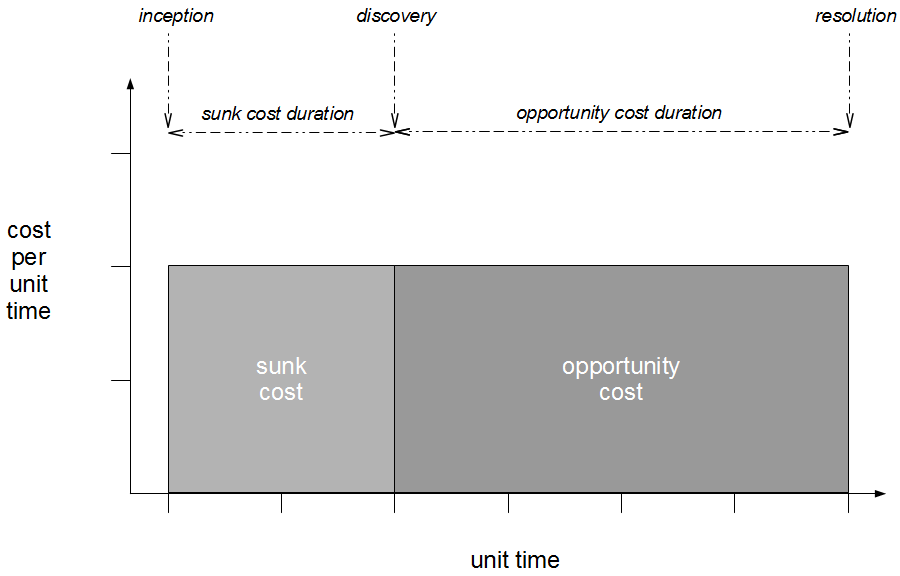
Dual Value Streams conceal transaction and opportunity costs
The goal of Continuous Delivery is to optimise cycle time in order to increase product revenues, and cycle time is measured as the average lead time of the value stream from code checkin to production release. This was memorably summarised by Mary and Tom Poppendieck as the Poppendieck Question:
“How long would it take your organization to deploy a change that involves just one single line of code? Do you do this on a repeatable, reliable basis?”
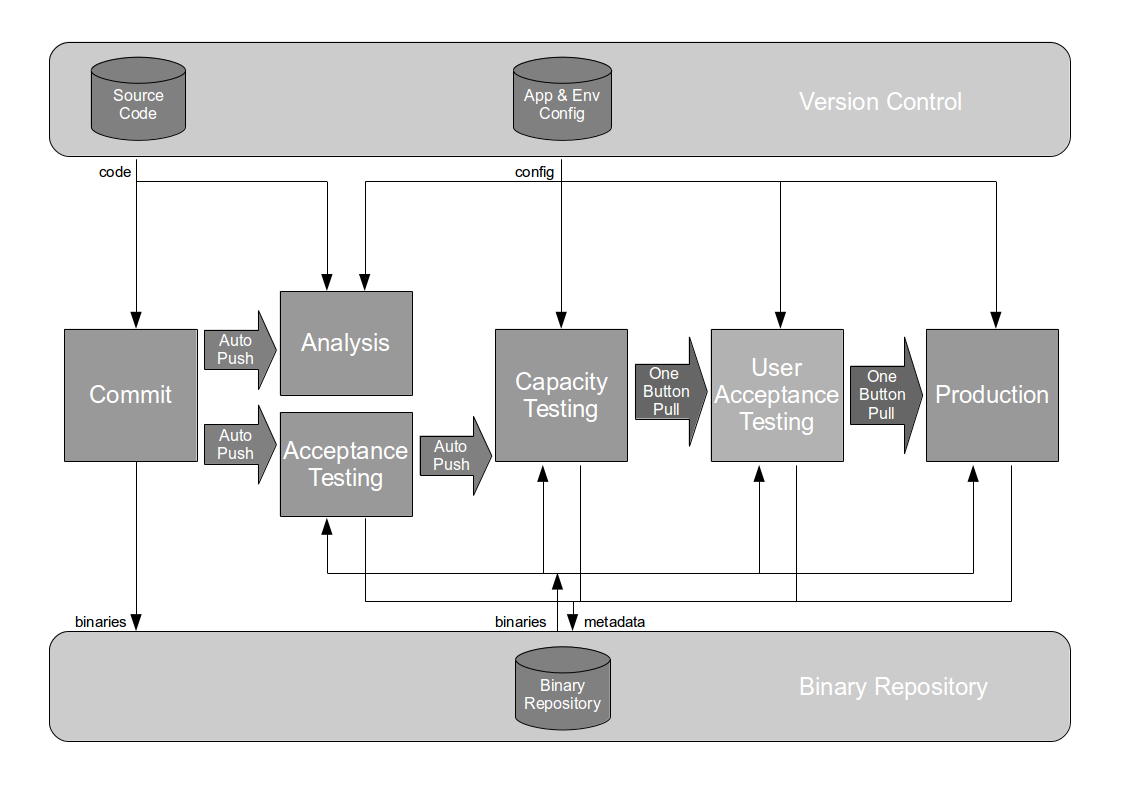
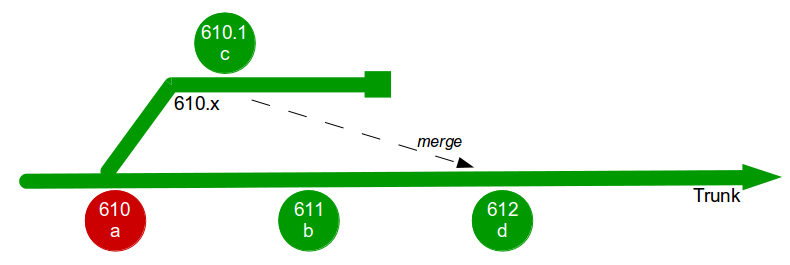
