Why does optimising for robustness leave organisations in a state of Discontinuous Delivery, and vulnerable to failure? How does optimising for resilience improve reliability, and how can it encourage the adoption of Continuous Delivery?
The Resilience as a Continuous Delivery Enabler series:
- The cost and theatre of Optimising For Robustness
- When Optimising For Robustness fails
- The value of Optimising For Resilience
- Resilience as a Continuous Delivery enabler
TL;DR:
- Optimising For Robustness – prioritising MTBF over MTTR – is an antiquated, flawed approach to IT reliability that results in Discontinuous Delivery and an operational brittleness that begets failure
- If an organisation has previously optimised for robustness, a Continuous Delivery programme focussed on throughput is unlikely to succeed
- Optimising For Resilience – prioritising MTTR over MTBF – is a superior reliability strategy that enables an organisation to gracefully extend to limit the impact of failures, and position itself for sustained adaptability
- Resilience As A Continuous Delivery Enabler is a heuristic that advocates resilience as the focus of a Continuous Delivery programme
- Improving the resilience of services makes it easier to reduce Risk Management Theatre, and gradually adopt Continuous Delivery
The tradition of robustness
As software continues to eat the world, organisations must have reliable IT services at the heart of their business if they are to innovate in rapidly changing markets. Reliability is defined by Patrick O’Connor and Andre Kleyner in Practical Reliability Engineering as “the probability that [a system] will perform a required function without failure under stated conditions for a stated period of time“, or as a function of Mean Time Between Failures (MTBF) and Mean Time To Repair (MTTR).
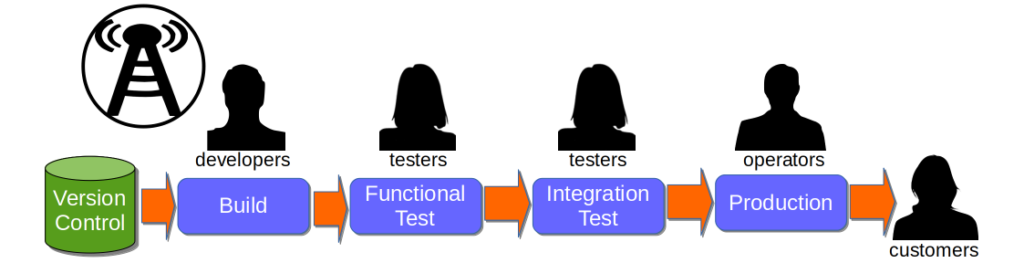
The traditional IT reliability strategy is Optimising For Robustness. This means prioritising a higher MTBF over a lower MTTR for IT services, by attempting to maintain a failure-free production environment. It is based on the belief that a production environment is a complicated system, in which services are homogeneous processes with predictable interactions in repeatable conditions. Failures are believed to be caused by isolated, faulty changes and are considered entirely preventable. When an organisation optimises for robustness, it will usually rely upon:
- End-To-End Testing to verify the functionality of a new service version against its unowned dependent services
- Change Advisory Boards to assess, prioritise, and approve the deployment of new service versions
- Change Freezes to restrict the deployment of new service versions for a period of time due to market conditions
These practices are inherently slow, and a form of Risk Management Theatre 1. End-To-End Testing incurs long execution times and significant maintenance time, and defects can still occur. Change Advisory Boards involve slow approval times, and deployments can still fail. Change Freezes cause huge productivity impediments, and failures can still happen. In addition, the long deployment lead times caused by robustness practices ensure a large batch of requirements and technology changes per release, which actually increases the risk of failure 2.
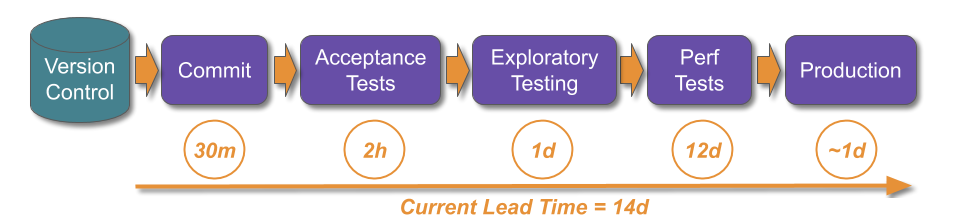
Optimising For Robustness constrains the stability and throughput of IT delivery such that business demand cannot be satisfied. It is the predominant reason why so many organisations are trapped in a state of Discontinuous Delivery.
The constancy of failure
Ironically, Optimising For Robustness leaves an organisation ill-equipped to deal with failure. In Resilience and Precarious Success, Mary Patterson and Robert Wears describe how “fundamental goals (such as safety) tend to be sacrificed with increasing pressure to achieve acute goals (faster, better, and cheaper)“. When an organisation optimises for robustness it will under-invest in its production environment, resulting in unimplemented “non-functional” requirements, inadequate telemetry 3, snowflake infrastructure, and a fragile service architecture. This will be considered acceptable, as failures are expected to be rare.
However, it is naive to think of a production environment of running services as a complicated system. A production environment is an intractable mass of heterogeneous processes, with unpredictable interactions occurring in unrepeatable conditions. It is a complex system of emergent behaviours, in which the cause and effect of an event can only be perceived in retrospect. Furthermore, as Richard Cook explains in How Complex Systems Fail “the complexity of these systems makes it impossible for them to run without multiple flaws“. A production environment is perpetually in a state of near-failure.
