“Is it possible to overinvest in Continuous Delivery?
The benefits of Continuous Delivery are astonishing, so it’s tempting to say no. Keep on increasing throughput indefinitely, and enjoy the efficiency gains! But that costs time and money, and if you’re already satisfying customer demand… should you keep pushing so hard?
If you’ve already achieved Continuous Delivery, sometimes your organisation should invest its scarce resources elsewhere – for a time. Continuously improve in the fuzzy front end of product development, as well as in technology.”
Steve Smith
TL;DR:
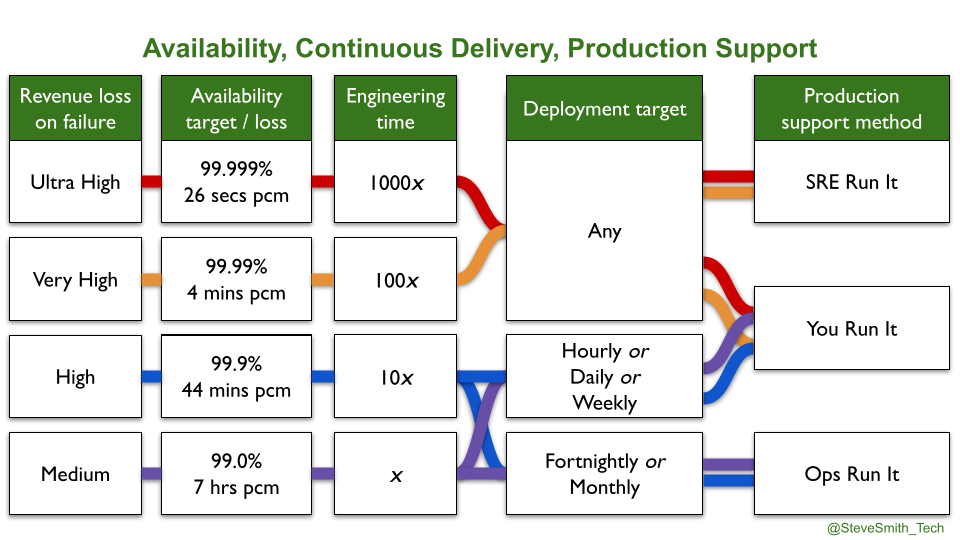
- Deployment throughput levels describe the effort necessary to implement Continuous Delivery in an enterprise organisation.
- Investing in Continuous Delivery means experimenting with technology and organisational changes to find and remove constraints in build, testing, and operational activities.
- When such a constraint does not exist, it is possible to overinvest in Continuous Delivery beyond the required throughput level.
Introduction
Continuous Delivery means increasing deployment throughput until customer demand is satisfied. It involves radical technology and organisational changes. Accelerate by Dr. Nicole Forsgren et al describes the benefits of Continuous Delivery:
- A faster time to market, and increased revenues.
- A substantial improvement in technical quality, and reduced costs.
