Projects kill flow and teams. Focus on products, not projects
Since the Dawn of Computer Time, enormous sums of money and embarrassing amounts of time have been squandered upon software projects that have delivered little or no return on investment, with projects floundering between segregated Business and IT divisions squabbling over overestimated value-add and underestimated delivery dates. Given Grant Rule’s assertion that “studies too numerous to mention show that software projects are challenged or fail“, why are software projects so prone to failure and why do they persist?
To answer these questions, we must understand what constitutes a software project and why its delivery model is incongruent with product development. If we start with the PRINCE 2 project definition of “a temporary organization that is needed to produce a unique and predefined outcome or result at a pre-specified time using predetermined resources“, we can offer a concise definition as follows:
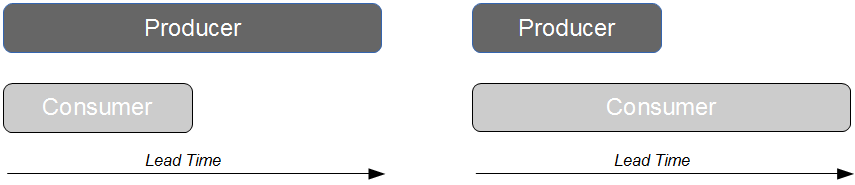
A project is a fixed amount of time and money assigned to deliver value-add
The key characteristic of a software project appears to be its fixed end date, which as a delivery model has been repeatedly debunked by IT practitioners such as Allan Kelly denouncing “endless, pointless discussions about when it will be done… successful software doesn’t have a pre-specified end date” and Marc Lankhorst arguing that “over 80% of IT spending in large organisations is on maintenance“. However, the fixed end date of a software project is invariably a consequence of its requirement for a collection of value-adding features to be simultaneously delivered, suggesting an augmented definition of:
A project is a fixed amount of time and money assigned to deliver a large batch of value-add
Once we view software projects as large batches of value-add, we can apply The Principles Of Product Development Flow by Don Reinertsen and better understand why so many projects fail:
- Increased cycle time – a project might not be deliverable on a particular date unless either demand is throttled or capacity is increased, e.g. artifically reduce user demand or increase staffing levels
- Increased variability – a project might be delayed due to unpredictable blockages in the value stream, e.g. testing of features B and C blocked while testing of feature A takes longer than expected
- Increased feedback delays – a project might incur significant costs due to slow feedback on bad design decisions and/or defects increasing rework, e.g. failures in feature C not detected until features A and B have passed testing
- Increased risk – a project might have an increased probability and cost of failure due to increased requirements/technology change, increased variation, and increased feedback delays
- Increased overheads – a project might endure development inefficiencies due to increased requirements/technology change, e.g. feature C development time increased by need to understand complexity of features A and B
- Increased inefficiencies – a project might encounter increased transaction costs due to increased requirements/technology change e.g. feature A slow to release as features B and C also required for release
- Increased irresponsibility – a project might suffer from diluted responsibilities, e.g. staff member has responsibility for delivery of feature A but is unincentivised to participate in delivery of features B or C
Don also provides a compelling explanation as to why the project delivery model remains prevalent, by explaining how large batches can become institutionalised as they “appear to have scale economies that increase efficiency [and] appear to reduce variability“. Software projects might indeed appear to be efficient due to perceived value stream inefficiencies and the counter-intuitiveness of batch size reduction, but from a product development standpoint it is an inefficient, ineffective delivery model that impedes value, quality, and flow.
There is a compelling alternative to the project delivery model – product development flow, in which we apply economic theory to Lean product development practices in order to flow product designs through our organisation. Product development flow emphasises the benefits of batch size reduction and encourages a one piece continuous flow delivery model, in order to reduce costs and improve return on investment.
Discarding the project delivery model in favour of product development flow requires an entirely different mindset, as epitomised by Grant urging us to “accommodate the ideas of flow production and lean systems thinking” and Allan affirming that “BAU isn’t a dirty word… enhancing products is Business As Usual, we should be proud of that“. On that basis the No Projects movement was conceived by Joshua Arnold to promote the valuation of products over projects, and anointed as:
Projects kill flow and teams. Focus on products, not projects
Recent Comments