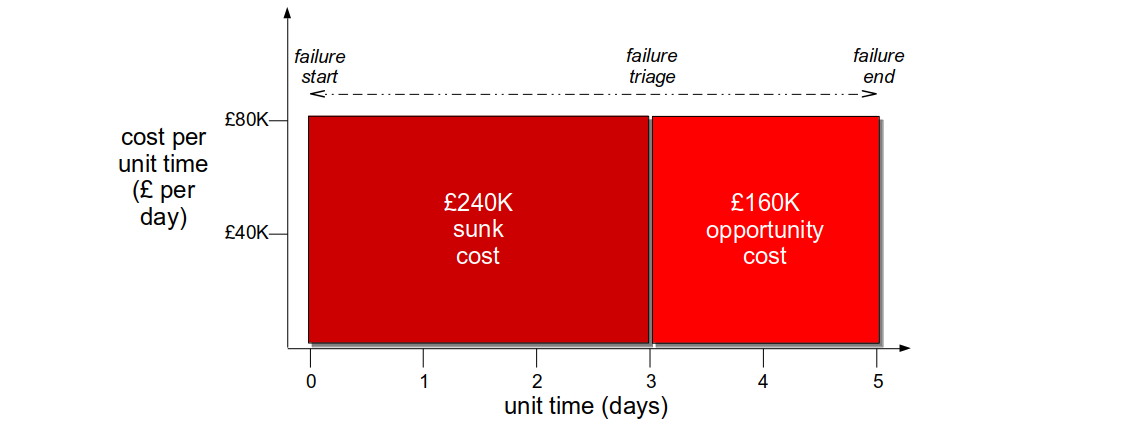
A failure occurs when multiple faults unexpectedly coalesce such that one or more business operations cannot succeed. It will create a revenue cost expressed as a function of cost per unit time and duration, and in an organisation optimised for robustness the impact can be considerable. The sunk cost incurred until failure detection can be high, as unimplemented “non-functional” requirements and inadequate telemetry will restrict situational awareness. The opportunity cost until failure resolution can also be high, as snowflake infrastructure and a fragile architecture will increase failure blast radius. In addition, the loss of customer confidence and increased failure demand will create further opportunity costs.
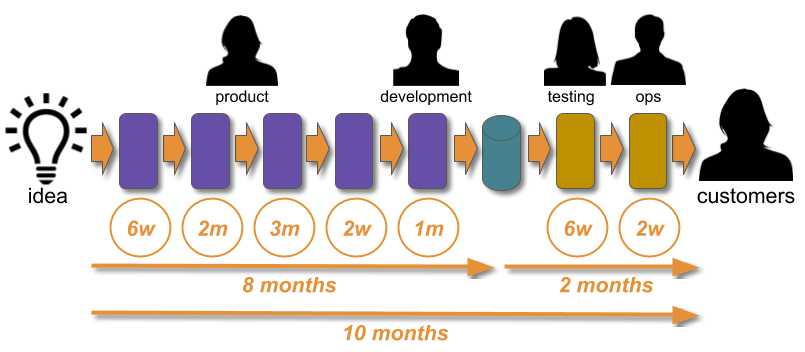
Consider a Fruits-U-Like website optimised for robustness. Its third party registration service begins to suffer under load, and new customers are rejected on checkout. The failure has a static cost per day of £80k, but with no telemetry the failure is not detected for 3 days. The checkout team then produces a hotfix within a day, and it is deployed the following day. The revenue cost is £400K, with a £240K sunk cost and a £160K opportunity cost.
Optimising For Robustness encourages an attitude Sidney Dekker calls the Bad Apple Theory, in which a system is considered absolutely reliable except for the actions of unreliable employees. When a failure occurs, the combination of the Bad Apple Theory and hindsight bias will produce an oppressive culture of naming, blaming, and shaming the individuals involved. This discourages knowledge sharing and collaboration.