- An uptick in profitability, market share, and productivity.
- Improved job satisfaction, and less burnout for employees.
If an enterprise organisation has IT as a Cost Centre, funding for Continuous Delivery is usually time-limited and orthogonal to development projects. Discontinuous Delivery and a historic underinvestment in continuous improvement are the starting point.
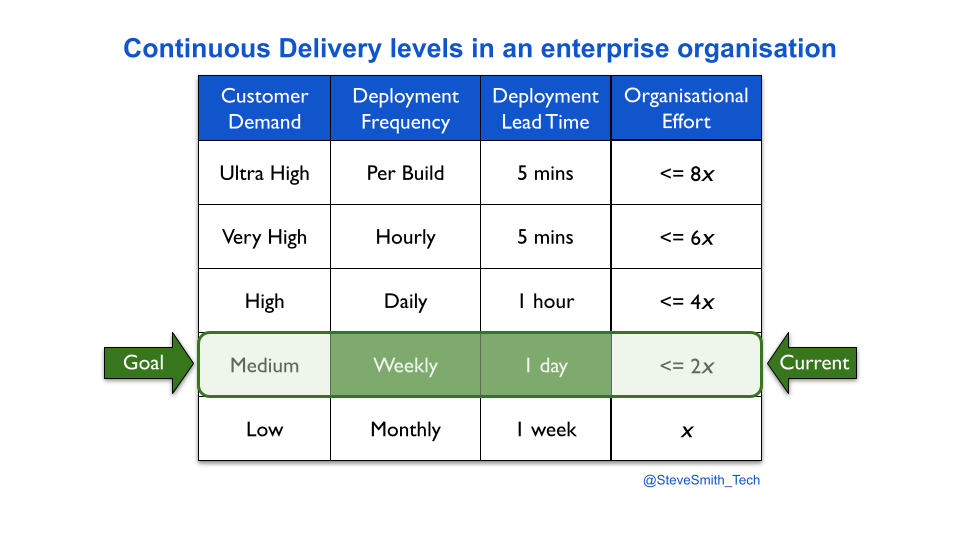
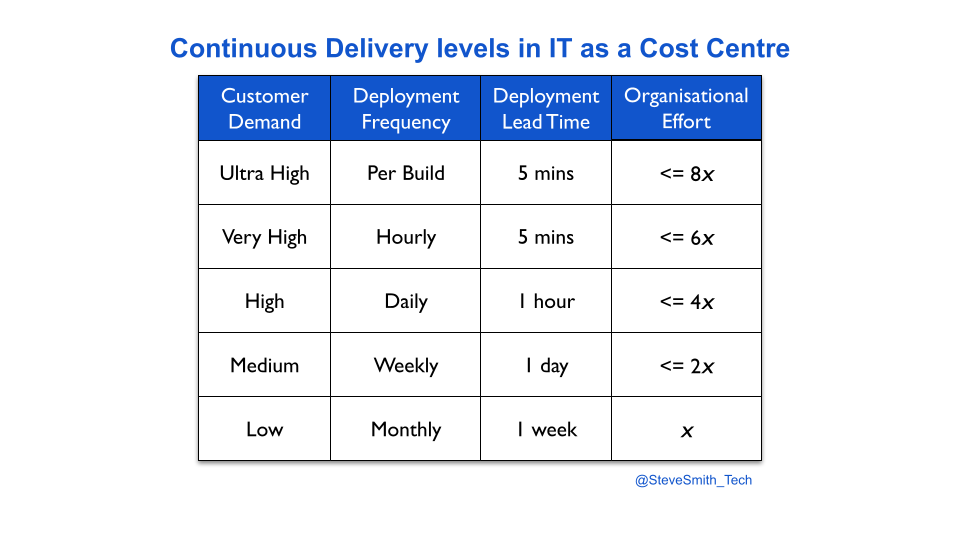
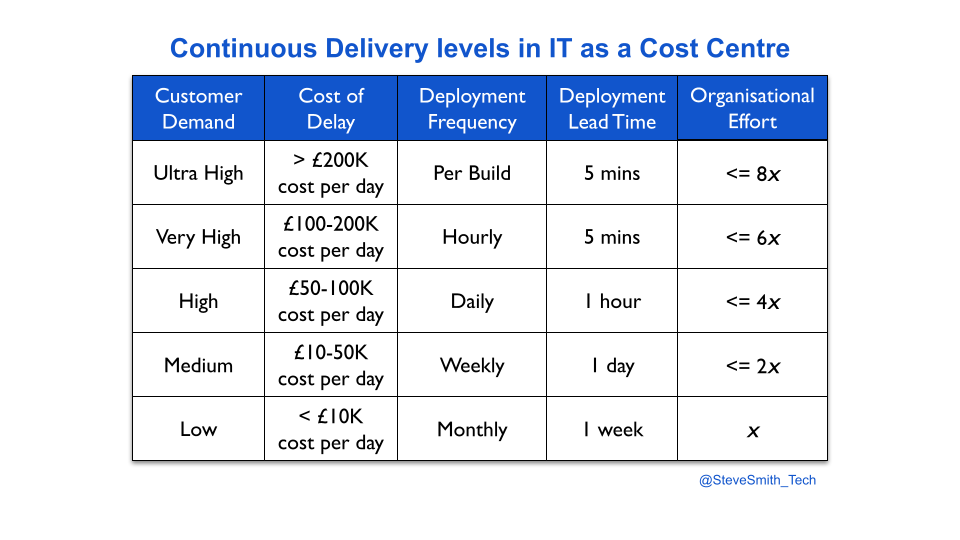
Continuous Delivery levels provide an estimation heuristic for different levels of deployment throughput versus organisational effort. A product manager might hypothesise their product has to move from monthly to weekly deployments, in order to satisfy customer demand. It can be estimated that implementing weekly deployments would take twice as much effort as monthly deployments.

Once the required throughput level is reached, incremental improvement efforts need to be funded and completed as business as usual. This protects ongoing deployment throughput, and the satisfaction of customer demand. The follow-up question is then how much more time and money to spend on deployment throughput. This can be framed as:
Is it possible to overinvest in Continuous Delivery?
To answer this question, a deeper understanding of how Continuous Delivery happens is necessary.