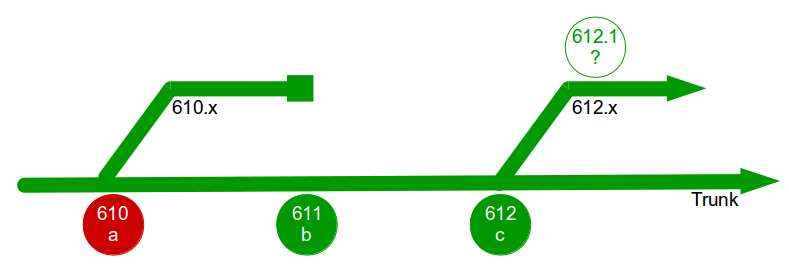
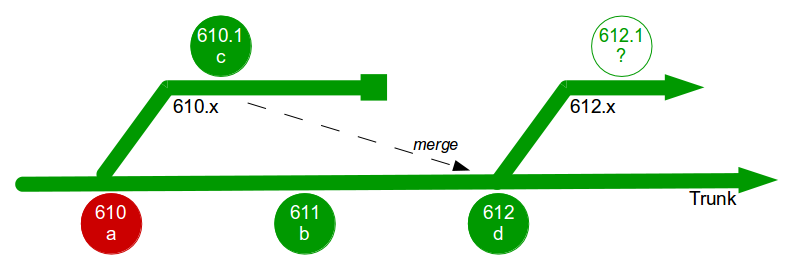
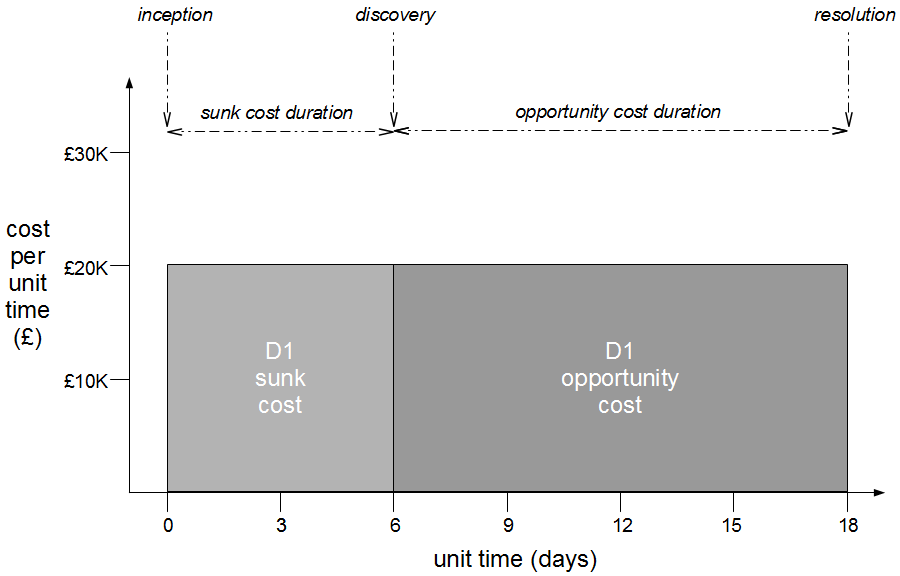
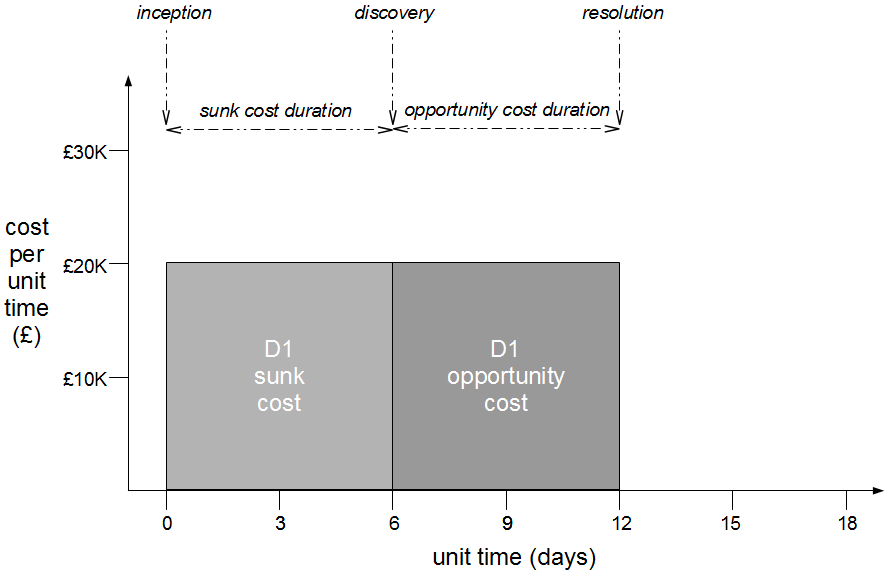
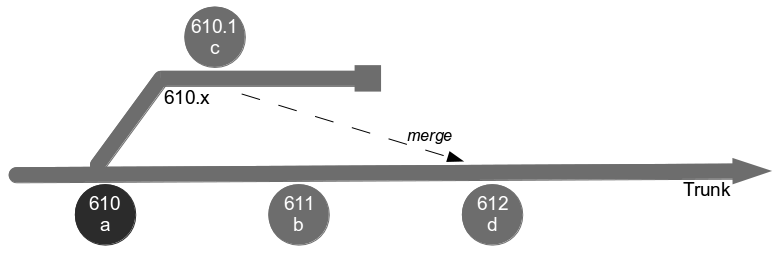
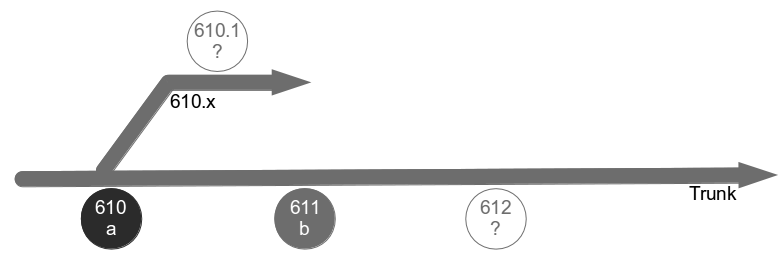
The Poppendieck Question is an excellent lead-in to the Continuous Delivery value proposition, but the problem with using it to assess the cycle time of an organisation yet to adopt Continuous Delivery is there will often be two very different answers – one for features, and one for fixes. For example, consider an organisation with a quarterly release cycle. The initial answer to the Poppendieck Question would be “90 days” or similar. 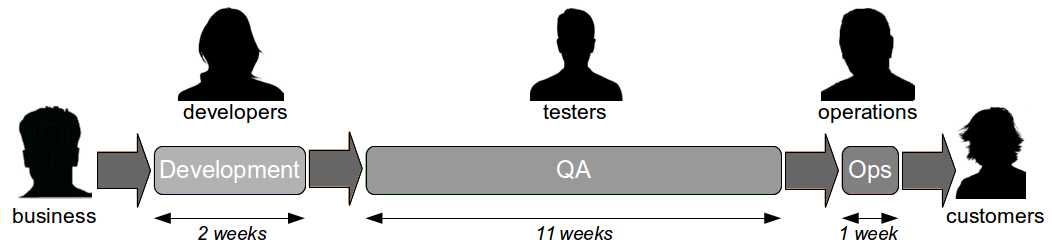 However, when the transaction cost of releasing software is disproportionately high a truncated value stream will often emerge for production defect fixes, in which value stream activities are deliberately omitted to slash cycle time. This results in Dual Value Streams – a Feature Value Stream with a cycle time of months, and a Fix Value Stream with a cycle time of days. If our example organisation can release a defect fix in a few days, the correct answer to the Poppendieck Question becomes “90 days or 3 days”.