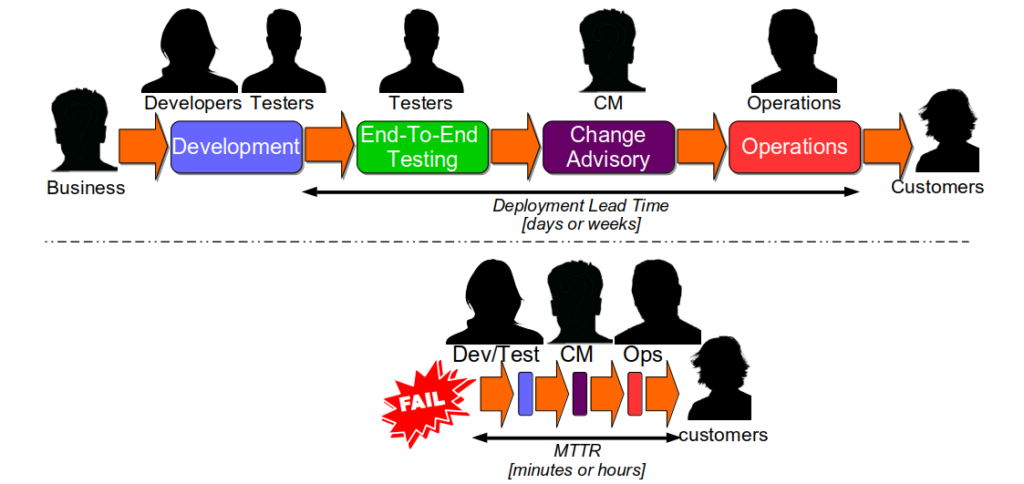
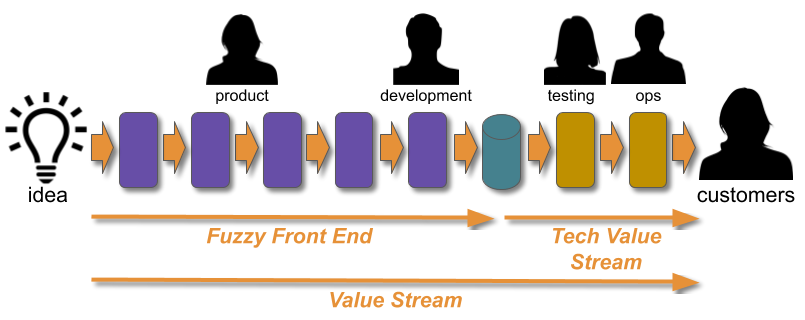
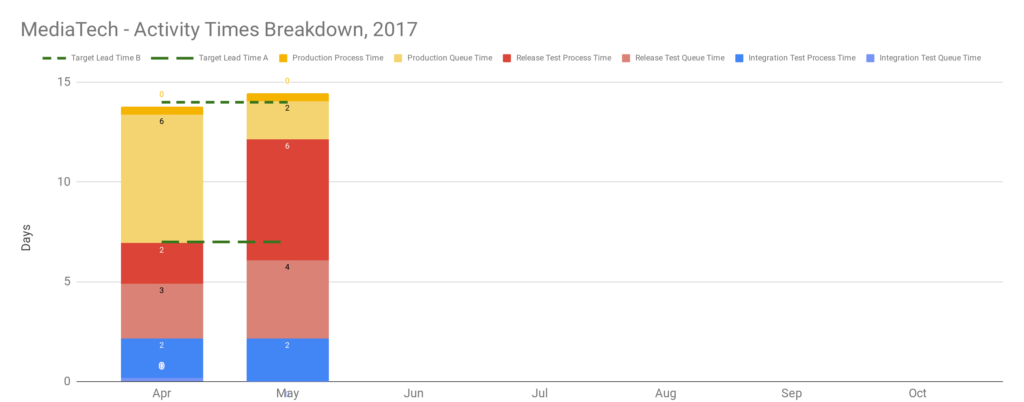
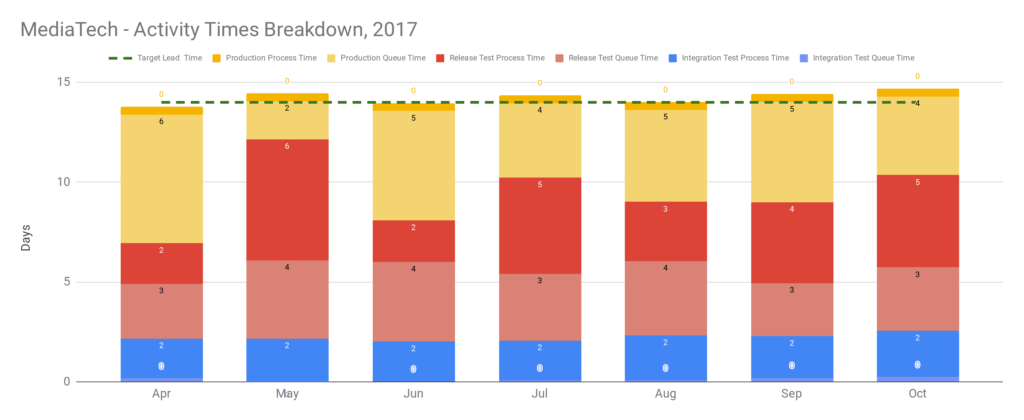
An interesting consequence of Optimising For Robustness is Dual Value Streams. An organisation optimised for robustness will have feature value streams with deployment lead times of weeks or months. When a failure is detected its sunk cost will create urgency, and people will want to immediately minimise the opportunity cost duration. That will lead to robustness practices being sacrificed for speed, in a truncated fix value stream with an MTTR of hours or days 4. The robustness practices omitted from the fix value stream should be considered theatre until proven otherwise.
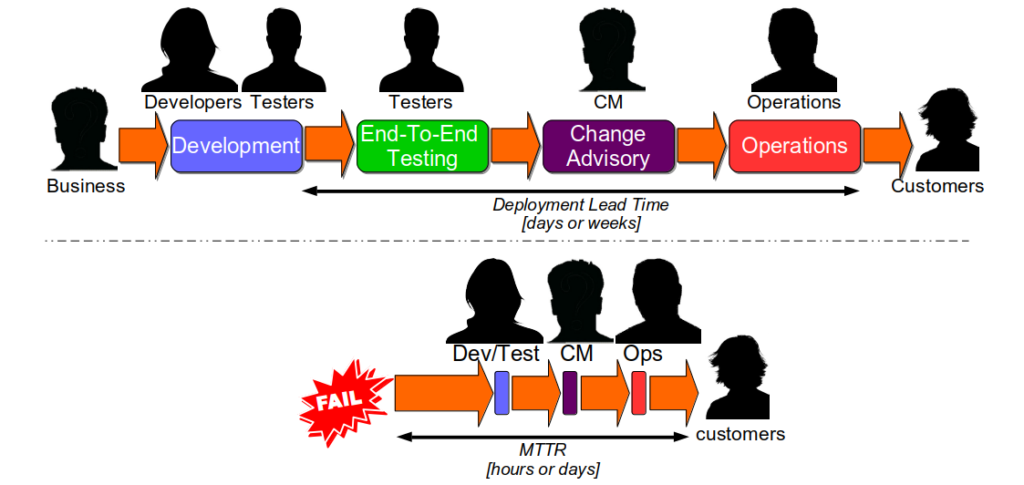
Continuous Delivery improves the stability and throughput of IT delivery, but it is hard. A Continuous Delivery programme in an organisation optimised for robustness will not succeed if it is focussed solely on throughput. The most significant accelerator of deployment lead time will likely be the removal of robustness risk management theatre, but practices like End-To-End Testing will be woven into the fabric of the organisation 5. If they are forcibly removed, Continuous Delivery will be blamed for the first subsequent production failure. Resisters will lobby for more robustness practices, and a return to the status quo is all but inevitable. Unfortunately, it only takes one inopportune failure for a Continuous Delivery programme to be cancelled.