Investing with a deployment constraint
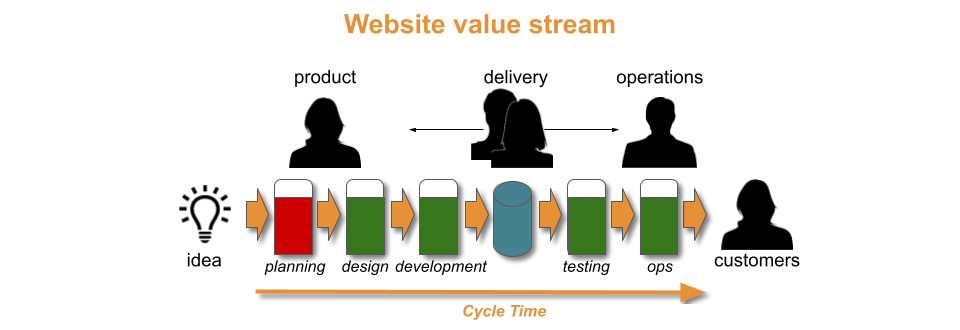
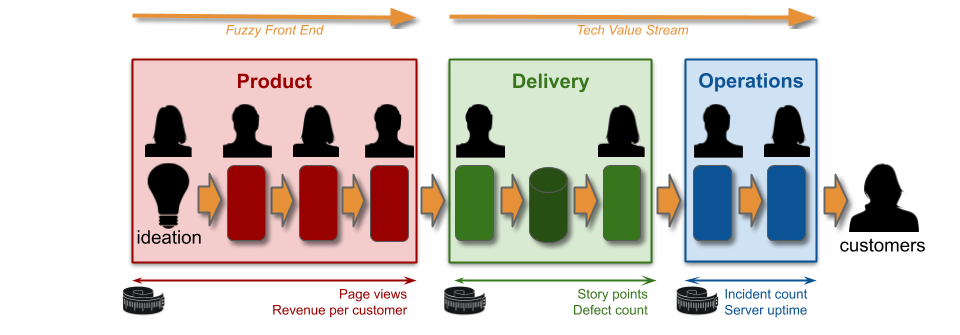
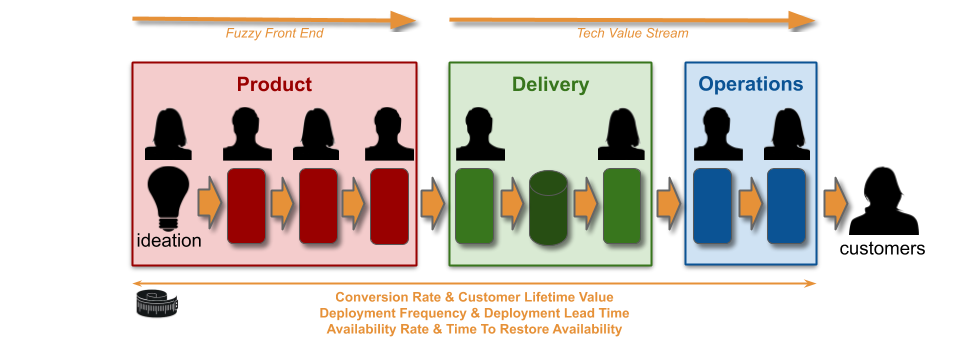
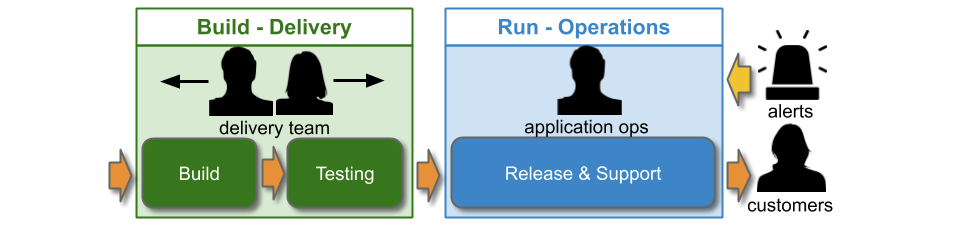
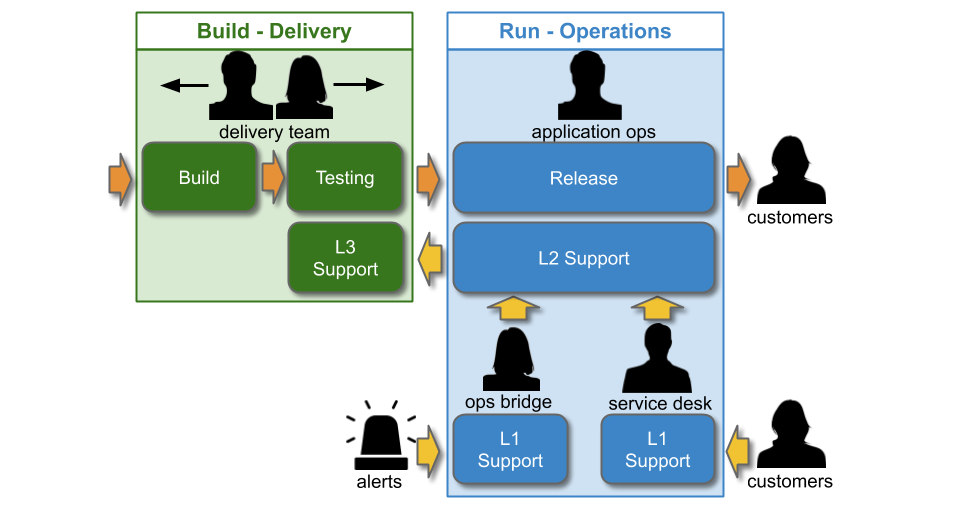
In an organisation, a product traverses a value stream with a fuzzy front end of design and development activities, and a technology value stream of build, testing, and operational activities.