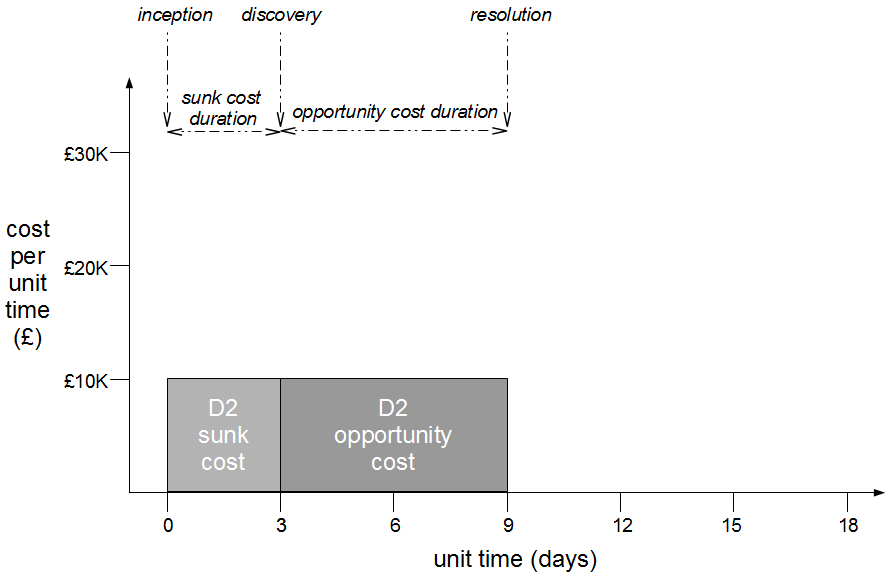
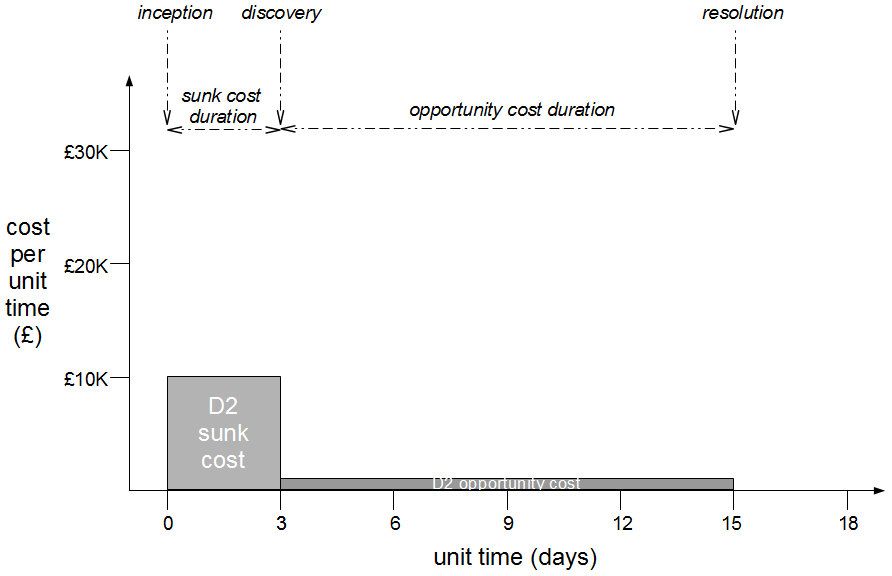
However, when the transaction cost of releasing software is disproportionately high a truncated value stream will often emerge for production defect fixes, in which value stream activities are deliberately omitted to slash cycle time. This results in Dual Value Streams – a Feature Value Stream with a cycle time of months, and a Fix Value Stream with a cycle time of days. If our example organisation can release a defect fix in a few days, the correct answer to the Poppendieck Question becomes “90 days or 3 days”. 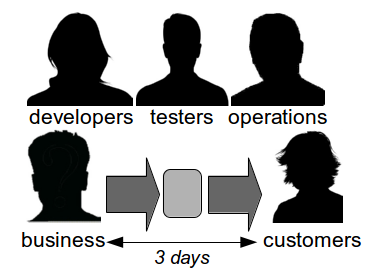 Fix Value Streams exist because production defect fixes have a clear financial value that is easily communicated and outweighs the high transaction cost of Feature Value Streams. An organisation will be imbued with a sense of urgency, as a sunk cost has demonstrably been incurred and by releasing a fix faster an opportunity cost can be reduced. People in siloed teams will collaborate upon a fix, and by using a minimal changeset it becomes possible to reason about which value stream activities can be discarded e.g. omitting capacity testing for a UI fix.