The value of resilience
A far more effective reliability strategy is Optimising For Resilience. This means prioritising a lower MTTR over a higher MTBF for IT services, by rapidly responding to failures in a production environment. Some classes of failure should never occur, some failures are more costly than others, and some safety-critical systems should never fail, but in general organisations should adhere to John Allspaw’s advice that “being able to recover quickly from failure is more important than having failures less often“.
Resilience can be thought of as graceful extensibility. In Four Concepts for Resilience and their Implications for Systems Safety in the Face of Complexity, David Woods describes graceful extensibility as “the ability of a system to extend its capacity to adapt when surprise events challenge its boundaries“. The graceful extensibility of a system is derived from its adaptive capacity, which represents the capacity for adaptation when a failure occurs.
Erik Hollnagel et al break down resilience in Resilience Engineering In Practice using a conceptual model known as the Four Cornerstones of Resilience:
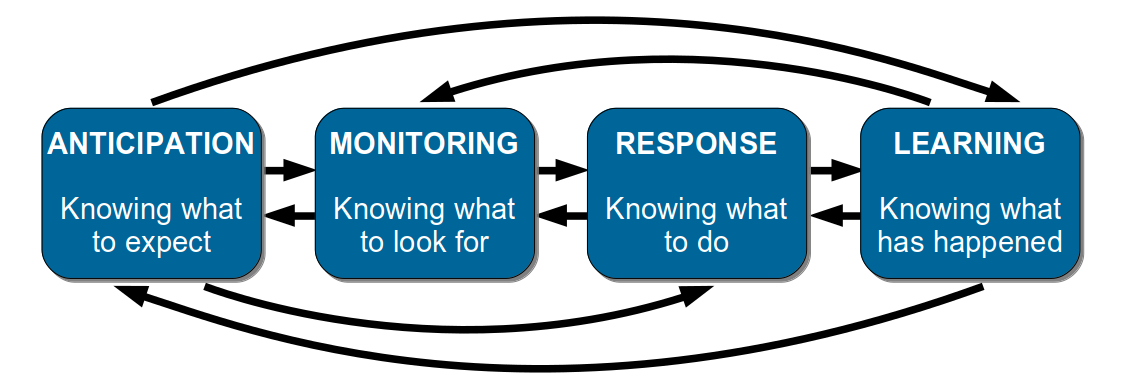
The cornerstones are non-linear, complementary aspects of resilience:
- Anticipation is imagining the potential for future failures, and countering those scenarios in advance
- Monitoring is inspecting operating conditions, and alerting when anomalies occur
- Response is using guidelines, heuristics, improvisation, and situational awareness to mitigate a failure
- Learning is understanding the circumstances of a near-miss or failure, and sharing the observations
Optimising For Resilience means creating a production environment in which running IT services can gracefully extend to deal with the unpredictable behaviours, unexpected changes, and periods of failure that will inevitably occur. When a service has sufficient adaptive capacity the cost per unit time and duration of production failures can potentially be minimised, reducing the direct revenue costs and indirect opportunity costs caused by a failure.