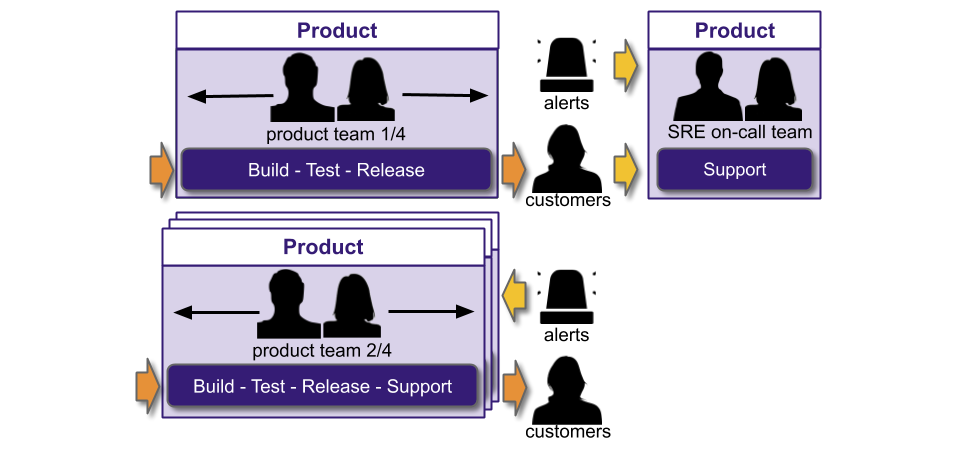
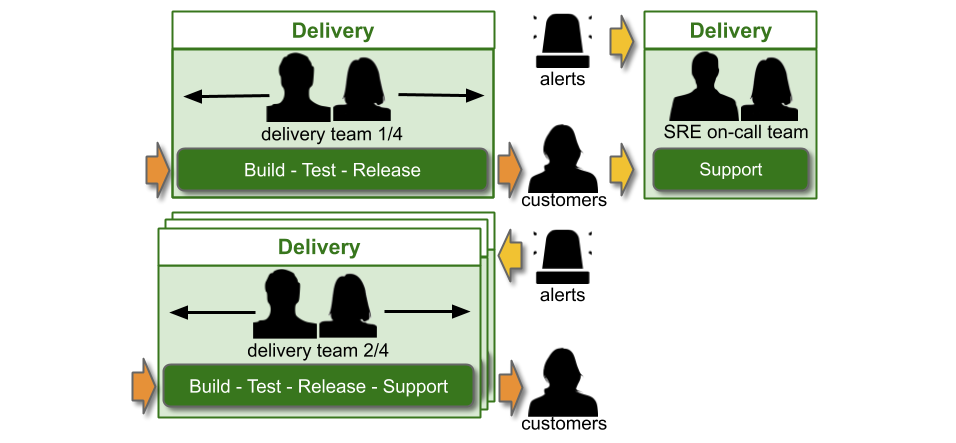
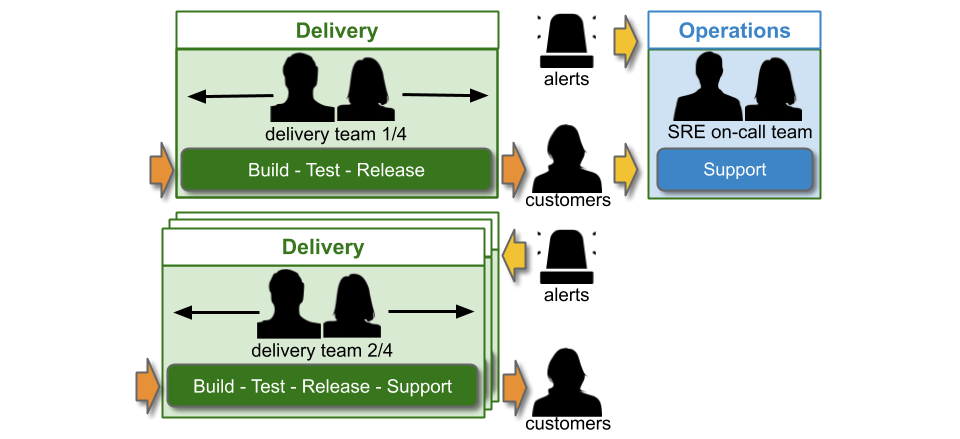
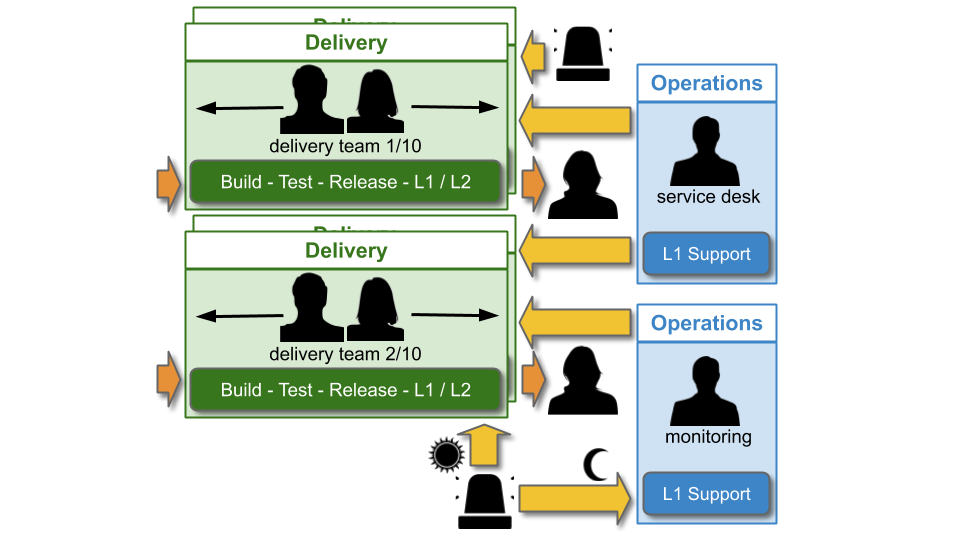
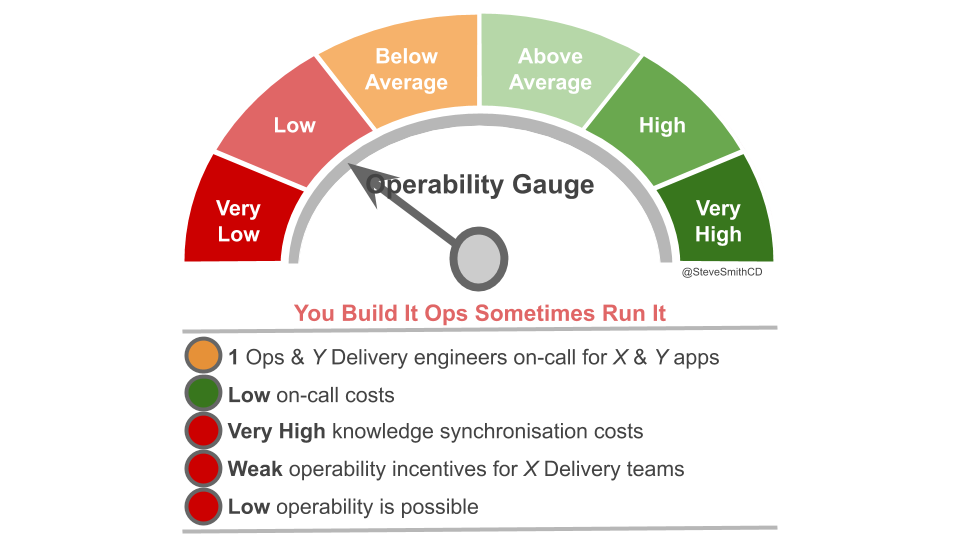
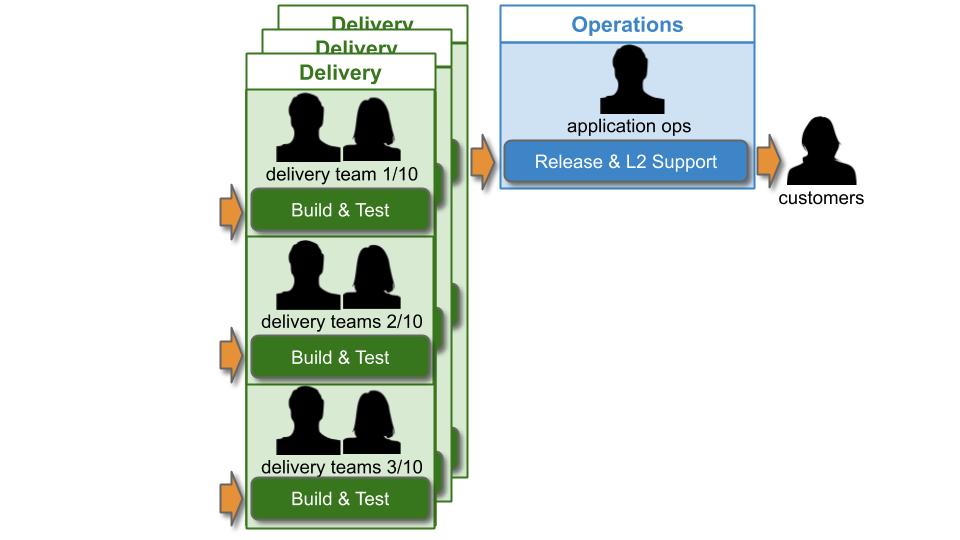
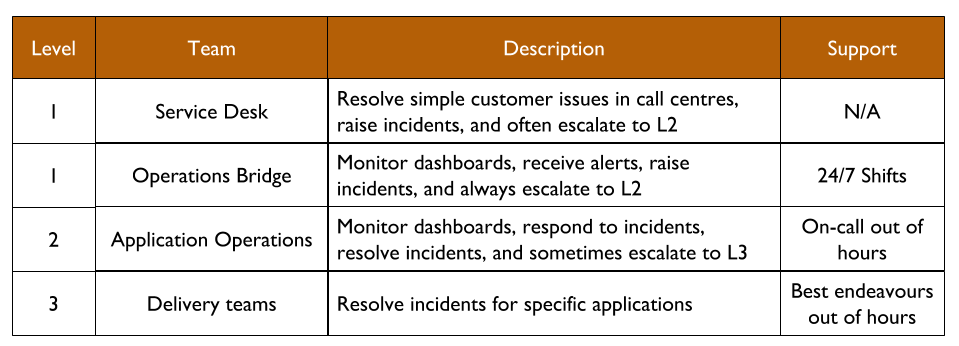
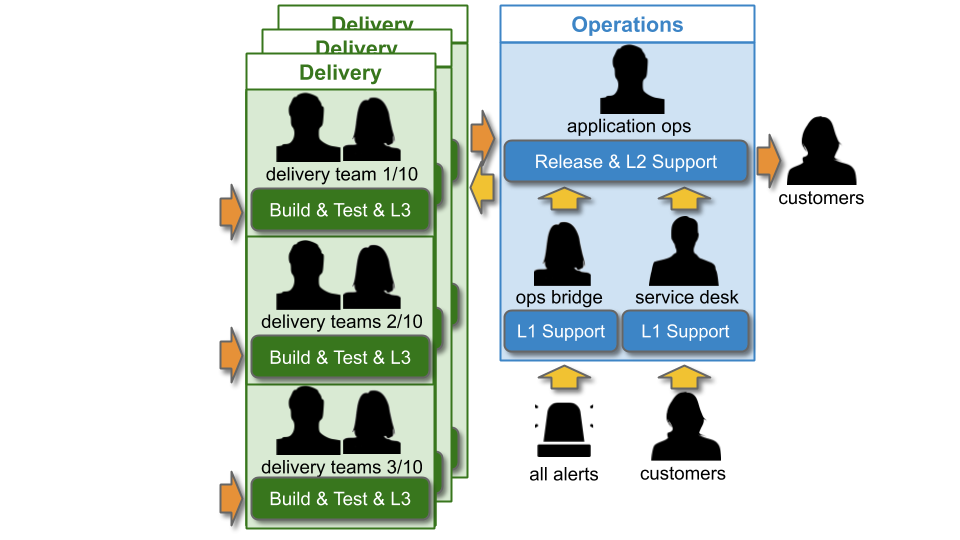
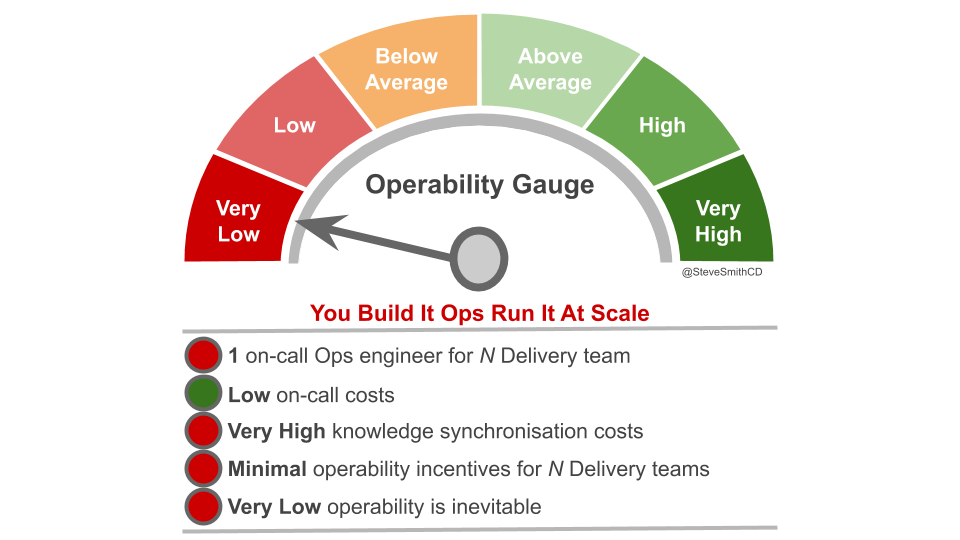