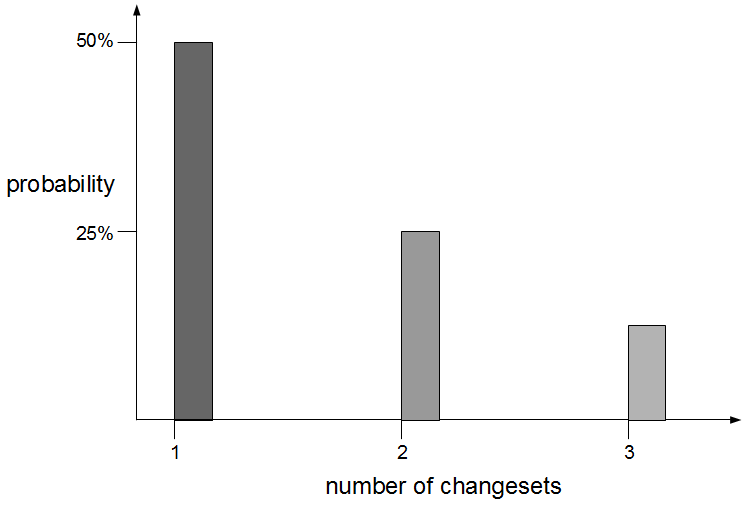
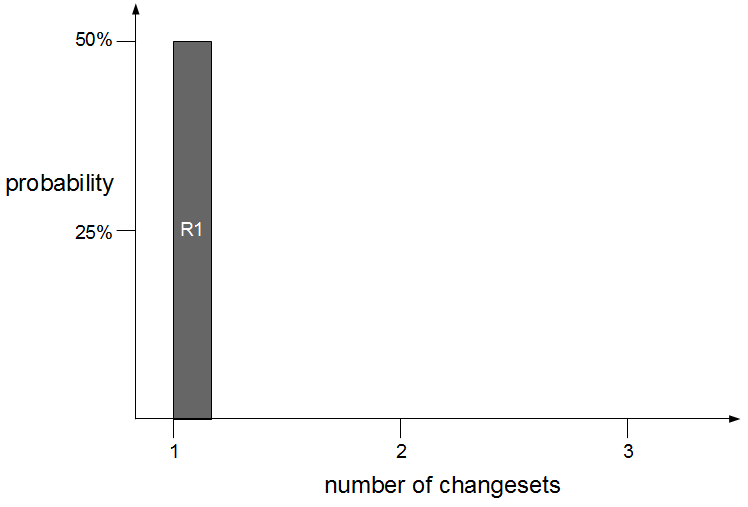
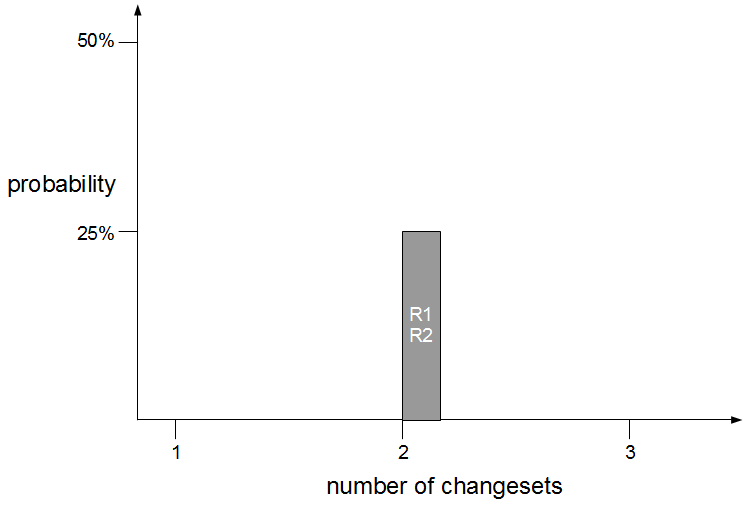
Fix Value Streams exist because production defect fixes have a clear financial value that is easily communicated and outweighs the high transaction cost of Feature Value Streams. An organisation will be imbued with a sense of urgency, as a sunk cost has demonstrably been incurred and by releasing a fix faster an opportunity cost can be reduced. People in siloed teams will collaborate upon a fix, and by using a minimal changeset it becomes possible to reason about which value stream activities can be discarded e.g. omitting capacity testing for a UI fix.