A lower MTTR can be achieved by investing in the operability of IT services. Operability is defined as “the ability to keep a system in a safe and reliable functioning condition“, and is associated with a set of practices:
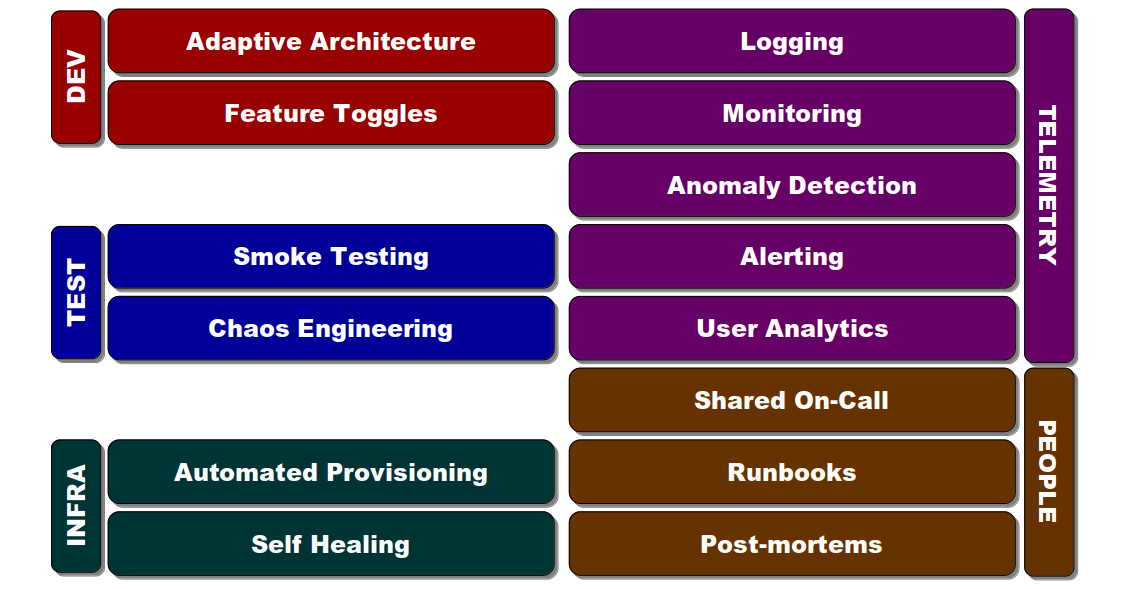
Each of these will increase the capacity of a service to adapt to unexpected operating conditions, and produce a more effective incident response:
- Development: an Adaptive Architecture limits the blast radius of a failure, and Feature Toggles allow features to be limited, tested in isolation, or turned off on failure
- Testing: Smoke Testing verifies service health, and Chaos Engineering uncovers latent failures in production
- Infrastructure: Automated Provisioning creates reproducible environments, and Self-Healing automatically restores failed service instances
- Telemetry: Logging radiates data on traffic, errors, latency, and saturation, and Monitoring visualises service metrics and events in a time series. Anomaly detection identifies events that breach normal operating conditions and Alerting notifies operators of abnormalities to act on. User analytics show success rates for user journeys
- People: Shared On-Call fosters a “You Build It, You Run It” culture and increases situational awareness, and Runbooks are a repository for operational knowledge. Blameless Post-Mortems uncover the multiple contributors to a near-miss or failure and suggest future preventative measures, while respecting the best efforts of individuals and the dangers of hindsight bias 1
If Fruits-U-Like was optimised for resilience its checkout team could receive an alert within 5 minutes of third party registration errors. A Circuit Breaker would allow some registrations to succeed, and a Bulkhead could trigger an anonymous checkout for failed registrations. This could decrease the cost per day to £5K, and a hotfix could be deployed within 3 hours. The revenue cost would be £625, with a £18 sunk cost and a £607 opportunity cost.
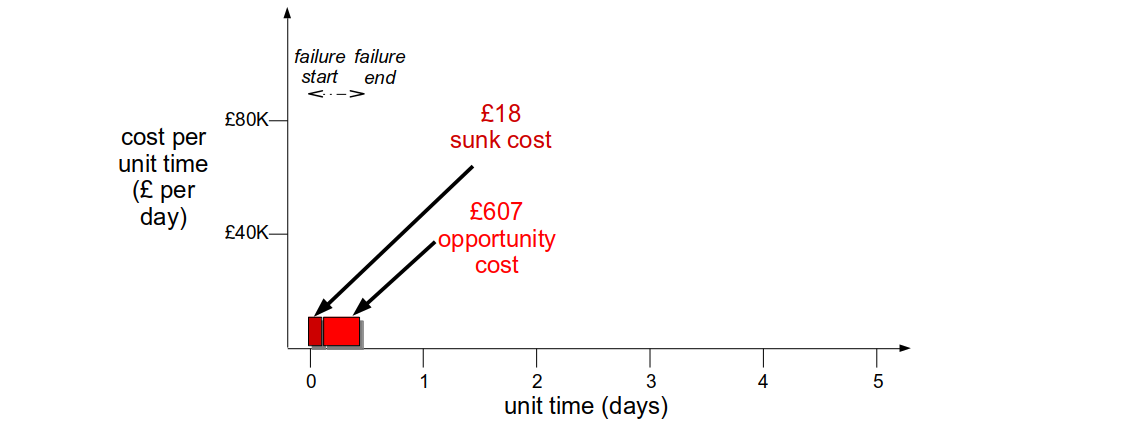
Optimising For Resilience sets the foundation for an organisation to act on market disruption and innovate. Once an organisation has the required level of graceful extensibility, it can continue to invest in its people and technology to achieve sustained adaptability. Sustained adaptability has been described by David Woods as “the ability to adapt to future surprises as conditions continue to evolve“, and can be thought of as innovation capability. An organisation that can quickly adapt to unexpected business events will hold a powerful First Mover Advantage over its competitors.