With a Theory Of Constraints lens, Discontinuous Delivery is caused by a constraint within the technology value stream. Time and money must be invested in technology and organisational changes from the Continuous Delivery canon, to find and remove that constraint. An example would be from You Build It Ops Run It, where a central operations team cannot keep up with deployment requests from a development team.
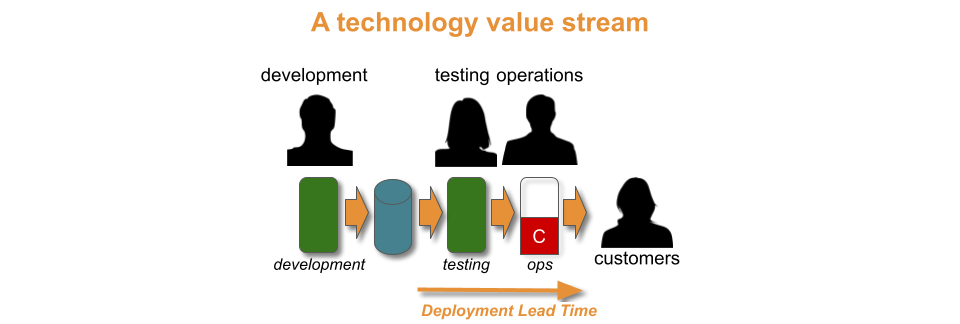
The optimal approach to implementing Continuous Delivery is the Improvement Kata. Improvement cycles are run to experiment with different changes. This continues until all constraints in the technology value stream are removed, and the flow of release candidates matches the required throughput level.