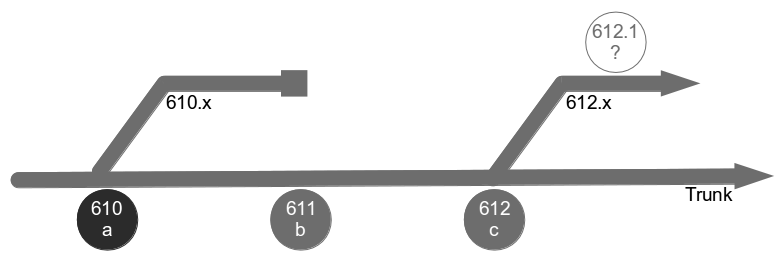
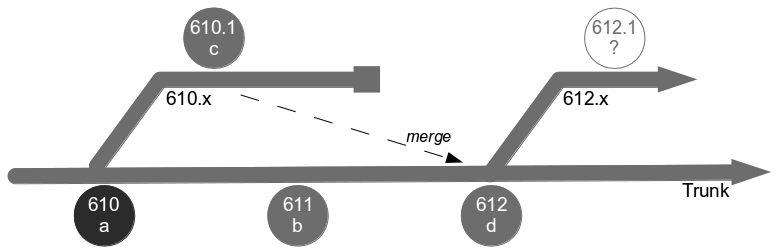
Dual Value Streams is an organisational antipattern because it is a local optimisation with little overall benefit to the organisation. There has been an investment in a release mechanism with a smaller batch size and a lower transaction cost, but as it is reserved for defect fixes it cannot add new customer value to the product. The long-term alternative is for organisations to adopt Continuous Delivery and invest in a single value stream with a minimal overall transaction cost. If our example organisation folded its siloed teams into cross-functional teams and moved activities off the critical path a fortnightly release cycle would become a distinct possibility. 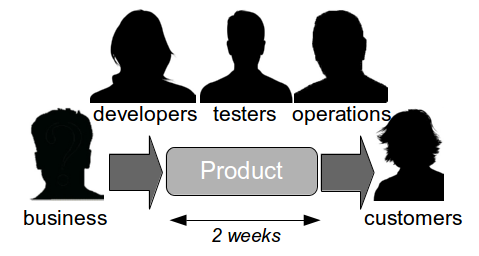 Dual Value Streams is an indicator of organisational potential for Continuous Delivery. When people are aware of the opportunity costs associated with releasing software as well as the transaction costs they are more inclined to work together in a cross-functional manner. When changesets contain a small number of changes it becomes easier to collectively reason about which value stream activities are useful and which should be moved off the critical path or retired.
Dual Value Streams is an indicator of organisational potential for Continuous Delivery. When people are aware of the opportunity costs associated with releasing software as well as the transaction costs they are more inclined to work together in a cross-functional manner. When changesets contain a small number of changes it becomes easier to collectively reason about which value stream activities are useful and which should be moved off the critical path or retired.
Furthermore, a Fix Value Stream implicitly validates the use of smaller batch sizes as a risk reduction strategy. Defect fixes are released in small changes to minimise both opportunity costs and the probability of any further errors. Given that strategy works for fixes, why not release features more frequently and measure an organisation against a value-centric Poppendieck Question?
“How long would it take your organization to release a single value-adding line of code? Do you do this on a repeatable, reliable basis?”




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}