Resilience as a Continuous Delivery enabler
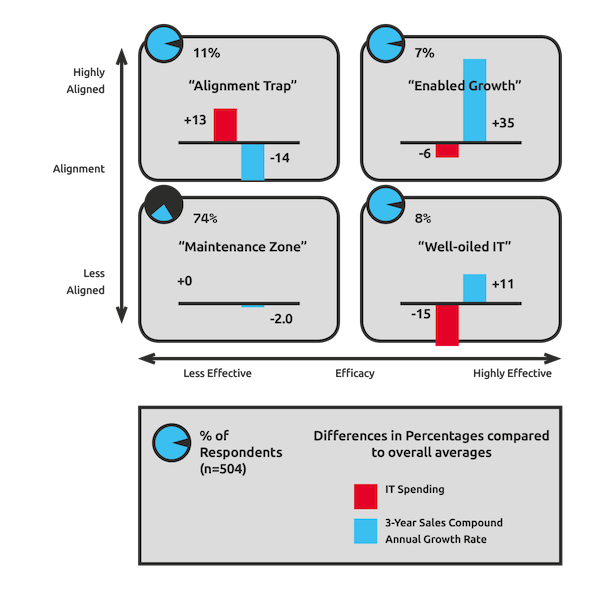
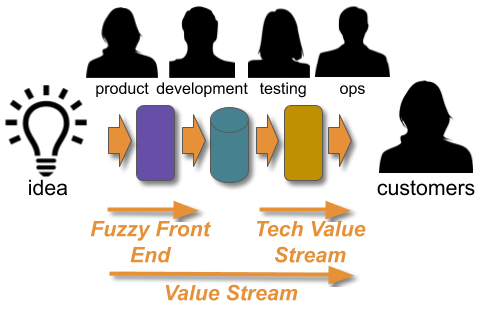
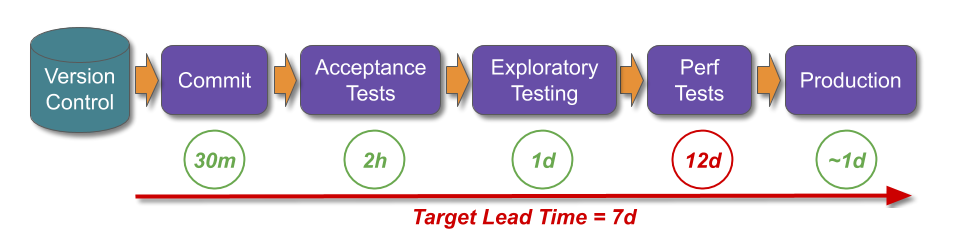
There is no recipe for success with Continuous Delivery, as every organisation is a complex, adaptive system with its own circumstances and constraints. However, if an organisation has previously optimised for robustness and is in a state of Discontinuous Delivery there is a heuristic that can be used:
Resilience as a Continuous Delivery enabler
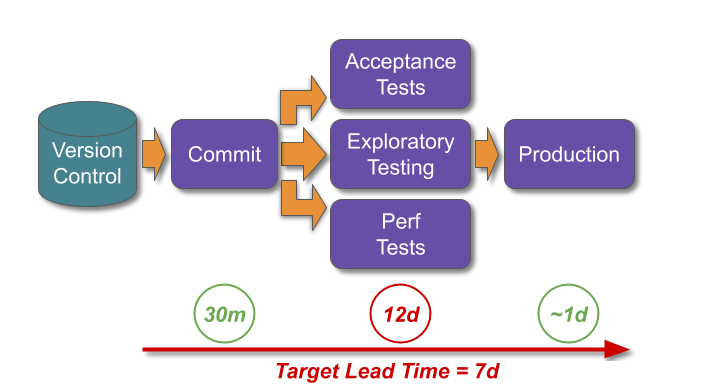
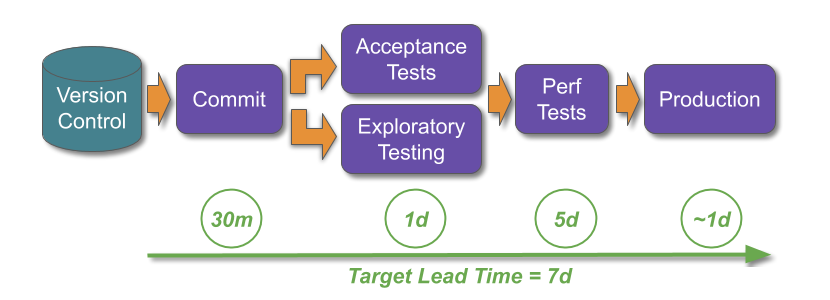
This can be applied to bootstrapping Continuous Delivery:
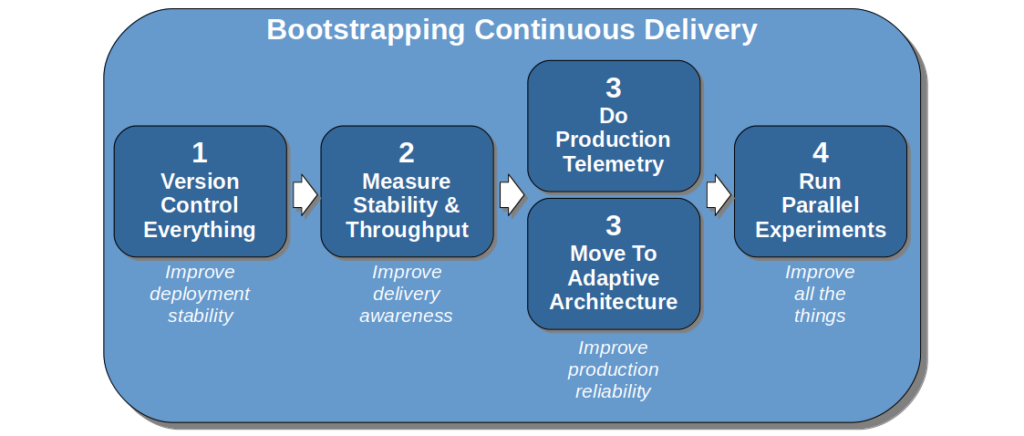
This bootstrap sequence can guide the formative steps of a Continuous Delivery programme, and build confidence throughout an organisation. It demonstrates a commitment to stability, transparency, and reliability which will help to win over resisters. Storing all code, configuration, infrastructure definitions, documents, scripts etc. in version control eliminates the predominant source of failure demand. Creating stability and throughput indicators helps people to understand their delivery capabilities, and make better decisions 7.