The overinvestment question can now be qualified as:
Is it possible to overinvest in Continuous Delivery, once constraints on deployment throughput are removed and customer demand is satisfied?
The answer depends on the amount of time and money to be invested, and where else that investment could be made in the organisation.
Investing without a deployment constraint
Indefinite investment in Continuous Delivery is possible. The deployment frequency and deployment lead time linked to a throughput level are its floor, not its ceiling. For example, a development team at its required throughput level of weekly deployments could push for a one hour deployment lead time.

Deployment lead time strongly correlates with technical quality. An ever-faster deployment lead time tightens up feedback loops, which means defects are found sooner, rework is reduced, and efficiency gains are accrued. The argument for a one hour deployment lead time is to ensure a developer receives feedback on their code commits within the same day, rather than the next working day with a one day deployment lead time.
Advocating for a one hour deployment lead time that exceeds the required throughput level is wrong, due to:
- Context. A one day deployment lead time might mean eight hours waiting for test feedback from an overnight build, before a 30 minute automated deployment to production. Alternatively, it might mean a 30 minute wait for automated tests to complete, before an eight hour manual deployment. A developer might receive actionable feedback on the same day.
- Cost. Incremental improvements are insufficient for a one hour deployment lead time. Additional funding is inevitably needed, as radical changes in build, testing, and operational activities are involved. In Lean Manufacturing, this is the difference between kaizen and kaikaku. It is the difference between four minutes refactoring a single test in an eight hour test suite, and four weeks parallelising all those tests into a 30 minute execution time.
- Culture. Radical changes necessary for a one hour deployment lead time can encounter strong resistance when customer demand is already satisfied, and there is no unmet business outcome. The lack of business urgency makes it easier for people to refuse changes, such as a change management team declining to switch from a pre-deployment CAB approval to a post-deployment automated audit trail.
- Constraints. A one hour deployment lead time exceeding the required throughput level is outside Discontinuous Delivery. There is no constraint to find and remove in the technology value stream. There is instead an upstream constraint in the fuzzy frontend. Time and money would be better invested in business development or product design, rather than Continuous Delivery. Removing the fuzzy frontend constraint could shorten the cycle time for product ideas, and uncover new revenue streams.
The correlation between deployment lead time and technical quality makes an indefinite investment in Continuous Delivery tempting, but overinvestment is a real possibility. Redirecting continuous improvement efforts at the fuzzy frontend after Continuous Delivery has been achieved is the key to unlocking more customer demand, raising the required throughput level, and creating a whole new justification for funding further Continuous Delivery efforts.
Example – Gardenz
Gardenz is a retailer. It has an ecommerce website that sells garden merchandise. It takes one week to deploy a new website version, and it happens once a month. The product manager estimates weekly deployments of new product features would increase customer sales.
The Gardenz website is in a state of Discontinuous Delivery, as the required throughput level is unmet. The developers previously needed five days to establish monthly deployments, so ten days is estimated for weekly.

The Gardenz constraint is manual regression testing. It causes so much rework between developers and testers that deployment lead time cannot be less than one week.
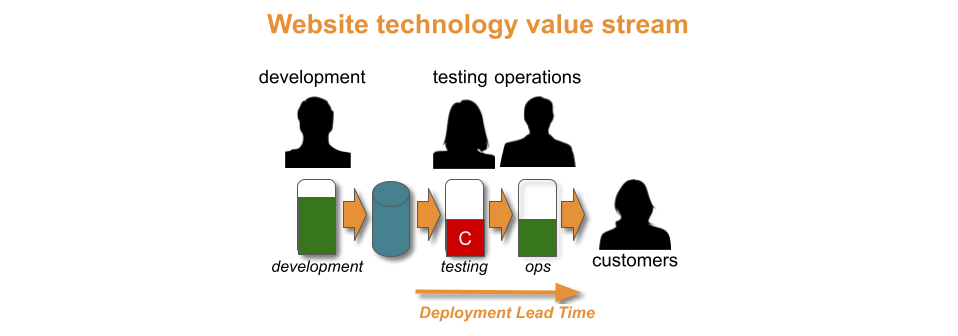
The Gardenz developers and testers run improvement cycles to merge into a single delivery team, and replace their manual regression tests with automated functional tests. After fourteen days of effort, a deployment lead time of one day is possible. This allows the website to be deployed once a week, in under a day.
