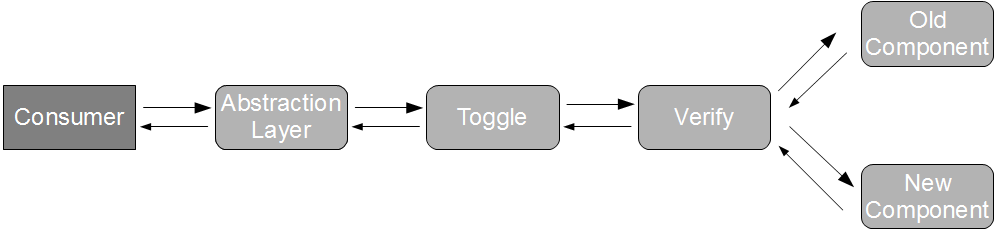
As API Examples are exercised within the consumer commit build, they can warn a new consumer version of an API change but cannot warn an existing consumer version already in production. The solution to this problem is for the consumer to derive its parser behaviour from the API Examples and publish it as a Consumer Driven Contract – a testable specification embedded within the producer commit build to document how the consumer uses the API and to immediately warn the producer if an API change will harm a consumer.
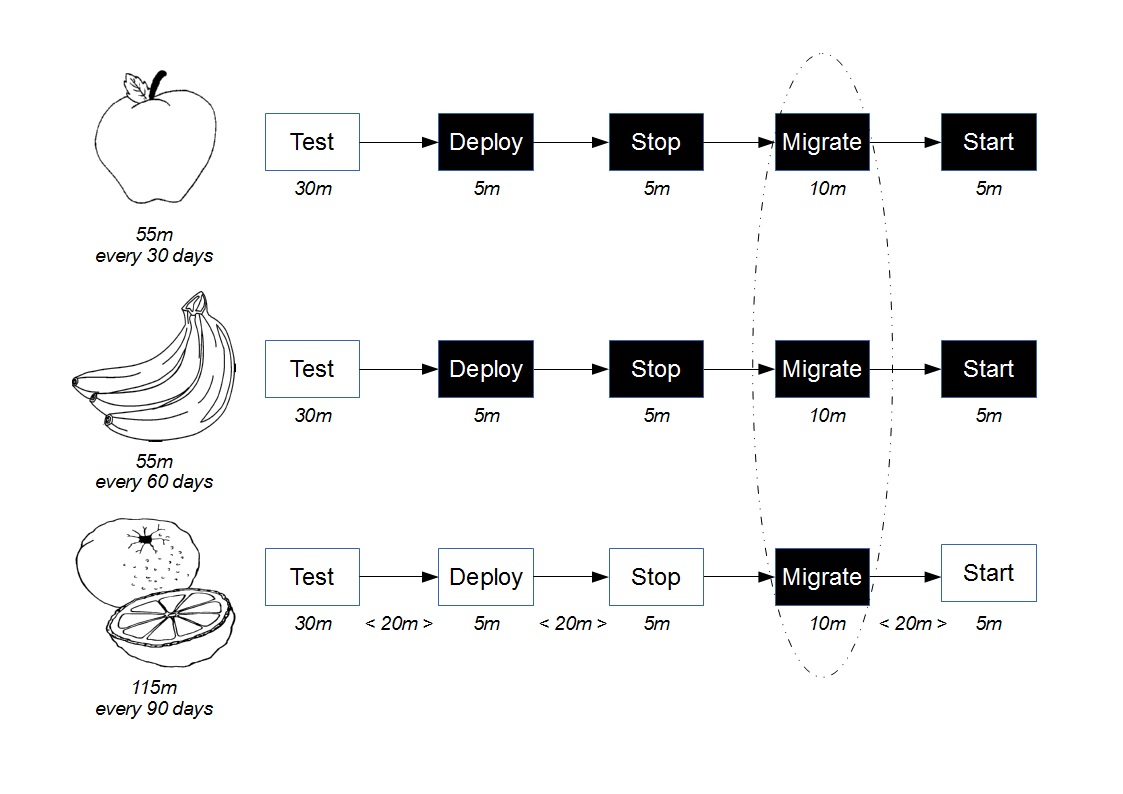

![Economic Batch Size [Reinertsen]](https://www.stevesmith.tech/wp-content/uploads/2013/03/Economic-Batch-Size-Reinertsen.jpg)