Improving production reliability minimises the cost of failure, and lays the groundwork for challenging robustness risk management theatre later on. Automated anomaly detection and alerting will speed up the detection time of an anticipated failure, reducing its sunk cost duration to seconds or minutes. An adaptive architecture will limit the blast radius of a failure, decreasing both cost per unit time and duration.
Implementing production telemetry early on also provides insurance for unsafe-to-fail situations. Logging, monitoring, and analytics dashboards can identify the contributing technical faults to a failure, and when they first entered production. If resisters blame Continuous Delivery for a failure, the data will pinpoint which faults were recent and which were lying dormant in production beforehand.
Once the Continuous Delivery programme reaches the experimentation phase, other sources of adaptive capacity can be created with operability practices such as Capacity Planning, Self-Healing, Shared On-Call, and Blameless Post-Mortems. At the same time, the programme should widen its focus to include deployment throughput as well as deployment stability and production resilience.
The end of theatre
The key to removing robustness risk management theatre is to visualise its costs to stakeholders and offer a practical alternative, rather than rely on theoretical arguments about wait times or defect discovery rates. Using the Resilience As A Continuous Delivery Enabler heuristic ensures a Continuous Delivery programme can supply those visualisations, and outline an alternative approach from the outset.
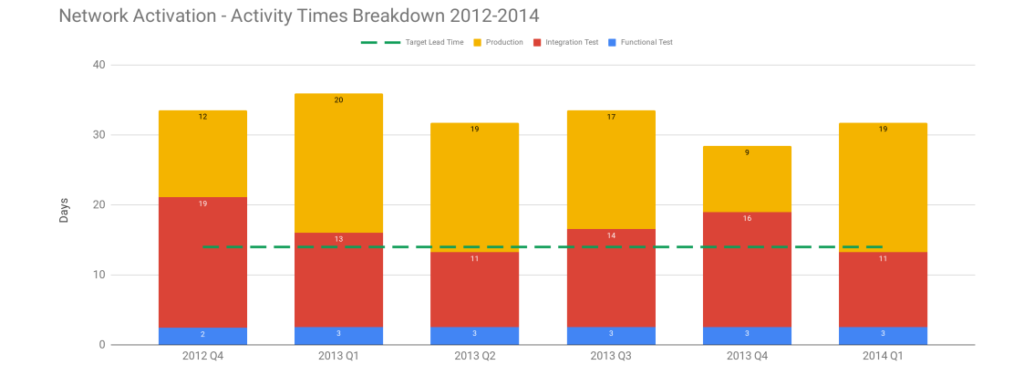
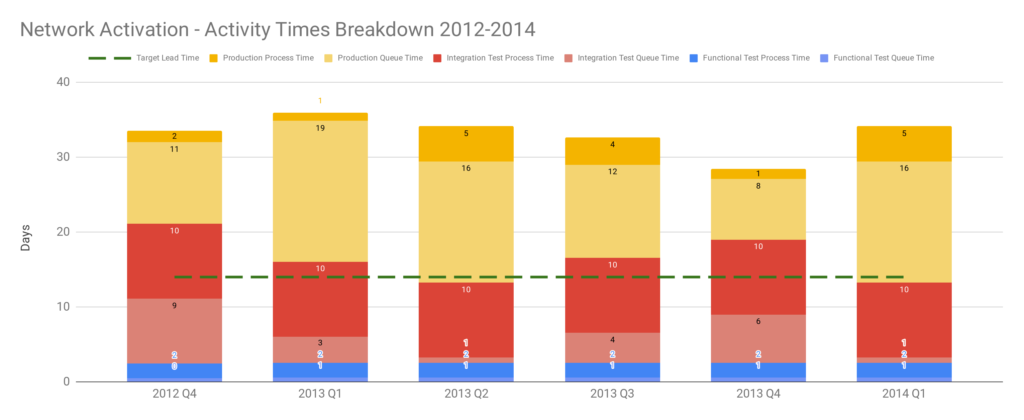
Stakeholders should be made aware of their robustness risk management theatre with a showcase of the delivery awareness and production reliability improvements so far. The stability and throughput indicators will illustrate the historical cost of robustness practices, by visualising the disparity between deployment lead times and MTTR in the Dual Value Streams. Some carefully calibrated Chaos Engineering in a test environment 8 will demonstrate how MTTR has been shrunk to minutes or hours, by showing how failures can be managed with the new production telemetry and adaptive architecture. An MTTR an order of magnitude faster than deployment lead times will show stakeholders what a team can accomplish with minimal robustness practices.