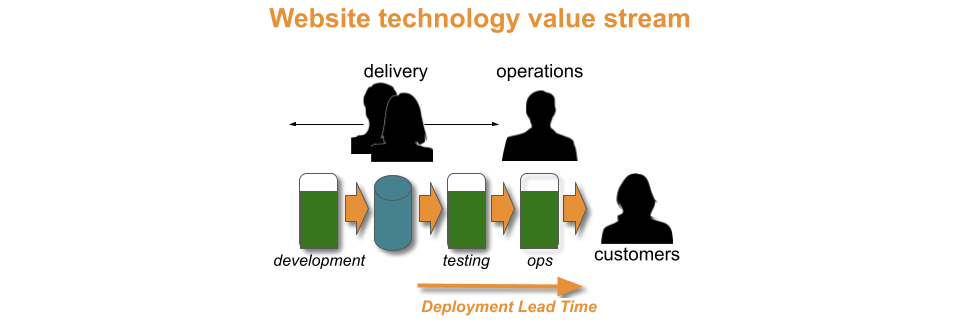
Gardenz has moved up a throughput level to weekly deployments, and the product manager is satisfied. Now they need to decide whether to invest further in daily deployments, beyond customer demand. As weekly deployments took 14 days, 28 days of time and money can be estimated for daily.
The removal of the testing constraint on weekly deployments causes a planning constraint to emerge for daily deployments. New feature ideas cannot move through product planning faster than two days, no matter whether the deployment lead time is one day, one hour, or one minute. The product manager decides to invest the available time and money into removing the planning constraint. Daily deployments are earmarked for future consideration.
Example – Puzzle Planet
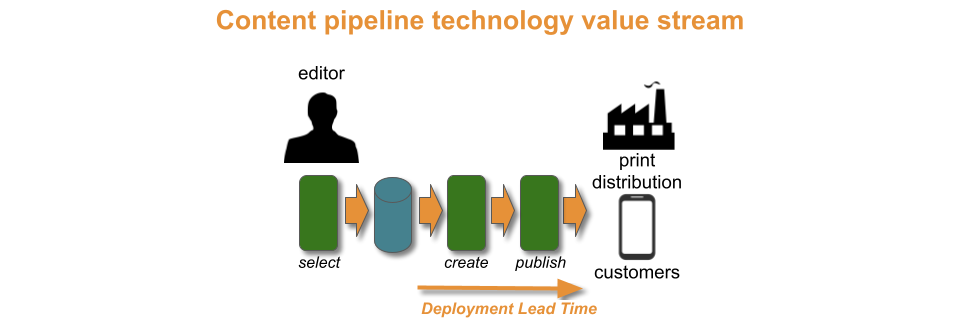
Puzzle Planet is a media publisher. Every month, it sells a range of puzzle print magazines to newsagent resellers. Its magazines come from a fully automated content pipeline. It takes one day for a magazine to be automatically created and published to print distributors.
The Puzzle Planet content pipeline is in a state of Continuous Delivery. The required throughput level of monthly magazines is met. It took two developers six months to reach a one week content lead time, and a further nine months to exceed the throughput level with a one day content lead time.

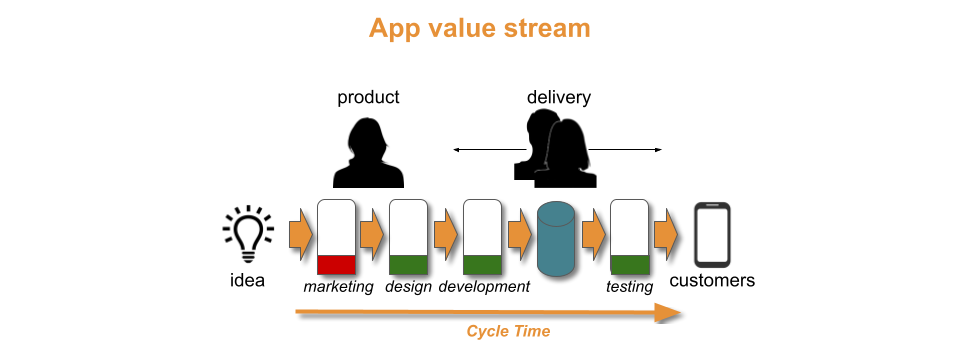
There is no constraint within the content pipeline. The content pipeline also serves a subscription-based Puzzle Planet app for mobile devices, in an attempt to enter the digital puzzle market. Subscribers receive new puzzles each day, and an updated app version every two months. Uptake of the app is limited, and customer demand is unclear.
Puzzle Planet has benefitted from exceeding its required throughput level with a one day content lead time. The content pipeline is highly efficient. It produces high quality puzzles with near-zero mistakes, and handles print distributors with no employee costs. It could theoretically scale up to hundreds of magazine titles. However, a one week content lead time would serve similar purposes.
The problem is the lack of customer demand for the Puzzle Planet app. Digital marketing is the constraint for Puzzle Planet, not its content pipeline or print magazines. An app with few customers and bi-monthly features will struggle in the marketplace, regardless of content updates.
As it stands, the nine months spent on a one day content lead time was an overinvestment in Continuous Delivery. The nine months of funding for the content pipeline could have been invested in digital marketing instead, to better understand customer engagement, retention, and digital revenue opportunities. If more paying customers can be found for the Puzzle Planet app, the one day content lead time could be turned around into a worthy investment.
Acknowledgements
Thanks to Adam Hansrod for his feedback.


Recent Comments