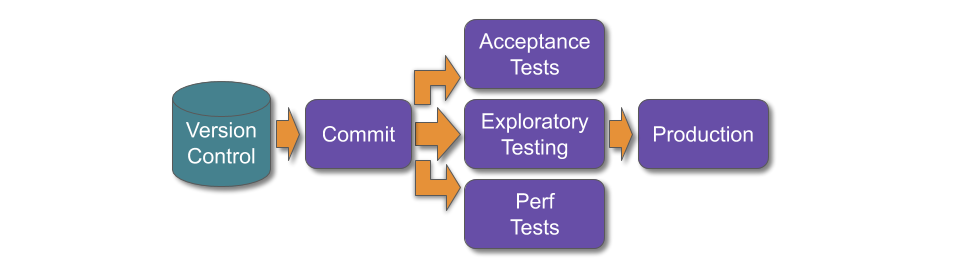
Each robustness practice subsequently agreed to be risk management theatre should be incrementally replaced with the appropriate mix of Continuous Delivery and operability practices. End-To-End Testing should be superseded by a multi-faceted testing portfolio, in order to turn the resident testing strategy from a Test Ice Cream Cone into a Test Pyramid. This will reduce test execution times and maintenance costs, while simultaneously improving defect discovery rates:
| Practice |
Quantity |
Frequency |
Duration |
Environment |
| Unit Testing |
100 to 1000+ |
Per build |
< 30s total |
Local and Build |
| Acceptance Testing |
10 to 100+ |
Per build |
< 10m total |
Local and Build |
| Exploratory Testing |
10 to 100+ |
Per build |
Timebox |
Local and 3rd Party |
| Contract Testing |
~20 |
Per 3rd party deploy |
< 1m |
3rd Party |
| Smoke Testing |
~5 |
Per deploy |
< 5m |
All |
| Monitoring |
10 to 100+ |
Always |
< 10s |
All |
| Anomaly detection |
10 to 100+ |
< 1m |
< 10s |
All |
| Adaptive architecture |
N/A |
Always |
N/A |
All |
Change Advisory Boards and Change Freezes should end in favour of incremental deployments and incremental launches. Blue Green Deployments and Canary Deployments gradually direct users to a newly deployed service version, and users can be redirected to the old version on service failure. Dark Launching controls feature rollouts based on user demographics, and services can be operated in a degraded state on feature failure. Lightweight change management conversations should be reserved for unavoidably large releases, or turbulent market conditions.
Summary
Optimising For Robustness is an antiquated, flawed approach to IT reliability that results in long-term Discontinuous Delivery and an operational brittleness that begets failure. As John Allspaw has stated, reliability is “the presence of adaptive capacity, not the absence of failures“. Robustness is of value, but it must be rejected as an outcome if an organisation wants to innovate in changing markets.
Optimising For Resilience is a superior reliability strategy that enables an organisation to gracefully extend to limit the impact of failures, and position itself for sustained adaptability. It is a paradigm shift, in which people need to accept the inherent complexity within their IT services and the hard truth that failures are inevitable. This is neatly summarised by David Woods’ assertion that “graceful extensibility trades off with robust optimality“. An organisation optimised for robustness will reject sources of adaptive capacity such as Circuit Breakers as inefficiencies, but to an organisation optimised for resilience its graceful extensibility is more important than cost efficiencies.
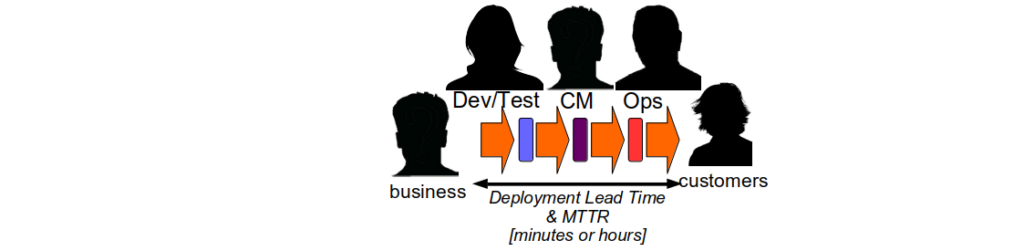
If an organisation has optimised for robustness a Continuous Delivery programme focussed on throughput alone is unlikely to succeed. Resilience As A Continuous Delivery Enabler is a heuristic that advocates resilience as the focus of Continuous Delivery, and using it to bootstrap a Continuous Delivery programme improves production reliability from the outset. Improving the resilience of services by an order of magnitude makes it easier to offer a series of practical alternatives to robustness risk management theatre, and reduce deployment throughput until there is a single value stream that can satisfy business demand 9.
1 Other robustness practices include manual regression testing, segregation of duties, artificial deployment limits, and uptime incentives
2 The Principles of Product Development Flow by Don Reinertsen describes in detail how large batch sizes increase risk
3 The DevOps Handbook by Patrick Debois et al defines telemetry as a logical grouping of logging, monitoring, anomaly detection, alerting, and user analytics
4 In ITIL these are termed Normal and Emergency Changes
5 The Anxiety Of Learning by Edgar Schein describes how people resist change due to learning and survival anxieties
6 How Complex Systems Fail by Richard Cook explains why hindsight bias is such an obstacle to understanding failures, and why root causes do not exist
7 Measuring Continuous Delivery by the author details how to measure the stability and throughput of IT delivery
8 Chaos Engineering should be restricted to test environments in an unsafe-to-fail culture
9 In ITIL these are termed Standard Changes
Acknowledgements
This series is indebted to John Allspaw and Dave Snowden for their respective work on Resilience Engineering and Cynefin.
Thanks to Beccy Stafford, Charles Kubicek, Chris O’Dell, Edd Grant, Daniel Mitchell, Martin Jackson, and Thierry de Pauw for their feedback on this series.

Recent Comments